Questo documento elenca i messaggi di errore comuni dei job e fornisce informazioni sul monitoraggio e sul debug dei job per aiutarti a risolvere i problemi relativi ai job Dataproc.
Messaggi di errore comuni dei job
L'attività non è stata acquisita
Ciò indica che l'agente Dataproc sul nodo master non è riuscito ad acquisire l'attività dal control plane. Ciò si verifica spesso a causa di problemi di esaurimento della memoria o di rete. Se il job è stato eseguito correttamente in precedenza e non hai modificato le impostazioni di configurazione di rete, l'errore Out of Memory è la causa più probabile, spesso il risultato dell'invio di molti job in esecuzione contemporaneamente o di job i cui driver consumano una quantità significativa di memoria (ad esempio, job che caricano set di dati di grandi dimensioni in memoria).
Nessun agente sui nodi master trovato attivo
Ciò indica che l'agente Dataproc sul nodo master non è attivo e non può accettare nuovi job. Ciò accade spesso a causa di problemi di esaurimento della memoria o di rete oppure se la VM del nodo master non è integra. Se il job è stato eseguito correttamente in precedenza e non hai modificato le impostazioni di configurazione di rete, l'errore dovuto all'esaurimento della memoria è la causa più probabile, spesso dovuta all'invio di molti job in esecuzione contemporaneamente o di job i cui driver consumano una quantità significativa di memoria (job che caricano set di dati di grandi dimensioni in memoria).
Per risolvere il problema, prova a eseguire le seguenti azioni:
- Riavvia il job.
- Connettiti utilizzando SSH al nodo master del cluster e poi determina quale job o altra risorsa utilizza più memoria.
Se non riesci ad accedere al nodo master, controlla i log della porta seriale (console).

Genera un pacchetto diagnostico, che contiene il syslog e altri dati.
Attività non trovata
Questo errore indica che il cluster è stato eliminato durante l'esecuzione di un job. Puoi eseguire le seguenti azioni per identificare l'entità che ha eseguito l'eliminazione e verificare che l'eliminazione del cluster sia avvenuta durante l'esecuzione di un job:
Visualizza gli audit log di Dataproc per identificare l'entità che ha eseguito l'operazione di eliminazione.
Utilizza Logging o gcloud CLI per verificare che l'ultimo stato noto dell'applicazione YARN fosse RUNNING:
- Utilizza il seguente filtro in Logging:
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- Esegui
gcloud dataproc jobs describe job-id --region=REGION, poi controllayarnApplications: > STATEnell'output.
Se l'entità che ha eliminato il cluster è l'account di servizio dell'agente di servizio Dataproc, verifica se il cluster è stato configurato con una durata di eliminazione automatica inferiore alla durata del job.
Per evitare errori Task not found, utilizza l'automazione per assicurarti che i cluster non vengano eliminati
prima che tutti i job in esecuzione siano stati completati.
Spazio esaurito sul dispositivo
Dataproc scrive i dati HDFS e temporanei su disco. Questo messaggio di errore indica che il cluster è stato creato con spazio su disco insufficiente. Per analizzare ed evitare questo errore:
Controlla le dimensioni del disco primario del cluster elencate nella scheda Configurazione della pagina Dettagli cluster nella console Google Cloud . La dimensione minima consigliata del disco è
1000 GBper i cluster che utilizzano il tipo di macchinan1-standard-4e2 TBper i cluster che utilizzano il tipo di macchinan1-standard-32.Se la dimensione del disco del cluster è inferiore a quella consigliata, ricrea il cluster con almeno la dimensione del disco consigliata.
Se le dimensioni del disco sono quelle consigliate o superiori, utilizza SSH per connetterti alla VM master del cluster e poi esegui
df -hsulla VM master per controllare l'utilizzo del disco e determinare se è necessario spazio su disco aggiuntivo.
Monitoraggio e debug dei job
Utilizza Google Cloud CLI, l'API Dataproc REST e la console Google Cloud per analizzare ed eseguire il debug dei job Dataproc.
Interfaccia a riga di comando gcloud
Per esaminare lo stato di un job in esecuzione:
gcloud dataproc jobs describe job-id \ --region=region
Per visualizzare l'output del driver del job, consulta la sezione Visualizzare l'output del job.
API REST
Chiama jobs.get per esaminare i campi JobStatus.State, JobStatus.Substate, JobStatus.details e YarnApplication.
Console
Per visualizzare l'output del driver del job, consulta la sezione Visualizzare l'output del job.
Per visualizzare il log dell'agente Dataproc in Logging, seleziona Cluster Dataproc → Nome cluster → UUID cluster dal selettore del cluster di Esplora log.
