有些实体需要匹配模式,而不是具体字词。 例如,国民身份证号码、ID、牌照等。 借助正则表达式实体,您可以提供正则表达式进行匹配。
如何查找此数据
构建代理时,最常见的方法是使用 Dialogflow ES 控制台(访问文档,打开控制台)。以下说明着重介绍如何使用控制台。如需访问实体数据,请执行以下操作:
- 前往 Dialogflow ES 控制台。
- 选择一个代理。
- 在左侧边栏菜单中选择实体 (Entities)。
如果您要使用 API 而非控制台来构建代理,请参阅 EntityTypes 参考。 API 字段名称与控制台字段名称类似。 以下说明重点介绍控制台与 API 之间的重要区别。
复合正则表达式
每个正则表达式实体都对应一个模式,但如果它们都代表某一模式的变体,您可提供多个正则表达式。
代理训练期间,单个实体的所有正则表达式与交替运算符 (|) 结合形成一个复合正则表达式。
举例来说,如果您提供以下电话号码正则表达式:
^[2-9]\d{2}-\d{3}-\d{4}$^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
复合正则表达式变为:
^[2-9]\d{2}-\d{3}-\d{4}$|^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
正则表达式的顺序很重要。 复合正则表达式中的每个正则表达式按顺序进行处理。 发现有效匹配后,搜索就会停止。 举例来说,如果最终用户表述为“Seattle”:
Sea|Seattle会匹配“Sea”Seattle|Sea会匹配“Seattle”
语音识别功能的特殊处理
如果您的代理使用语音识别(也称为音频输入或语音转文字 (STT)),您的正则表达式在匹配字母和数字时需要特殊处理。 最终用户所说话语经过语音识别程序处理后才能进行实体匹配。 当话语中包含一系列字母或数字时,识别程序会用空格填充各个字符。 此外,识别程序会用字词形式解读数字。 举例来说,最终用户说出的“My ID is 123”可能会被识别为以下任意一种形式:
- “My ID is 123”
- “My ID is 1 2 3”
- “My ID is one two three”
如要容纳三位数字,您可以使用以下正则表达式:
\d{3}\d \d \d
(zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine)
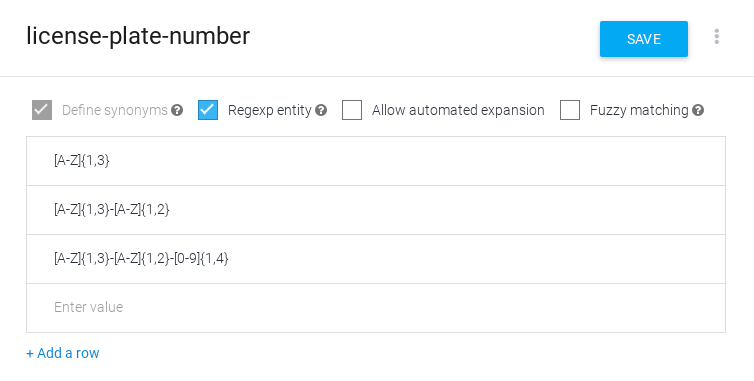
创建正则表达式实体
如需创建正则表达式实体,请执行以下操作:
- 打开现有实体或创建新实体。
- 勾选正则表达式实体。
- 在条目表格中输入一个或多个正则表达式。
- 点击保存 (Save)。
如果您使用 API 创建或更新实体,请在实体种类字段使用 KIND_REGEXP。
限制
存在以下限制: