In diesem Dokument wird beschrieben, wie Cloud Logging Logeinträge weiterleitet, die von Google Cloudempfangen werden. Es gibt verschiedene Arten von Routingzielen. Sie können Logeinträge beispielsweise an ein Ziel wie ein Log-Bucket weiterleiten, in dem Logeinträge gespeichert werden. Wenn Sie Ihre Logdaten an ein Drittanbieterziel exportieren möchten, können Sie Logeinträge an Pub/Sub weiterleiten. Außerdem kann ein Logeintrag an mehrere Ziele weitergeleitet werden.
Auf übergeordneter Ebene leitet Cloud Logging Logeinträge so weiter und speichert diese so:
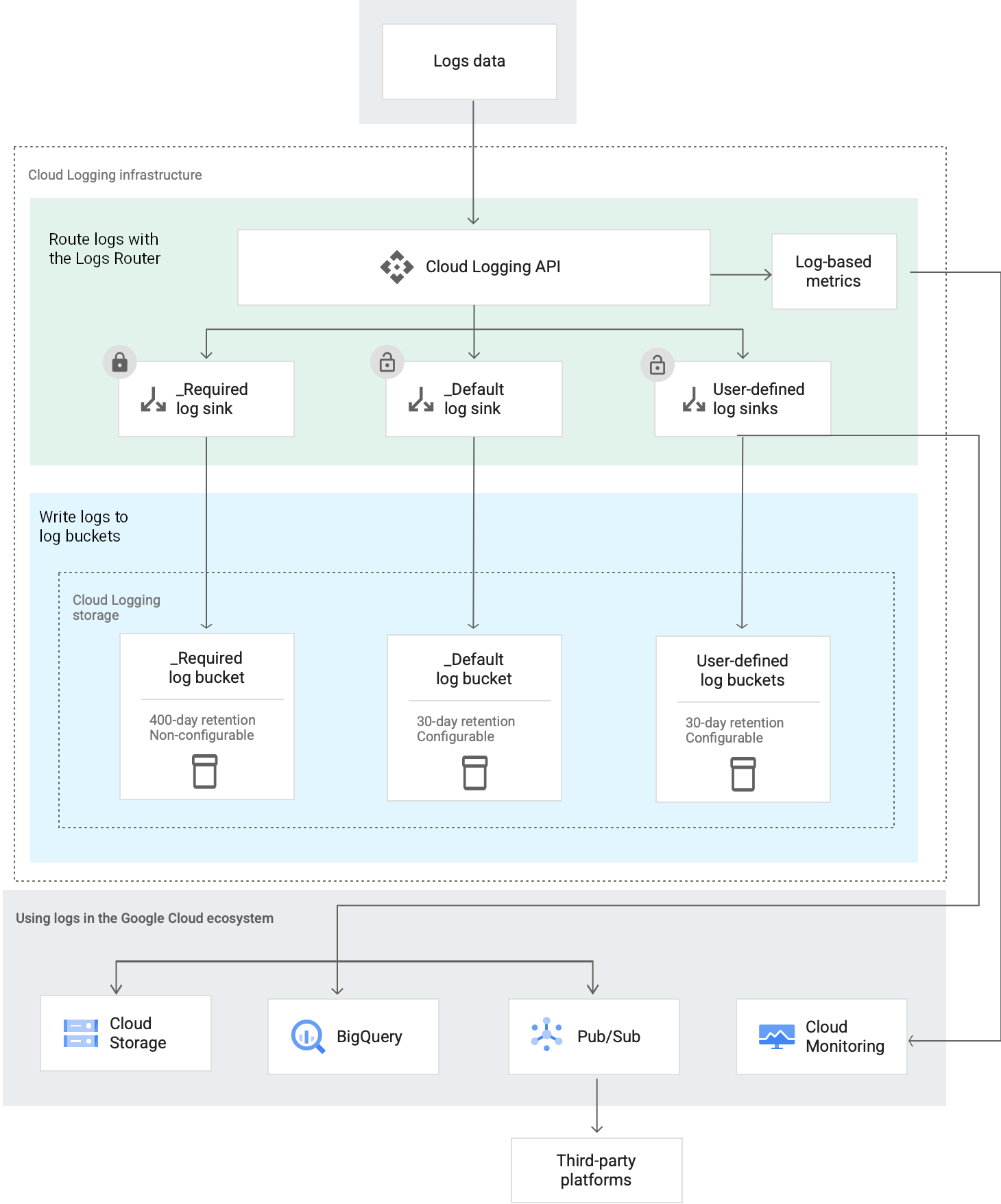
Log-Router
Jedes Google Cloud Projekt, Rechnungskonto, jeder Ordner und jede Organisation hat einen Log-Router, der den Fluss von Logeinträgen durch Senken auf Ressourcenebene verwaltet. Ein Log-Router verwaltet auch den Fluss eines Logeintrags durch Senken, die sich in der Ressourcenhierarchie des Eintrags befinden. Senken steuern, wie Logeinträge an Ziele weitergeleitet werden.