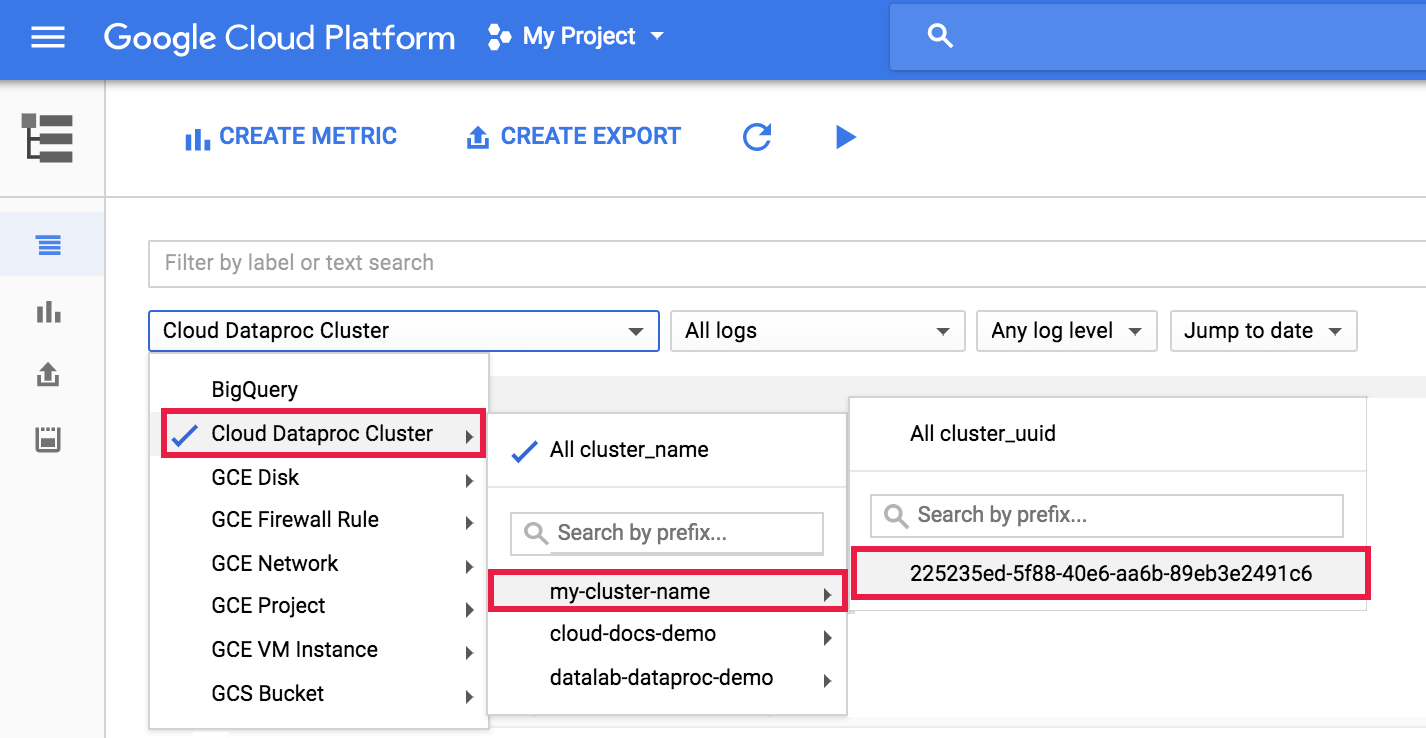
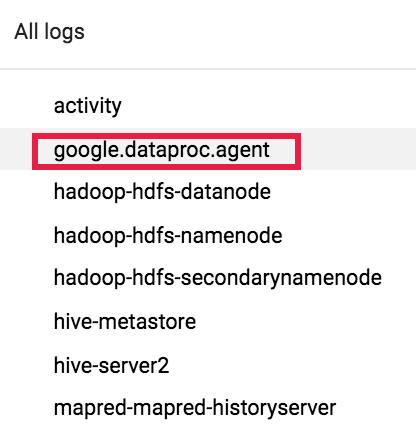
Poi utilizza il selettore dei log per selezionare i log google.dataproc.agent.
Visualizzare i log dei job in Logging
Se un job non va a buon fine, puoi accedere ai log dei job in Logging.
Determinare chi ha inviato un job
La ricerca dei dettagli di un job mostrerà chi ha inviato il job nel campo submittedBy. Ad esempio, questo output del job mostra che user@domain ha inviato il job di esempio a un cluster.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain