Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Konektor Hive-BigQuery open source memungkinkan beban kerja Apache Hive Anda membaca dan menulis data dari dan ke tabel BigQuery dan BigLake. Anda dapat menyimpan data di penyimpanan BigQuery atau dalam format data open source di Cloud Storage.
Konektor Hive-BigQuery menerapkan
Hive Storage Handler API
untuk memungkinkan workload Hive berintegrasi dengan tabel BigQuery dan BigLake. Mesin eksekusi Hive menangani operasi komputasi, seperti agregasi dan gabungan, dan konektor mengelola interaksi dengan data yang disimpan di BigQuery atau di bucket Cloud Storage yang terhubung dengan BigLake.
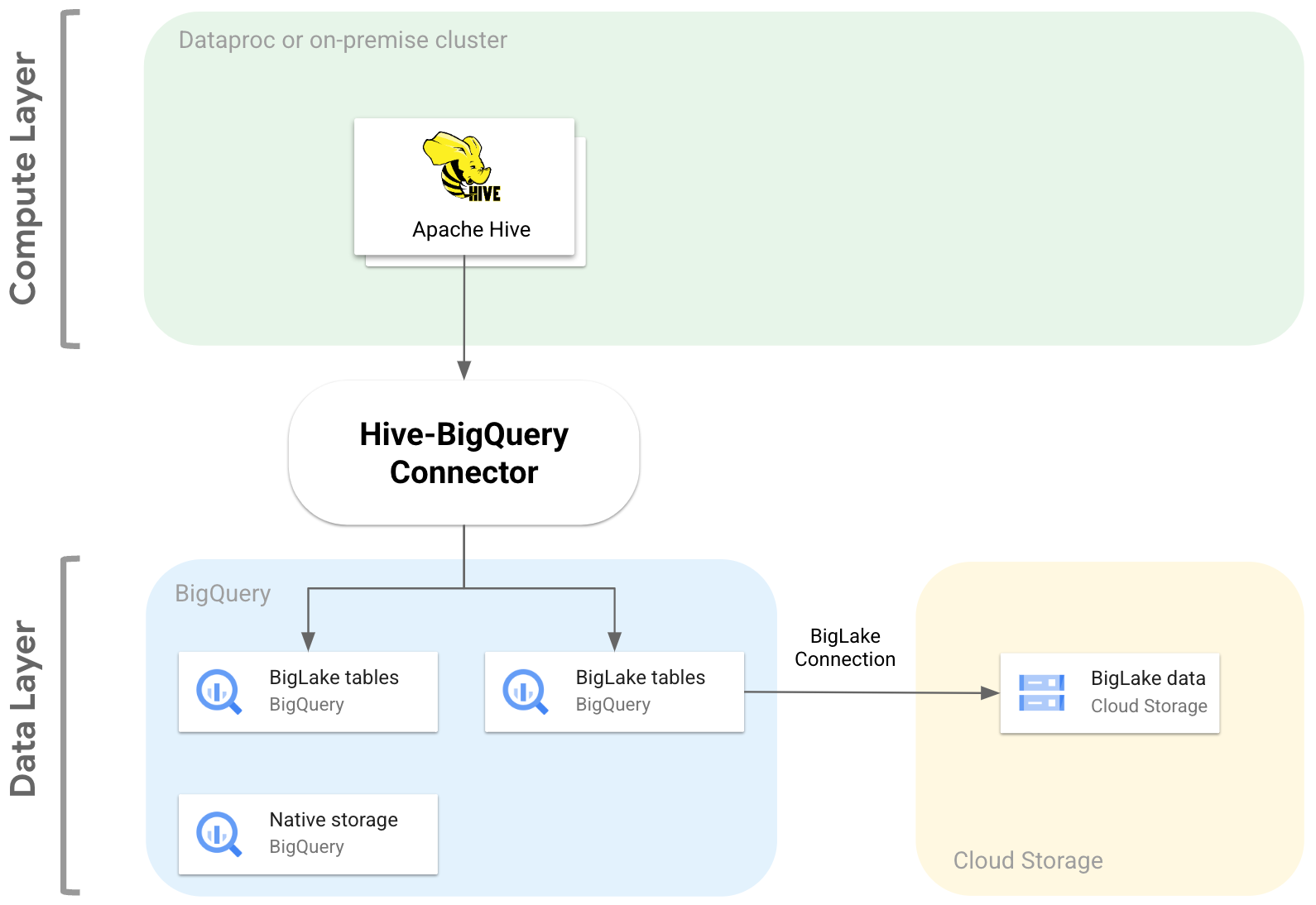
Diagram berikut menggambarkan cara konektor Hive-BigQuery
cocok di antara lapisan komputasi dan data.
Kasus penggunaan
Berikut beberapa cara konektor Hive-BigQuery dapat membantu Anda dalam
skenario umum berbasis data:
Migrasi data. Anda berencana memindahkan data warehouse Hive ke BigQuery, lalu menerjemahkan kueri Hive secara bertahap ke dialek SQL BigQuery.
Anda memperkirakan migrasi akan memakan waktu yang cukup lama karena ukuran data warehouse dan banyaknya aplikasi yang terhubung, dan Anda perlu memastikan kelangsungan selama operasi migrasi. Berikut alur kerjanya:
Anda memindahkan data ke BigQuery
Dengan menggunakan konektor, Anda dapat mengakses dan menjalankan kueri Hive asli sambil
menerjemahkan kueri Hive secara bertahap ke dialek SQL yang sesuai dengan
ANSI BigQuery.
Setelah menyelesaikan migrasi dan terjemahan, Anda akan menghentikan penggunaan Hive.
Alur kerja Hive dan BigQuery. Anda berencana menggunakan
Hive untuk beberapa tugas, dan BigQuery untuk workload yang diuntungkan
dari fiturnya, seperti BigQuery BI Engine atau
BigQuery ML. Anda menggunakan
konektor untuk menggabungkan tabel Hive ke tabel BigQuery Anda.
Ketergantungan pada stack software open source (OSS). Untuk menghindari ketergantungan pada vendor,
Anda menggunakan stack OSS lengkap untuk data warehouse. Berikut paket data Anda:
Anda memigrasikan data dalam format OSS aslinya, seperti Avro, Parquet, atau ORC, ke bucket Cloud Storage menggunakan koneksi BigLake.
Anda terus menggunakan Hive untuk menjalankan dan memproses kueri dialek Hive SQL.
Anda menggunakan konektor sesuai kebutuhan untuk terhubung ke BigQuery
guna memanfaatkan fitur berikut:
Tulis data ke BigQuery menggunakan metode berikut:
Penulisan langsung menggunakan
BigQuery Storage Write API dalam mode tertunda. Gunakan
metode ini untuk workload yang memerlukan latensi penulisan rendah, seperti dasbor
near-real-time dengan jangka waktu refresh yang singkat.
Penulisan tidak langsung dengan menyiapkan file Avro sementara ke Cloud Storage, lalu memuat file ke tabel tujuan menggunakan Load Job API.
Metode ini lebih murah daripada metode langsung, karena tugas pemuatan BigQuery tidak dikenai biaya. Karena metode ini lebih lambat, dan paling baik digunakan
dalam workload yang tidak memerlukan waktu yang mendesak
Akses tabel berpartisi menurut waktu
dan dikelompokkan BigQuery. Contoh berikut
menentukan hubungan antara tabel Hive dan tabel
yang dipartisi dan dikelompokkan di BigQuery.
Pangkas kolom untuk menghindari pengambilan kolom yang tidak perlu dari lapisan data.
Gunakan pushdown predikat untuk memfilter terlebih dahulu baris data di lapisan penyimpanan BigQuery. Teknik ini dapat meningkatkan performa kueri secara keseluruhan secara signifikan dengan
mengurangi jumlah data yang melintasi jaringan.
Mengonversi jenis data Hive ke jenis data BigQuery secara otomatis.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-02 UTC."],[[["\u003cp\u003eThe Hive-BigQuery connector enables Apache Hive workloads to interact with data in BigQuery and BigLake tables, allowing for data storage in either BigQuery or open-source formats on Cloud Storage.\u003c/p\u003e\n"],["\u003cp\u003eThis connector is beneficial for migrating from Hive to BigQuery, utilizing both Hive and BigQuery in tandem, or maintaining an entirely open-source data warehouse stack.\u003c/p\u003e\n"],["\u003cp\u003eUsing the Hive Storage Handler API, the connector manages data interactions, while Hive handles compute operations, like aggregates and joins, offering integration between the two platforms.\u003c/p\u003e\n"],["\u003cp\u003eThe connector supports direct writes to BigQuery for low-latency needs or indirect writes via temporary Avro files for cost-effective, non-time-critical operations.\u003c/p\u003e\n"],["\u003cp\u003eFeatures of the Hive-BigQuery connector include running queries with MapReduce and Tez engines, creating/deleting BigQuery tables from Hive, joining BigQuery and Hive tables, fast reads using the Storage Read API, column pruning, and predicate pushdowns for performance optimization.\u003c/p\u003e\n"]]],[],null,["The open source\n[Hive-BigQuery connector](https://github.com/GoogleCloudDataproc/hive-bigquery-connector)\nlets your [Apache Hive](https://hive.apache.org/)\nworkloads read and write data from and to [BigQuery](/bigquery) and\n[BigLake](/biglake) tables. You can store data in\nBigQuery storage or in open source data formats on\nCloud Storage.\n| Use the connector to work with Hive and BigQuery together or to migrate your data warehouse from Hive to BigQuery.\n\nThe Hive-BigQuery connector implements the\n[Hive Storage Handler API](https://cwiki.apache.org/confluence/display/Hive/StorageHandlers)\nto allow Hive workloads to integrate with BigQuery and BigLake\ntables. The Hive execution engine handles compute operations, such\nas aggregates and joins, and the connector manages interactions with\ndata stored in BigQuery or in BigLake-connected\nCloud Storage buckets.