Questa pagina descrive come personalizzare il deployment di GKE Inference Gateway.
Questa pagina è rivolta agli specialisti di networking responsabili della gestione dell'infrastruttura GKE e agli amministratori della piattaforma che gestiscono i carichi di lavoro AI.
Per gestire e ottimizzare i carichi di lavoro di inferenza, configura le funzionalità avanzate di GKE Inference Gateway.
Comprendi e configura le seguenti funzionalità avanzate:
- Per utilizzare l'integrazione di Model Armor, configura i controlli di sicurezza dell'AI.
- Per migliorare GKE Inference Gateway con funzionalità come sicurezza API, limitazione di frequenza e analisi, configura Apigee per l'autenticazione e la gestione delle API.
- Per indirizzare le richieste in base al nome del modello nel corpo della richiesta, configura il routing basato sul corpo.
- Per visualizzare le metriche e i dashboard per GKE Inference Gateway e i server di modelli e per attivare la registrazione dell'accesso HTTP, configura l'osservabilità.
- Per scalare automaticamente i deployment di GKE Inference Gateway, configura la scalabilità automatica.
Configurare i controlli di sicurezza e protezione dell'AI
GKE Inference Gateway si integra con Model Armor per eseguire controlli di sicurezza su prompt e risposte per applicazioni che utilizzano modelli linguistici di grandi dimensioni (LLM). Questa integrazione fornisce un ulteriore livello di applicazione della sicurezza a livello di infrastruttura che integra le misure di sicurezza a livello di applicazione. Ciò consente l'applicazione centralizzata dei criteri a tutto il traffico LLM.
Il seguente diagramma illustra l'integrazione di Model Armor con GKE Inference Gateway su un cluster GKE:
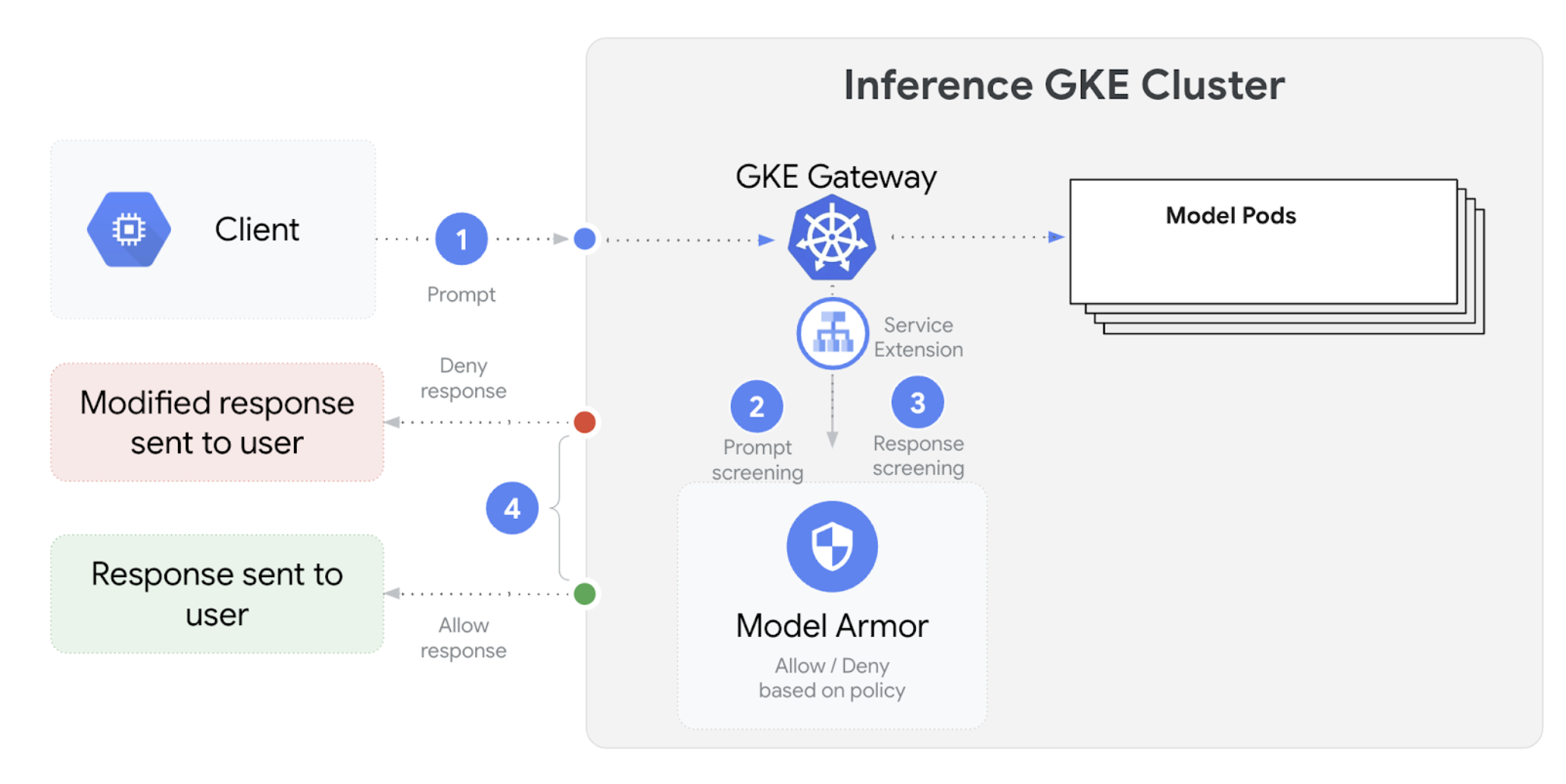
Per configurare i controlli di sicurezza dell'AI, segui questi passaggi:
Prerequisiti
- Abilita il servizio Model Armor nel tuo progetto Google Cloud .
Crea i template Model Armor utilizzando la console Model Armor, Google Cloud CLI o l'API. Il seguente comando crea un modello denominato
llmche registra le operazioni e filtra i contenuti dannosi.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
Concedi autorizzazioni IAM
Il account di servizio Service Extensions richiede autorizzazioni per accedere alle risorse necessarie. Concedi i ruoli richiesti eseguendo i seguenti comandi:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.userConfigura
GCPTrafficExtensionPer applicare i criteri di Model Armor al tuo gateway, crea una risorsa
GCPTrafficExtensioncon il formato dei metadati corretto.Salva il seguente manifest di esempio come
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Sostituisci quanto segue:
GATEWAY_NAME: il nome del gateway.MODEL_ARMOR_TEMPLATE_NAME: il nome del tuo template Model Armor.
Il file
gcp-traffic-extension.yamlinclude le seguenti impostazioni:targetRefs: specifica il gateway a cui si applica questa estensione.extensionChains: definisce una catena di estensioni da applicare al traffico.matchCondition: definisce le condizioni in base alle quali vengono applicate le estensioni.extensions: definisce le estensioni da applicare.supportedEvents: specifica gli eventi durante i quali viene richiamata l'estensione.timeout: specifica il timeout per l'estensione.googleAPIServiceName: specifica il nome del servizio per l'estensione.metadata: specifica i metadati dell'estensione, incluse le impostazioni di pulizia diextensionPolicye prompt o risposte.
Applica il manifest di esempio al cluster:
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Dopo aver configurato i controlli di sicurezza dell'AI e averli integrati con il gateway, Model Armor filtra automaticamente prompt e risposte in base alle regole definite.
Configurare Apigee per l'autenticazione e la gestione delle API
GKE Inference Gateway si integra con Apigee per fornire autenticazione, autorizzazione e gestione delle API per i carichi di lavoro di inferenza. Per scoprire di più sui vantaggi dell'utilizzo di Apigee, consulta Vantaggi principali dell'utilizzo di Apigee.
Puoi integrare GKE Inference Gateway con Apigee per migliorarlo con funzionalità come sicurezza API, limitazione di frequenza, quote, analisi e monetizzazione.
Prerequisiti
Prima di iniziare, assicurati di disporre di quanto segue:
- Un cluster GKE che esegue la versione 1.34.* o successive.
- Un cluster GKE con GKE Inference Gateway di cui è stato eseguito il deployment.
- Un'istanza Apigee creata nella stessa regione del cluster GKE.