Ein Log-Router speichert einen Logeintrag temporär. Dieses Verhalten schützt vor vorübergehenden Unterbrechungen und Ausfällen, die auftreten können, wenn ein Logeintrag durch Senken fließt. Temporärer Speicher schützt nicht vor Konfigurationsfehlern.
Der temporäre Speicher eines Log-Routers unterscheidet sich vom Langzeitspeicher, der von Logging-Buckets bereitgestellt wird.
Eingehende Logeinträge mit Zeitstempeln, die mehr als die Aufbewahrungsdauer für Logs in der Vergangenheit liegen oder die mehr als 24 Stunden in der Zukunft liegen, werden verworfen.
Logsenken
Wenn eine Logs-Senke einen Logeintrag empfängt, wird entschieden, ob der Logeintrag ignoriert oder weitergeleitet werden soll. Diese Entscheidung wird getroffen, indem der Logeintrag mit den Filtern in der Logsenke verglichen wird. Wenn der Logeintrag weitergeleitet wird, sendet die Logsenke ihn an das von ihr angegebene Ziel. Das Ziel kann ein Projekt, ein Speicherort oder ein Dienst sein.
Logsinks gehören zu einer bestimmten Google Cloud Ressource Google Cloud :Projekte, Rechnungskonten, Ordner und Organisationen. Diese Ressourcen enthalten auch mehrere Logsinks. Wenn eine Ressource einen Logeintrag empfängt, wird dieser von jeder Logsenke in der Ressource unabhängig ausgewertet. Daher können mehrere Logsinks denselben Logeintrag weiterleiten.
Standardmäßig werden Logdaten in dem Projekt gespeichert, aus dem die Daten stammen. Es gibt jedoch mehrere Gründe, warum Sie diese Konfiguration ändern möchten:
- Sie möchten die Speicherung Ihrer Logdaten zentralisieren.
- Logdaten mit anderen Geschäftsdaten zusammenführen
- Zum Organisieren Ihrer Logdaten in einer für Sie nützlichen Weise.
- Sie können Ihre Logs an andere Anwendungen, Repositories oder Dritte senden. Sie möchten Ihre Logs beispielsweise aus Google Cloud exportieren, damit Sie sie auf einer Drittanbieterplattform ansehen können. Wenn Sie Ihre Logeinträge exportieren möchten, erstellen Sie eine Logsenke, die Ihre Logeinträge an Pub/Sub weiterleitet.
Bei einer falsch konfigurierten Logsenke werden Logeinträge nicht weitergeleitet. Wenn eine Senke falsch konfiguriert ist, werden Logeinträge geschrieben, in denen die Details des Fehlers angegeben sind. Außerdem wird eine E‑Mail an die wichtigen Kontakte für die Ressource gesendet. Weitere Informationen finden Sie unter Fehlerbehebung: Fehler ansehen.
Mit Logsenken können Logeinträge nicht rückwirkend weitergeleitet werden. Eine Logsenke kann also keinen Logeintrag weiterleiten, der vor der Erstellung der Senke empfangen wurde. Wenn eine Senke falsch konfiguriert ist, werden nur Logeinträge weitergeleitet, die nach der Behebung des Konfigurationsfehlers eingehen. Sie können Logdaten jedoch nachträglich aus einem Log-Bucket in Cloud Storage kopieren. Weitere Informationen finden Sie unter Logs kopieren.
Unterstützung für Organisationen und Ordner
Um die Protokolldaten in einer Organisation oder einem Ordner zu verwalten, haben Sie folgende Möglichkeiten:
Sie können aggregierte Senken erstellen, mit denen Logeinträge für eine Organisation oder einen Ordner und deren untergeordnete Elemente an das in der Senke angegebene Ziel weitergeleitet werden. Es gibt zwei Arten von aggregierten Senken:
- Nicht abfangende aggregierte Senken
- Aggregierte Senken abfangen
Der Unterschied zwischen diesen beiden Senkentypen besteht darin, dass das Abfangen von Senken auf einer Ebene in der Ressourcenhierarchie sich auf das Routing für Ressourcen auswirken kann, die sich weiter unten in der Hierarchie befinden. Nicht abfangende Senken haben keine Auswirkungen auf das Routing für andere Ressourcen. Wenn eine abfangende Senke in einer Ressource mit einem Logeintrag übereinstimmt, wird der Logeintrag nicht an die Senken in untergeordneten Ressourcen gesendet. Eine Ausnahme besteht jedoch: Der Logeintrag wird immer an die
_Required-Logsenke in der Ressource gesendet, in der der Logeintrag stammt.Sie können Standardeinstellungen für Ressourcen konfigurieren, um die Konfiguration der vom System erstellten
_Default-Senke für neue Ressourcen in einer Organisation oder einem Ordner anzugeben. Sie können diese Einstellungen beispielsweise verwenden, um die_Default-Senke zu deaktivieren oder die Filter in dieser Senke anzugeben.
Routing-Beispiele
In diesem Abschnitt wird veranschaulicht, wie ein Logeintrag, der in einem Projekt erstellt wurde, durch die Senken in der zugehörigen Ressourcenhierarchie fließen kann.
Beispiel: Keine aggregierten Senken vorhanden
Wenn in der Ressourcenhierarchie des Logeintrags keine aggregierten Senken vorhanden sind, wird der Logeintrag an die Logsenken in dem Projekt gesendet, aus dem der Logeintrag stammt. Eine Senke auf Projektebene leitet den Logeintrag an das Ziel der Senke weiter, wenn der Logeintrag mit dem Einschlussfilter der Senke übereinstimmt, aber nicht mit einem der Ausschlussfilter der Senke.
Beispiel: Es ist ein nicht abfangender aggregierter Sink vorhanden.
Angenommen, in der Ressourcenhierarchie ist für einen Logeintrag eine nicht abfangende aggregierte Senke vorhanden. Nachdem der Log-Router den Logeintrag an die nicht abfangende aggregierte Senke gesendet hat, geschieht Folgendes:
Die nicht abfangende zusammengefasste Senke leitet den Logeintrag an das Ziel der Senke weiter, wenn der Logeintrag mit dem Einschlussfilter übereinstimmt, aber nicht mit einem Ausschlussfilter.
Der Log-Router sendet den Logeintrag an die Logsenken in dem Projekt, in dem der Logeintrag erstellt wurde.
Eine Senke auf Projektebene leitet den Logeintrag an das Ziel der Senke weiter, wenn der Logeintrag mit dem Einschlussfilter der Senke übereinstimmt, aber nicht mit einem der Ausschlussfilter der Senke.
