Halaman ini menunjukkan cara melakukan operasi peluncuran inkremental, yang men-deploy versi baru infrastruktur inferensi Anda secara bertahap, untuk GKE Inference Gateway. Gateway ini memungkinkan Anda melakukan update yang aman dan terkontrol pada infrastruktur inferensi Anda. Anda dapat mengupdate node, model dasar, dan adaptor LoRA dengan gangguan layanan minimal. Halaman ini juga memberikan panduan tentang pemisahan traffic dan pengembalian untuk memastikan deployment yang andal.
Halaman ini ditujukan bagi admin akun dan Identitas GKE serta Developer yang ingin melakukan operasi peluncuran untuk GKE Inference Gateway.
Kasus penggunaan berikut didukung:
Memperbarui peluncuran node
Update node memigrasikan beban kerja inferensi dengan aman ke konfigurasi hardware node atau akselerator baru. Proses ini terjadi secara terkontrol tanpa mengganggu layanan model. Gunakan update node untuk meminimalkan gangguan layanan selama upgrade hardware, update driver, atau penyelesaian masalah keamanan.
Buat
InferencePoolbaru: men-deployInferencePoolyang dikonfigurasi dengan spesifikasi node atau hardware yang telah diupdate.Membagi traffic menggunakan
HTTPRoute: mengonfigurasiHTTPRouteuntuk mendistribusikan traffic antara resourceInferencePoolyang ada dan yang baru. Gunakan kolomweightdibackendRefsuntuk mengelola persentase traffic yang diarahkan ke node baru.Pertahankan
InferenceObjectiveyang konsisten: pertahankan konfigurasiInferenceObjectiveyang ada untuk memastikan perilaku model yang seragam di kedua konfigurasi node.Mempertahankan resource asli: pertahankan
InferencePooldan node asli tetap aktif selama peluncuran untuk memungkinkan rollback jika diperlukan.
Misalnya, Anda dapat membuat InferencePool baru bernama llm-new. Konfigurasi
kumpulan ini dengan konfigurasi model yang sama seperti llm
InferencePool yang ada. Deploy pool di kumpulan node baru dalam cluster Anda. Gunakan
objek HTTPRoute untuk membagi traffic antara llm asli dan llm-new InferencePool baru. Teknik ini memungkinkan Anda mengupdate node model secara inkremental.
Diagram berikut mengilustrasikan cara GKE Inference Gateway melakukan peluncuran update node.
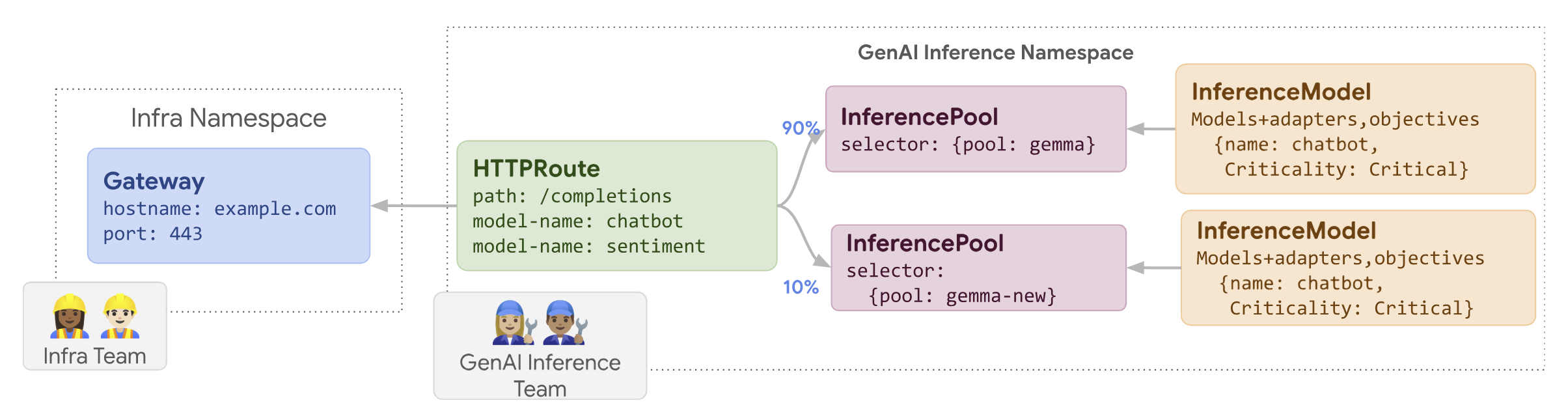
Untuk melakukan peluncuran update node, ikuti langkah-langkah berikut:
Simpan manifes contoh berikut sebagai
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Terapkan manifes contoh ke cluster Anda:
kubectl apply -f routes-to-llm.yaml
llm InferencePool asli menerima sebagian besar traffic, sedangkan
llm-new InferencePool menerima sisanya. Tingkatkan bobot traffic secara bertahap
untuk llm-new InferencePool guna menyelesaikan peluncuran update node.
Meluncurkan model dasar
Update model dasar diluncurkan secara bertahap ke LLM dasar baru, dengan tetap mempertahankan kompatibilitas dengan adaptor LoRA yang ada. Anda dapat menggunakan peluncuran update model dasar untuk mengupgrade ke arsitektur model yang lebih baik atau untuk mengatasi masalah khusus model.
Untuk meluncurkan update model dasar:
- Deploy infrastruktur baru: buat node baru dan
InferencePoolbaru yang dikonfigurasi dengan model dasar baru yang Anda pilih. - Konfigurasi distribusi traffic: gunakan
HTTPRouteuntuk membagi traffic antaraInferencePoolyang ada (yang menggunakan model dasar lama) danInferencePoolbaru (yang menggunakan model dasar baru). KolombackendRefs weightmengontrol persentase traffic yang dialokasikan ke setiap kumpulan. - Pertahankan integritas
InferenceObjective: jaga konfigurasiInferenceObjectiveAnda tetap tidak berubah. Hal ini memastikan bahwa sistem menerapkan adaptor LoRA yang sama secara konsisten di kedua versi model dasar. - Mempertahankan kemampuan rollback: mempertahankan node dan
InferencePoolasli selama peluncuran untuk memfasilitasi rollback jika diperlukan.
Anda membuat InferencePool baru bernama llm-pool-version-2. Kumpulan ini men-deploy
versi baru model dasar pada kumpulan node baru. Dengan
mengonfigurasi HTTPRoute, seperti yang ditunjukkan dalam contoh yang diberikan, Anda dapat
membagi traffic secara bertahap antara llm-pool asli dan
llm-pool-version-2. Opsi ini memungkinkan Anda mengontrol update model dasar di cluster.
Untuk melakukan peluncuran update model dasar, ikuti langkah-langkah berikut:
Simpan manifes contoh berikut sebagai
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Terapkan manifes contoh ke cluster Anda:
kubectl apply -f routes-to-llm.yaml
llm-pool InferencePool asli menerima sebagian besar traffic, sedangkan
llm-pool-version-2 InferencePool menerima sisanya. Tingkatkan bobot
traffic secara bertahap untuk llm-pool-version-2 InferencePool guna menyelesaikan
peluncuran update model dasar.