\n\nThe following diagram illustrates how Hive-BigQuery connector\nfits between the compute and data layers.\n\nUse cases\n\nHere are some of the ways the Hive-BigQuery connector can help you in\ncommon data-driven scenarios:\n\n- Data migration. You plan to move your Hive data warehouse to BigQuery,\n then incrementally translate your Hive queries into BigQuery SQL dialect.\n You expect the migration to take a significant amount of time due to the size\n of your data warehouse and the large number of connected applications, and\n you need to ensure continuity during the migration operations. Here's the\n workflow:\n\n 1. You move your data to BigQuery\n 2. Using the connector, you access and run your original Hive queries while you gradually translate the Hive queries to BigQuery ANSI-compliant SQL dialect.\n 3. After completing the migration and translation, you retire Hive.\n- Hive and BigQuery workflows. You plan to use\n Hive for some tasks, and BigQuery for workloads that benefit\n from its features, such as [BigQuery BI Engine](/bigquery/docs/bi-engine-intro) or\n [BigQuery ML](/bigquery/docs/bqml-introduction). You use\n the connector to join Hive tables to your BigQuery tables.\n\n- Reliance on an open source software (OSS) stack. To avoid vendor lock-in,\n you use a full OSS stack for your data warehouse. Here's your data plan:\n\n 1. You migrate your data in its original OSS format, such as Avro, Parquet, or\n ORC, to Cloud Storage buckets using a BigLake connection.\n\n 2. You continue to use Hive to execute and process your Hive SQL dialect queries.\n\n 3. You use the connector as needed to connect to BigQuery\n to benefit from the following features:\n\n - [Metadata caching](/bigquery/docs/biglake-intro#metadata_caching_for_performance) for query performance\n - [Data loss prevention](/bigquery/docs/scan-with-dlp)\n - [Column-level access control](/bigquery/docs/column-level-security-intro)\n - [Dynamic data masking](/bigquery/docs/column-data-masking-intro) for security and governance at scale.\n\nFeatures\n\nYou can use the Hive-BigQuery connector to work with your\nBigQuery data and accomplish the following tasks:\n\n- Run queries with MapReduce and Tez execution engines.\n- Create and delete BigQuery tables from Hive.\n- Join BigQuery and BigLake tables with Hive tables.\n- Perform fast reads from BigQuery tables using the [Storage Read API](/bigquery/docs/reference/storage) streams and the [Apache Arrow](https://arrow.apache.org/) format\n- Write data to BigQuery using the following methods:\n - Direct writes using the BigQuery [Storage Write API in pending mode](/bigquery/docs/write-api-batch). Use this method for workloads that require low write latency, such as near-real-time dashboards with short refresh time windows.\n - Indirect writes by staging temporary Avro files to Cloud Storage, and then loading the files into a destination table using the [Load Job API](/bigquery/docs/batch-loading-data). This method is less expensive than the direct method, since BigQuery load jobs don't accrue charges. Since this method is slower, and finds its best use in workloads that aren't time critical\n- Access BigQuery [time-partitioned](/bigquery/docs/partitioned-tables)\n and [clustered](/bigquery/docs/clustered-tables) tables. The following example\n defines the relation between a Hive table and a table\n that is partitioned and clustered in BigQuery.\n\n ```sql\n CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP)\n STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler'\n TBLPROPERTIES (\n 'bq.table'='myproject.mydataset.mytable',\n 'bq.time.partition.field'='ts',\n 'bq.time.partition.type'='MONTH',\n 'bq.clustered.fields'='int_val,text'\n );\n ```\n- Prune columns to avoid retrieving unnecessary columns from the data layer.\n\n- Use predicate pushdowns to pre-filter data rows at the BigQuery storage\n layer. This technique can significantly improve overall query performance by\n reducing the amount of data traversing the network.\n\n- Automatically convert Hive data types to BigQuery data types.\n\n- Read BigQuery [views](/bigquery/docs/views-intro) and\n [table snapshots](/bigquery/docs/table-snapshots-intro).\n\n- Integrate with Spark SQL.\n\n- Integrate with Apache Pig and HCatalog.\n\nGet started\n\nSee the instructions to\n[install and configure the Hive-BigQuery connector on a Hive cluster](https://github.com/GoogleCloudDataproc/hive-bigquery-connector/blob/main/README.md)."]]