Beispiel: Eine abfangende aggregierte Senke ist vorhanden
Angenommen, in der Ressourcenhierarchie ist eine abfangende aggregierte Senke für einen Logeintrag vorhanden. Nachdem der Log-Router den Logeintrag an die abfangende aggregierte Senke gesendet hat, geschieht eines der folgenden Dinge:
Der Logeintrag stimmt mit dem Einschlussfilter überein, aber nicht mit einem Ausschlussfilter:
- Der Logeintrag wird an das Ziel der abfangenden aggregierten Senke weitergeleitet.
- Der Logeintrag wird an die
_Required-Senke in dem Projekt gesendet, in dem der Logeintrag erstellt wurde.
Der Logeintrag stimmt nicht mit dem Einschlussfilter überein oder er stimmt mit mindestens einem Ausschlussfilter überein:
- Der Logeintrag wird nicht von der abfangenden aggregierten Senke weitergeleitet.
Der Log-Router sendet den Logeintrag an die Logsenken in dem Projekt, in dem der Logeintrag erstellt wurde.
Eine Senke auf Projektebene leitet den Logeintrag an das Ziel der Senke weiter, wenn der Logeintrag mit dem Einschlussfilter der Senke übereinstimmt, aber nicht mit einem der Ausschlussfilter der Senke.
Filter für Logsenken
Jede Logs-Senke enthält einen Einschlussfilter und kann mehrere Ausschlussfilter enthalten. Mit diesen Filtern wird festgelegt, ob die Logsenke einen Logeintrag an das Ziel der Senke weiterleitet. Wenn Sie keine Filter angeben, wird jeder Logeintrag an das Ziel der Senke weitergeleitet.
Ein Logeintrag wird von einem Log-Sink anhand der folgenden Regeln weitergeleitet:
Wenn der Logeintrag nicht mit dem Einschlussfilter übereinstimmt, wird er nicht weitergeleitet. Wenn für eine Senke kein Einschlussfilter angegeben ist, stimmt jeder Logeintrag mit diesem Filter überein.
Wenn der Logeintrag mit dem Einschlussfilter und mindestens einem Ausschlussfilter übereinstimmt, wird er nicht weitergeleitet.
Wenn der Logeintrag mit dem Einschlussfilter übereinstimmt und mit keinem Ausschlussfilter, wird er an das Ziel der Senke weitergeleitet.
Die Filter in einer Logsenke werden mit der Logging-Abfragesprache angegeben.
Sie können Ausschlussfilter nicht verwenden, um die Nutzung Ihres entries.write API-Kontingents oder die Anzahl der entries.write API-Aufrufe zu reduzieren. Ausschlussfilter werden angewendet, nachdem Logeinträge von der Logging API empfangen wurden.
Vom System erstellte Logsenken
Für jedes Google Cloud Projekt, Rechnungskonto, Ordner und jede Organisation erstellt Cloud Logging zwei Logsinks: einen mit dem Namen _Required und einen mit dem Namen _Default. Die Ein- und Ausschlussfilter für diese Senken sorgen dafür, dass jeder Logeintrag, der die Ressource erreicht, über eine dieser Senken weitergeleitet wird.
Beide Senken leiten Logdaten an einen Log-Bucket weiter, der sich in derselben Ressource wie die Logsenke befindet.
Im Rest dieses Abschnitts finden Sie Informationen zu den Filtern und Zielen der vom System erstellten Logsinks.
_Required Logsenke
Die _Required-Logsenke in einer Ressource leitet eine Teilmenge von Audit-Logs an den _Required-Log-Bucket der Ressource weiter.
Für diese Senke sind keine Ausschlussfilter angegeben und der Einschlussfilter ist wie folgt:
LOG_ID("cloudaudit.googleapis.com/activity") OR
LOG_ID("externalaudit.googleapis.com/activity") OR
LOG_ID("cloudaudit.googleapis.com/system_event") OR
LOG_ID("externalaudit.googleapis.com/system_event") OR
LOG_ID("cloudaudit.googleapis.com/access_transparency") OR
LOG_ID("externalaudit.googleapis.com/access_transparency")
Die Logsenke _Required entspricht nur Logeinträgen, die von der Ressource stammen, in der die Logsenke _Required definiert ist. Angenommen, eine Log-Senke leitet einen Aktivitätslogeintrag aus dem Projekt A an das Projekt B weiter.