- L'operatore Apigee APIM e i relativi CRD installati nel cluster GKE. Per istruzioni, vedi Installare l'operatore Apigee APIM.
kubectlconfigurato per connettersi al cluster GKE.Google Cloud CLIinstallato e autenticato.
Crea un ApigeeBackendService
Per prima cosa, crea una risorsa ApigeeBackendService. GKE Inference Gateway utilizza questo valore per creare un processore di estensioni Apigee.
Salva il seguente manifest come
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Sostituisci quanto segue:
APIGEE_ENVIRONMENT_NAME: il nome del tuo ambiente Apigee. Nota: non è necessario impostare questo campo seapigee-apim-operatorè installato con il flaggenerateEnv=TRUE. In caso contrario, crea un ambiente Apigee seguendo le istruzioni riportate in Crea un ambiente.LOCATION: la posizione dell'istanza Apigee.CLUSTER_NETWORK: la rete del tuo cluster GKE.CLUSTER_SUBNETWORK: la subnet del tuo cluster GKE.
Applica il manifest al cluster:
kubectl apply -f my-apigee-backend-service.yamlVerifica che lo stato sia diventato
CREATED:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
Configura GKE Inference Gateway
Configura GKE Inference Gateway per attivare Apigee Extension Processor come estensione del traffico del bilanciatore del carico.
Salva il seguente manifest come
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Sostituisci
GATEWAY_NAMEcon il nome del gateway.Applica il manifest al cluster:
kubectl apply -f my-apigee-traffic-extension.yamlAttendi che lo stato di
GCPTrafficExtensiondiventiProgrammed:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Inviare richieste autenticate utilizzando le chiavi API
Per trovare l'indirizzo IP del gateway di inferenza GKE, controlla lo stato del gateway:
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Sostituisci
GATEWAY_NAMEcon il nome del gateway.Testa una richiesta senza autenticazione. Questa richiesta deve essere rifiutata:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Verrà visualizzata una risposta simile alla seguente, che indica che l'estensione Apigee funziona:
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Accedi alla UI di Apigee e crea una chiave API. Per istruzioni, consulta Crea una chiave API.
Invia la chiave API nell'intestazione della richiesta HTTP:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Sostituisci
API_KEYcon la tua chiave API.
Per informazioni più dettagliate sulla configurazione delle policy Apigee, vedi Utilizzare le policy di gestione delle API con l'operatore APIM Apigee per Kubernetes.
Configura l'osservabilità
GKE Inference Gateway fornisce informazioni dettagliate su integrità, prestazioni e comportamento dei tuoi carichi di lavoro di inferenza. Ciò ti aiuta a identificare e risolvere i problemi, ottimizzare l'utilizzo delle risorse e garantire l'affidabilità delle tue applicazioni.
Google Cloud fornisce le seguenti dashboard di Cloud Monitoring che offrono l'osservabilità dell'inferenza per GKE Inference Gateway:
- Dashboard GKE Inference Gateway: fornisce metriche fondamentali per il servizio LLM, come throughput di richieste e token, latenza, errori e utilizzo della cache per
InferencePool. Per visualizzare l'elenco completo delle metriche di GKE Inference Gateway disponibili, consulta Metriche esposte. - Dashboard di osservabilità AI/ML: fornisce dashboard per l'utilizzo dell'infrastruttura, le metriche DCGM e le metriche delle prestazioni del modello vLLM.
- Dashboard del server modello: fornisce una
dashboard per gli indicatori aurei del server modello. In questo modo puoi monitorare il carico e le prestazioni dei server dei modelli, ad esempio
KVCache UtilizationeQueue length. - Dashboard del bilanciatore del carico: riporta le metriche del bilanciatore del carico, ad esempio le richieste al secondo, la latenza di gestione delle richieste end-to-end e i codici di stato richiesta-risposta. Queste metriche ti aiutano a comprendere le prestazioni della gestione delle richieste end-to-end e a identificare gli errori.
- Metriche Data Center GPU Manager (DCGM): fornisce metriche DCGM, come le prestazioni e l'utilizzo delle GPU NVIDIA. Puoi configurare le metriche DCGM in Cloud Monitoring. Per ulteriori informazioni, consulta Raccogliere e visualizzare le metriche DCGM.
