Anda dapat mengirimkan tugas ke cluster Dataproc yang ada
melalui permintaan HTTP atau terprogram jobs.submit
Dataproc API, menggunakan alat command line gcloud
Google Cloud CLI di jendela terminal lokal atau di
Cloud Shell, atau dari konsol Google Cloud yang dibuka di browser lokal. Anda
juga dapat melakukan SSH ke instance master
di cluster, lalu menjalankan tugas langsung dari instance tanpa
menggunakan layanan Dataproc.
Cara mengirimkan tugas
Konsol
Buka halaman Dataproc Submit a job di konsol Google Cloud di browser Anda.
Contoh tugas Spark
Untuk mengirimkan sampel tugas Spark, isi kolom di halaman Submit a job, sebagai berikut:
- Pilih nama Cluster Anda dari daftar cluster.
- Tetapkan Jenis pekerjaan ke
Spark. - Tetapkan Main class or jar ke
org.apache.spark.examples.SparkPi. - Tetapkan Arguments ke argumen tunggal
1000. - Tambahkan
file:///usr/lib/spark/examples/jars/spark-examples.jarke file Jar:file:///menunjukkan skema Hadoop LocalFileSystem. Dataproc menginstal/usr/lib/spark/examples/jars/spark-examples.jardi node master cluster saat membuat cluster.- Atau, Anda dapat menentukan jalur Cloud Storage
(
gs://your-bucket/your-jarfile.jar) atau jalur Hadoop Distributed File System (hdfs://path-to-jar.jar) ke salah satu JAR Anda.
Klik Submit untuk memulai tugas. Setelah tugas dimulai, tugas tersebut akan ditambahkan ke daftar Tugas.
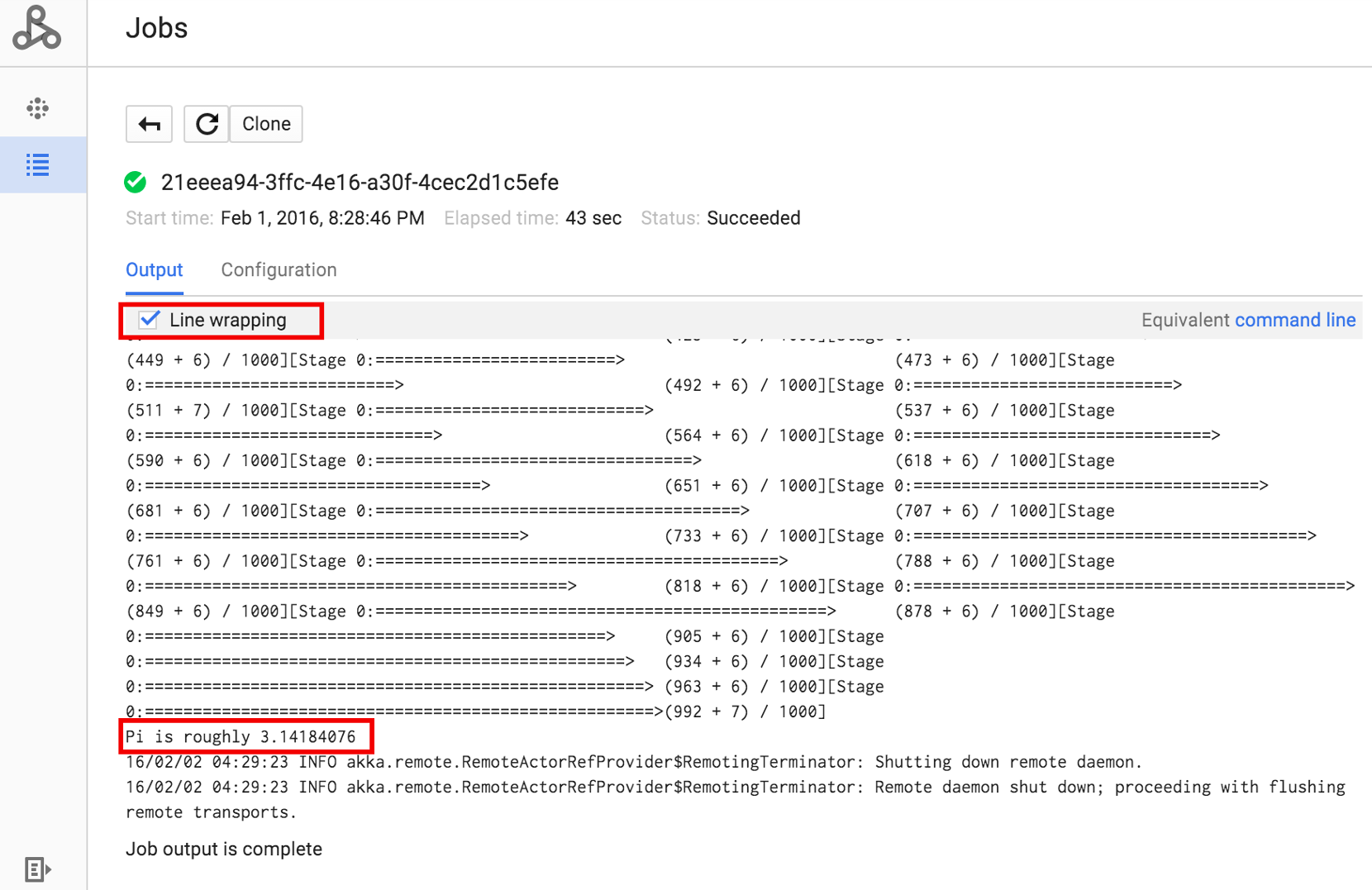
Klik ID Tugas untuk membuka halaman Tugas, tempat Anda dapat melihat output driver tugas. Karena tugas ini menghasilkan baris output panjang yang melebihi lebar jendela browser, Anda dapat mencentang kotak Pengepasan baris untuk menampilkan semua teks output dalam tampilan guna menampilkan hasil yang dihitung untuk pi.
Anda dapat melihat output driver tugas dari command line menggunakan perintah
gcloud dataproc jobs wait
yang ditampilkan di bawah (untuk mengetahui informasi selengkapnya, lihat
Melihat output tugas–PERINTAH GCLOUD).
Salin dan tempel project ID Anda sebagai nilai untuk tanda --project dan ID Pekerjaan Anda (ditampilkan di daftar Pekerjaan) sebagai argumen akhir.
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
Berikut adalah cuplikan dari output driver untuk tugas SparkPi
contoh yang dikirimkan di atas:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
Untuk mengirimkan tugas ke cluster Dataproc, jalankan perintah gcloud CLI gcloud dataproc jobs submit secara lokal di jendela terminal atau di Cloud Shell.
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- Mencantumkan
hello-world.pyyang dapat diakses secara publik dan terletak di Cloud Storage.gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- Kirim tugas Pyspark ke Dataproc.
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- Jalankan contoh SparkPi yang telah diinstal sebelumnya di node master
cluster Dataproc.
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
Bagian ini menunjukkan cara mengirimkan tugas Spark untuk menghitung perkiraan nilai
pi menggunakan Dataproc
API jobs.submit.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- project-id: Google Cloud project ID
- region: cluster region
- clusterName: nama cluster
Metode HTTP dan URL:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
Meminta isi JSON:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
- Instal library klien
- Menyiapkan kredensial default aplikasi
- Jalankan kode
Python
- Instal library klien
- Menyiapkan kredensial default aplikasi
- Jalankan kode
Go
- Instal library klien
- Menyiapkan kredensial default aplikasi
- Jalankan kode
Node.js
- Instal library klien
- Menyiapkan kredensial default aplikasi
- Jalankan kode
Mengirimkan tugas langsung di cluster Anda
Jika Anda ingin menjalankan tugas secara langsung di cluster tanpa menggunakan layanan Dataproc, lakukan SSH ke node master cluster Anda, lalu jalankan tugas di node master.
Setelah membuat koneksi SSH ke instance master VM, jalankan perintah di jendela terminal pada node master cluster untuk:
- Buka shell Spark.
- Jalankan tugas Spark sederhana untuk menghitung jumlah baris dalam file "hello-world" Python (tujuh baris) yang berada di file Cloud Storage yang dapat diakses secara publik.
Keluar dari shell.
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
Menjalankan tugas bash di Dataproc
Anda mungkin ingin menjalankan skrip bash sebagai tugas Dataproc, baik karena
mesin yang Anda gunakan tidak didukung sebagai jenis tugas Dataproc tingkat teratas atau karena
Anda perlu melakukan penyiapan atau penghitungan argumen tambahan sebelum meluncurkan
tugas menggunakan hadoop atau spark-submit dari skrip Anda.
Contoh Pig
Asumsikan Anda menyalin skrip bash hello.sh ke Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.shKarena perintah pig fs menggunakan jalur Hadoop, salin skrip dari
Cloud Storage ke tujuan yang ditentukan sebagai file:/// untuk memastikan
skrip berada di sistem file lokal, bukan HDFS. Perintah sh berikutnya
mereferensikan sistem file lokal secara otomatis dan tidak memerlukan awalan file:///.
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'Atau, karena tugas Dataproc yang mengirimkan argumen --jars melakukan staging file
ke dalam direktori sementara yang dibuat selama masa aktif tugas, Anda dapat menentukan
skrip shell Cloud Storage sebagai argumen --jars:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'Perhatikan bahwa argumen --jars juga dapat mereferensikan skrip lokal:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'