Da der Logeintrag nicht aus dem Projekt B stammt, wird er durch die _Required-Logs-Senke im Projekt B nicht an den _Required-Log-Bucket weitergeleitet.
Sie können die Logs-Senke _Required nicht ändern oder löschen.
_Default Logsenke
Die _Default-Logsenke in einer Ressource leitet alle Logeinträge mit Ausnahme derer, die mit dem Filter der _Required-Logsenke übereinstimmen, an den _Default-Log-Bucket der Ressource weiter.
Da der Einschlussfilter für diese Senke leer ist, stimmt er mit allen Logeinträgen überein. Der Ausschlussfilter ist jedoch so konfiguriert:
NOT LOG_ID("cloudaudit.googleapis.com/activity") AND
NOT LOG_ID("externalaudit.googleapis.com/activity") AND
NOT LOG_ID("cloudaudit.googleapis.com/system_event") AND
NOT LOG_ID("externalaudit.googleapis.com/system_event") AND
NOT LOG_ID("cloudaudit.googleapis.com/access_transparency") AND
NOT LOG_ID("externalaudit.googleapis.com/access_transparency")
Sie können die Logs-Senke _Default ändern und deaktivieren. Sie können beispielsweise die Logsenke _Default bearbeiten und das Ziel ändern. Sie können auch vorhandene Filter ändern und Ausschlussfilter hinzufügen.
Senkenziele
Das Ziel einer Senke kann sich in einer anderen Ressource als die Senke befinden. Sie können beispielsweise eine Logsenke verwenden, um Logeinträge aus einem Projekt an einen Log-Bucket weiterzuleiten, der in einem anderen Projekt gespeichert ist.
Die folgenden Ziele werden unterstützt:
- Google Cloud -Projekt
Wählen Sie dieses Ziel aus, wenn die Logsenken im Zielprojekt Ihre Logeinträge umleiten sollen oder wenn Sie eine abfangende aggregierte Senke erstellt haben. Die Logsenken im Projekt, das das Senkenziel ist, können die Logeinträge an jedes unterstützte Ziel außer einem Projekt weiterleiten.
- Log-Bucket
Wählen Sie dieses Ziel aus, wenn Sie Ihre Logdaten in von Cloud Logging verwalteten Ressourcen speichern möchten. Logdaten, die in Log-Buckets gespeichert sind, können mit Diensten wie dem Log-Explorer und Log Analytics aufgerufen und analysiert werden.
Wenn Sie Ihre Logdaten mit anderen Geschäftsdaten verknüpfen möchten, können Sie sie in einem Log-Bucket speichern und ein verknüpftes BigQuery-Dataset erstellen. Ein verknüpftes Dataset ist ein schreibgeschütztes Dataset, das wie jedes andere BigQuery-Dataset abgefragt werden kann.
- BigQuery-Dataset
- Wählen Sie dieses Ziel aus, wenn Sie Ihre Logdaten mit anderen Geschäftsdaten zusammenführen möchten. Das von Ihnen angegebene Dataset muss für Schreibvorgänge aktiviert sein. Legen Sie für das Ziel einer Senke kein verknüpftes BigQuery-Dataset fest. Verknüpfte Datasets sind schreibgeschützt.
- Cloud Storage-Bucket
- Wählen Sie dieses Ziel aus, wenn Sie Ihre Logdaten langfristig speichern möchten. Der Cloud Storage-Bucket kann sich im selben Projekt befinden, in dem die Logeinträge erstellt werden, oder in einem anderen Projekt. Logeinträge werden als JSON-Dateien gespeichert.