Visualizza la dashboard di GKE Inference Gateway
Per visualizzare la dashboard di GKE Inference Gateway, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Monitoring.
Nel riquadro di navigazione, seleziona Dashboard.
Nella sezione Integrazioni, seleziona GMP.
Nella pagina Modelli di dashboard di Cloud Monitoring, cerca "Gateway".
Visualizza la dashboard di GKE Inference Gateway.
In alternativa, puoi seguire le istruzioni riportate in Dashboard di monitoraggio.
Visualizza le dashboard di osservabilità dei modelli AI/ML
Per visualizzare i modelli e i dashboard di cui è stato eseguito il deployment per le metriche di osservabilità di un modello, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Modelli di cui è stato eseguito il deployment.
Per visualizzare i dettagli di un deployment specifico, tra cui metriche, log e dashboard, fai clic sul nome del modello nell'elenco.
Nella pagina dei dettagli del modello, fai clic sulla scheda Osservabilità per visualizzare le seguenti dashboard. Se ti viene richiesto, fai clic su Abilita per abilitare la dashboard.
- La dashboard Utilizzo dell'infrastruttura mostra le metriche di utilizzo.
- La dashboard DCGM mostra le metriche DCGM.
- Se utilizzi vLLM, la dashboard Prestazioni del modello è disponibile e mostra le metriche per le prestazioni del modello vLLM.
Configurare la dashboard di osservabilità del server dei modelli
Per raccogliere indicatori chiave delle prestazioni da ogni server di modelli e capire cosa contribuisce al rendimento di GKE Inference Gateway, puoi configurare il monitoraggio automatico per i tuoi server di modelli. Sono inclusi server di modelli come i seguenti:
Per visualizzare le dashboard di integrazione, assicurati innanzitutto di raccogliere le metriche dal server del modello. Poi, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Monitoring.
Nel riquadro di navigazione, seleziona Dashboard.
In Integrazioni, seleziona GMP. Vengono visualizzate le dashboard di integrazione corrispondenti.
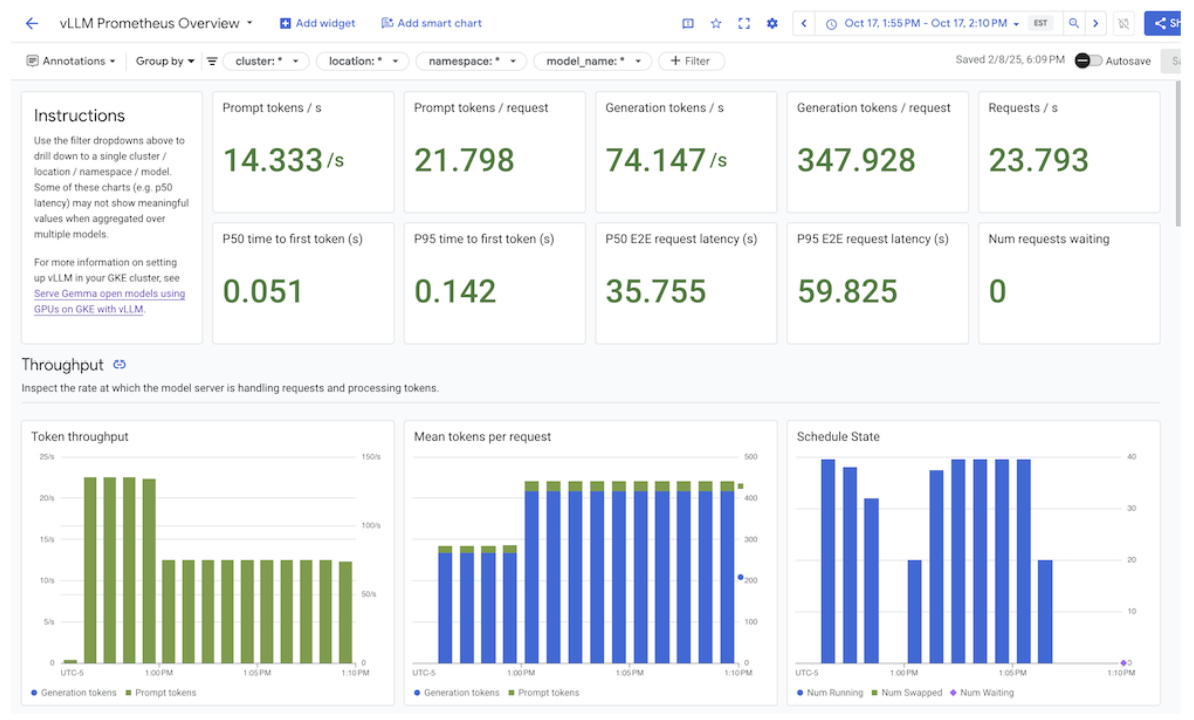
Figura: dashboard di integrazione
Per ulteriori informazioni, vedi Personalizzare il monitoraggio per le applicazioni.