- Pub/Sub-Thema
- Wählen Sie dieses Ziel aus, wenn Sie Ihre Protokolldaten ausGoogle Cloud exportieren und dann Drittanbieterintegrationen wie Splunk oder Datadog verwenden möchten. Logeinträge werden in JSON formatiert und dann an ein Pub/Sub-Thema weitergeleitet.
Einschränkungen für Ziele
In diesem Abschnitt werden zielgruppenspezifische Einschränkungen beschrieben:
- Wenn Sie Logeinträge an einen Log-Bucket in einem anderen Google Cloud Projekt weiterleiten, werden diese Logeinträge nicht von Error Reporting analysiert. Weitere Informationen finden Sie unter Error Reporting – Übersicht.
- Wenn Sie Logeinträge an ein BigQuery-Dataset weiterleiten, muss das BigQuery-Dataset schreibgeschützt sein. Sie können keine Logeinträge an verknüpfte Datasets weiterleiten, die schreibgeschützt sind.
- Bei neuen Senken, die Logdaten an Cloud Storage-Buckets weiterleiten, kann es mehrere Stunden dauern, bis Logeinträge weitergeleitet werden. Diese Senken werden stündlich verarbeitet.
Die folgenden Einschränkungen gelten, wenn das Ziel eines Log-Senken ein Google Cloud -Projekt ist:
- Es gibt ein Hop-Limit.
- Logeinträge, die dem Filter der
_Required-Logsenke entsprechen, werden nur dann an den_Required-Log-Bucket des Zielprojekts weitergeleitet, wenn sie aus dem Zielprojekt stammen. - Nur aggregierte Senken, die sich in der Ressourcenhierarchie eines Logeintrags befinden, verarbeiten den Logeintrag.
Angenommen, das Ziel einer Logs-Senke im Projekt
Aist das ProjektB. Dann gilt Folgendes:- Aufgrund der Beschränkung auf einen Hop können die Logsinks im Projekt
BLogeinträge nicht an ein Google Cloud -Projekt weiterleiten. - Im
_Required-Log-Bucket des ProjektsBwerden nur Logeinträge gespeichert, die aus dem ProjektBstammen. In diesem Log-Bucket werden keine Logeinträge gespeichert, die aus einer anderen Ressource stammen, einschließlich der Einträge, die aus dem ProjektAstammen. - Wenn sich die Ressourcenhierarchie von Projekt
Aund ProjektBunterscheidet, wird ein Logeintrag, den eine Logs-Senke in ProjektAan ProjektBweiterleitet, nicht an die aggregierten Senken in der Ressourcenhierarchie von ProjektBgesendet. - Wenn Projekt
Aund ProjektBdieselbe Ressourcenhierarchie haben, werden Logeinträge an die aggregierten Senken in dieser Hierarchie gesendet. Wenn ein Logeintrag nicht von einer aggregierten Senke abgefangen wird, sendet der Log-Router den Logeintrag an die Senken im ProjektA.
Auswirkungen des Routings von Logeinträgen auf logbasierte Messwerte
Logbasierte Messwerte sind Cloud Monitoring-Messwerte, die aus dem Inhalt von Logeinträgen abgeleitet werden. Sie können beispielsweise einen logbasierten Messwert verwenden, um die Anzahl der Logeinträge zu zählen, die eine bestimmte Nachricht enthalten, oder um in Logeinträgen aufgezeichnete Latenzinformationen zu extrahieren. Sie können logbasierte Messwerte in Cloud Monitoring-Diagrammen darstellen und Benachrichtigungsrichtlinien können diese Messwerte überwachen.
Systemdefinierte logbasierte Messwerte gelten auf Projektebene. Benutzerdefinierte logbasierte Messwerte können auf Projekt- oder Log-Bucket-Ebene angewendet werden. Logbasierte Messwerte auf Bucket-Ebene sind nützlich, wenn Sie aggregierte Senken verwenden, um Logeinträge an einen Log-Bucket weiterzuleiten, und wenn Sie Logeinträge aus einem Projekt an einen Log-Bucket in einem anderen Projekt weiterleiten.