Configurare gli avvisi di Cloud Monitoring
Per configurare gli avvisi di Cloud Monitoring per GKE Inference Gateway, segui questi passaggi:
Salva il seguente file manifest di esempio come
alerts.yamle modifica le soglie in base alle esigenze:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Per creare criteri di avviso, esegui questo comando:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlNella pagina Avvisi vengono visualizzate le nuove policy di avviso.
Modificare gli avvisi
Puoi trovare l'elenco completo delle metriche più recenti disponibili nel repository GitHub kubernetes-sigs/gateway-api-inference-extension e puoi aggiungere nuovi avvisi al manifest utilizzando altre metriche.
Per modificare gli avvisi di esempio, considera il seguente esempio:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Questo avviso viene attivato se il 99° percentile della durata della richiesta in 5 minuti
supera i 10 secondi. Puoi modificare la sezione expr dell'avviso per regolare la
soglia in base ai tuoi requisiti.
Configura la registrazione per GKE Inference Gateway
La configurazione della registrazione per GKE Inference Gateway fornisce informazioni dettagliate su richieste e risposte, utili per la risoluzione dei problemi, il controllo e l'analisi delle prestazioni. I log di accesso HTTP registrano ogni richiesta e risposta, inclusi intestazioni, codici di stato e timestamp. Questo livello di dettaglio può aiutarti a identificare i problemi, trovare gli errori e comprendere il comportamento dei tuoi carichi di lavoro di inferenza.
Per configurare la registrazione per GKE Inference Gateway, abilita la registrazione degli accessi HTTP per ciascuno dei tuoi oggetti InferencePool.
Salva il seguente manifest di esempio come
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMESostituisci quanto segue:
NAMESPACE_NAME: il nome dello spazio dei nomi in cui è stato eseguito il deployment diInferencePool.INFERENCE_POOL_NAME: il nome diInferencePool.
Applica il manifest di esempio al cluster:
kubectl apply -f logging-backend-policy.yaml
Dopo aver applicato questo manifest, GKE Inference Gateway abilita i log di accesso HTTP per il InferencePool specificato. Puoi visualizzare questi log in
Cloud Logging. I log includono informazioni dettagliate su ogni richiesta e
risposta, come l'URL della richiesta, le intestazioni, il codice di stato della risposta e la latenza.
Creare metriche basate sui log per visualizzare i dettagli degli errori
Puoi utilizzare le metriche basate sui log per analizzare i log di bilanciamento del carico ed estrarre
i dettagli degli errori. Ogni classe GKE Gateway, come le classi
gke-l7-global-external-managed e gke-l7-regional-internal-managed
Gateway, è supportata da un bilanciatore del carico diverso. Per ulteriori
informazioni, consulta Funzionalità
di GatewayClass.
Ogni bilanciatore del carico ha una risorsa monitorata diversa che devi utilizzare quando crei unametrica basata su logg. Per saperne di più sulla risorsa monitorata per ciascun bilanciatore del carico, consulta quanto segue:
- Per i bilanciatori del carico esterni regionali: metriche basate sui log per i bilanciatori del carico HTTP(S) esterni
- Per i bilanciatori del carico interni: metriche basate sui log per i bilanciatori del carico HTTP(S) interni
Per creare una metrica basata su log per visualizzare i dettagli dell'errore:
Crea un file JSON denominato
error_detail_metric.jsoncon la seguente definizione diLogMetric. Questa configurazione crea una metrica che estrae il campoproxyStatusdai log del bilanciatore del carico.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Sostituisci
MONITORED_RESOURCEcon la risorsa monitorata per il bilanciatore del carico.Apri Cloud Shell o il terminale locale in cui è installata gcloud CLI.
Per creare la metrica, esegui il comando
gcloud logging metrics createcon il flag--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Dopo aver creato la metrica, puoi utilizzarla in Cloud Monitoring per visualizzare la distribuzione degli errori segnalati dal bilanciatore del carico. Per saperne di più, vedi Creare una metrica basata su log.
Per saperne di più sulla creazione di avvisi dalle metriche basate su log, consulta Creare una criterio di avviso su una metrica del contatore.
Configura scalabilità automatica
La scalabilità automatica regola l'allocazione delle risorse in risposta alle variazioni di carico,
mantenendo le prestazioni e l'efficienza delle risorse aggiungendo o
rimuovendo dinamicamente i pod in base alla domanda. Per GKE Inference Gateway, ciò comporta la scalabilità automatica orizzontale dei pod in ogni InferencePool. Horizontal Pod Autoscaler (HPA) di GKE esegue la scalabilità automatica dei pod in base alle metriche del server di modelli
come KVCache Utilization. In questo modo, il servizio di inferenza gestisce
diversi carichi di lavoro e volumi di query, gestendo in modo efficiente l'utilizzo delle risorse.
Per configurare le istanze InferencePool in modo che vengano scalate automaticamente in base alle metriche prodotte da GKE Inference Gateway, segui questi passaggi:
Esegui il deployment di un oggetto
PodMonitoringnel cluster per raccogliere le metriche prodotte da GKE Inference Gateway. Per saperne di più, consulta Configurare l'osservabilità.Esegui il deployment dell'adattatore Stackdriver delle metriche personalizzate per consentire ad HPA di accedere alle metriche:
Salva il seguente manifest di esempio come
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemApplica il manifest di esempio al cluster:
kubectl apply -f adapter_new_resource_model.yaml
Per concedere all'adattatore le autorizzazioni per leggere le metriche del progetto, esegui questo comando:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSostituisci
PROJECT_IDcon l'ID del tuo progetto Google Cloud .Per ogni
InferencePool, esegui il deployment di un HPA simile al seguente:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUESostituisci quanto segue:
INFERENCE_POOL_NAME: il nome diInferencePool.INFERENCE_POOL_NAMESPACE: lo spazio dei nomi diInferencePool.CLUSTER_NAME: il nome del cluster.MIN_REPLICAS: la disponibilità minima diInferencePool(capacità di base). HPA mantiene questo numero di repliche quando l'utilizzo è inferiore alla soglia target di HPA. I carichi di lavoro ad alta disponibilità devono impostare questo valore su un valore superiore a1per garantire la disponibilità continua durante le interruzioni dei pod.MAX_REPLICAS: il valore che vincola il numero di acceleratori che devono essere assegnati ai carichi di lavoro ospitati inInferencePool. HPA non aumenterà il numero di repliche oltre questo valore. Durante i periodi di picco del traffico, monitora il numero di repliche per assicurarti che il valore del campoMAX_REPLICASfornisca un margine sufficiente in modo che il workload possa scalare per mantenere le caratteristiche di rendimento del workload scelte.TARGET_VALUE: il valore che rappresenta il targetKV-Cache Utilizationscelto per server modello. Si tratta di un numero compreso tra 0 e 100 e dipende molto dal server del modello, dal modello, dall'acceleratore e dalle caratteristiche del traffico in entrata. Puoi determinare questo valore target in modo sperimentale tramite test di carico e tracciando un grafico del throughput rispetto alla latenza. Seleziona una combinazione di velocità effettiva e latenza dal grafico e utilizza il valoreKV-Cache Utilizationcorrispondente come target HPA. Devi modificare e monitorare attentamente questo valore per ottenere i risultati di prezzo/rendimento che hai scelto. Puoi utilizzare GKE Inference Quickstart per determinare automaticamente questo valore.
Passaggi successivi
- Scopri di più su GKE Inference Gateway.
- Esegui il deployment di GKE Inference Gateway.
- Gestisci le operazioni di implementazione di GKE Inference Gateway.
- Esegui la pubblicazione con GKE Inference Gateway.