- Systemdefinierte logbasierte Messwerte
-
Der Log-Router zählt einen Logeintrag, wenn alle der folgenden Bedingungen erfüllt sind:
- Der Logeintrag wird über die Logsinks des Projekts weitergeleitet, in dem der logbasierte Messwert definiert ist.
Der Logeintrag wird in einem Log-Bucket gespeichert. Der Log-Bucket kann sich in einem beliebigen Projekt befinden.
Angenommen, das Projekt
Ahat eine Logs-Senke, deren Ziel das ProjektBist. Nehmen Sie außerdem an, dass die Logsenken im ProjektBdie Logeinträge an ein Log-Bucket weiterleiten. In diesem Szenario tragen die Logeinträge, die von ProjektAzu ProjektBweitergeleitet werden, zu den systemdefinierten logbasierten Messwerten von ProjektAbei. Diese Logeinträge werden auch für die systemdefinierten logbasierten Messwerte des ProjektsBberücksichtigt.
- Benutzerdefinierte logbasierte Messwerte
-
Der Log-Router zählt einen Logeintrag, wenn alle der folgenden Bedingungen erfüllt sind:
- Die Abrechnung ist für das Projekt aktiviert, in dem der logbasierte Messwert definiert ist.
- Bei Messwerten auf Bucket-Ebene wird der Logeintrag in dem Log-Bucket gespeichert, in dem der logbasierte Messwert definiert ist.
- Bei Messwerten auf Projektebene durchläuft der Logeintrag die Logsinks des Projekts, in dem der logbasierte Messwert definiert ist.
Weitere Informationen finden Sie unter Übersicht über logbasierte Messwerte.
Best Practices
Best Practices für die Verwendung von Routing für Data Governance oder für gängige Anwendungsfälle finden Sie in den folgenden Dokumenten:
Logdaten: Eine Schritt-für-Schritt-Anleitung zur Bewältigung häufiger Compliance-Herausforderungen
Data Governance: Grundsätze für die Sicherung und Verwaltung von Logs
Beispiele: Logspeicher zentralisieren
In diesem Abschnitt wird beschrieben, wie Sie zentralen Speicher konfigurieren können. Durch die zentrale Speicherung können Sie Logdaten an einem einzigen Ort abfragen. Das vereinfacht Ihre Abfragen, wenn Sie nach Trends suchen oder Probleme untersuchen. Aus Sicherheitssicht haben Sie auch einen Speicherort, was die Aufgaben Ihrer Sicherheitsanalysten vereinfachen kann.
Wenn Sie Ihre Logs zentral speichern, sollten Sie überlegen, ob Sie das Projekt, in dem Ihre Logdaten gespeichert werden, sperren möchten. Eine Sperre kann das versehentliche Löschen eines Projekts verhindern. Weitere Informationen finden Sie unter Projekte mit Sperren schützen.
Logspeicher für Projekte in einem Ordner zentralisieren
Angenommen, Sie verwalten einen Ordner und möchten den Speicher Ihrer Logeinträge zentralisieren. Für diesen Anwendungsfall können Sie Folgendes tun:
- In diesem Ordner erstellen Sie ein Projekt mit dem Namen
CentralStorage. - Erstellen Sie eine abfangende aggregierte Senke für Ihren Ordner und konfigurieren Sie sie so, dass alle Logeinträge weitergeleitet werden. Sie legen das Ziel der Senke auf das Projekt mit dem Namen
CentralStoragefest.
Wenn ein Logeintrag, der im Ordner oder in einer seiner untergeordneten Ressourcen stammt, eingeht, wird er an die von Ihnen erstellte abfangende aggregierte Senke gesendet. Über diese Senke werden Logeinträge an das Projekt mit dem Namen CentralStorage weitergeleitet. Die Logsenken in diesem Projekt verarbeiten die Logeinträge:
Die
_Default-Logsenke leitet alle Logeinträge, die dem Filter der Senke entsprechen, an den_Default-Log-Bucket weiter. Dieser Log-Bucket ist Ihr zentraler Speicherort.Die
_Required-Logsenke leitet Logeinträge, die den Filtern der Senke entsprechen und aus demCentralStorage-Projekt stammen, an den_Required-Log-Bucket weiter. Dieser Log-Bucket ist kein zentraler Speicherort. Sie können jedoch alle Ihre Protokolldaten zentral speichern. Ein Beispiel finden Sie unter Audit-Logs an einem zentralen Ort speichern.
Nachdem die Verarbeitung der aggregierten Senke abgeschlossen ist, wird der Logeintrag an die _Required-Logsenke in der Ressource gesendet, in der der Logeintrag erstellt wurde. Wenn der Logeintrag mit dem Filter in der _Required-Logsenke übereinstimmt, wird er an den _Required-Log-Bucket der Ressource weitergeleitet. Folglich werden Logeinträge für jedes Google Cloud Projekt in Ihrem Ordner im zugehörigen _Required-Log-Bucket gespeichert.
Logspeicher für eine Reihe von Projekten zentralisieren
Sie können Logeinträge auch an einem einzigen Ort speichern, wenn Sie keine Organisation oder keinen Ordner haben. Zum Beispiel könnten Sie Folgendes tun:
- Erstellen Sie ein Projekt mit dem Namen
CentralStorage. - Für jedes Projekt außer
CentralStoragebearbeiten Sie die Logs-Senke_Defaultund legen als Ziel das Projekt mit dem NamenCentralStoragefest.
Sie fragen sich vielleicht, warum im vorherigen Beispiel das Ziel der _Default-Logsinks ein Projekt und nicht der _Default-Log-Bucket in diesem Projekt ist. Die Hauptgründe dafür sind Einfachheit und Einheitlichkeit.
Wenn Sie Logeinträge an ein Projekt weiterleiten, wird durch die Logsinks im Zielprojekt gesteuert, welche Logeinträge gespeichert werden und wo sie gespeichert werden.
Das bedeutet, dass Sie die Filter- und Zielfunktionen zentralisieren. Wenn Sie ändern möchten, welche Logeinträge gespeichert werden oder wo sie gespeichert werden, müssen Sie nur die Log-Senken in einem Projekt ändern.
Zentrale Speicherung von Logs für Audit-Logs
Sie können Logeinträge, die der _Required-Logsenke entsprechen, zentral speichern. Wenn Sie diese Logeinträge zentral speichern möchten, haben Sie folgende Möglichkeiten:
Erstellen Sie Logsenken, die Logeinträge, die der Logsenke
_Requiredentsprechen, an einen zentralen Log-Bucket weiterleiten.Konfigurieren Sie Logsenken wie in den beiden vorherigen Beispielen und fügen Sie dann im Zielprojekt eine Logsenke hinzu, die Logeinträge, die der
_Required-Logsenke entsprechen, an einen Log-Bucket weiterleitet. Sie können die Filter auch in der_Default-Logsenke bearbeiten.
Bevor Sie eine solche Strategie implementieren, sollten Sie sich die Preisrichtlinien ansehen.
Preise
Informationen zu den Preisen für Cloud Logging finden Sie unter Preise für Google Cloud Observability.
Nächste Schritte
Informationen zum Weiterleiten und Speichern von Cloud Logging-Daten finden Sie in den folgenden Dokumenten:
Informationen zum Erstellen von Senken zum Weiterleiten von Logeinträgen an unterstützte Ziele finden Sie unter Logs an unterstützte Ziele weiterleiten.
Informationen zum Erstellen aggregierter Senken, mit denen Logeinträge aus den Ressourcen in Ordnern oder Organisationen weitergeleitet werden können, finden Sie unter Aggregierte Senken – Übersicht.
Informationen zum Format weitergeleiteter Logeinträge und dazu, wie die Logs in den Zielen organisiert werden, finden Sie in den folgenden Dokumenten: