Gli snapshot di Dataflow salvano lo stato di una pipeline di streaming, consentendoti di avviare una nuova versione del job Dataflow senza perdere lo stato. Gli snapshot sono utili per backup e ripristino, test e rollback di aggiornamenti di pipeline di streaming e altri scenari simili.
Puoi creare uno snapshot Dataflow di qualsiasi job di streaming in esecuzione. Tieni presente che qualsiasi nuovo job creato da uno snapshot utilizza Streaming Engine. Puoi anche utilizzare uno snapshot Dataflow per eseguire la migrazione della pipeline esistente a Streaming Engine, che è più efficiente e scalabile, con tempi di inattività minimi.
Questa guida spiega come creare snapshot, gestirli e creare job a partire dagli snapshot.
Prima di iniziare
- Sign in to your Google Cloud Platform account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Nella console Google Cloud , vai alla pagina Job di Dataflow.
Viene visualizzato un elenco di job Dataflow insieme al relativo stato. Se non vedi alcun job in modalità flusso, devi eseguirne uno nuovo. Per un esempio di job di streaming, vedi la Guida rapida all'utilizzo dei modelli.
- Seleziona un lavoro.
- Nella barra dei menu della pagina Dettagli job, fai clic su Crea snapshot.
- Nella finestra di dialogo Crea uno snapshot, seleziona una delle seguenti
opzioni:
- Senza origini dati: seleziona questa opzione per creare uno snapshot solo dello stato del job Dataflow.
- Con origini dati: seleziona questa opzione per creare uno snapshot sia dello stato del job Dataflow sia dell'origine Pub/Sub.
- Fai clic su Crea.
JOB_ID: l'ID del job di streamingDURATION: il periodo di tempo (in giorni) prima della scadenza dello snapshot, dopo il quale non è più possibile creare job dallo snapshot. Il flagsnapshot-ttlè facoltativo, quindi se non viene specificato, lo snapshot scade dopo 7 giorni. Specifica il valore nel seguente formato:5d. La durata massima che puoi specificare è di 30 giorni (30d).REGION: la regione in cui viene eseguito il job di streaming- Gli snapshot Dataflow comportano un addebito per l'utilizzo del disco.
- Gli snapshot vengono creati nella stessa regione del job.
- Se la posizione del worker del job è diversa dalla regione del job, la creazione dello snapshot non va a buon fine. Consulta la guida alle regioni Dataflow.
- Puoi acquisire snapshot di job non Streaming Engine solo se i job sono stati avviati o aggiornati dopo il 1° febbraio 2021.
- Gli snapshot Pub/Sub creati con gli snapshot Dataflow sono gestiti dal servizio Pub/Sub e comportano un addebito.
- Uno snapshot Pub/Sub scade al massimo 7 giorni dopo la sua creazione. La sua durata esatta viene determinata al momento della creazione dal
backlog esistente nell'abbonamento di origine. Nello specifico, la durata dello snapshot Pub/Sub è
7 days - (age of oldest unacked message in the subscription). Prendiamo ad esempio un abbonamento il cui messaggio non confermato più vecchio ha 3 giorni. Se da questo abbonamento viene creato uno snapshot Pub/Sub, lo snapshot, che acquisisce sempre questo backlog di 3 giorni finché esiste, scade dopo 4 giorni. Consulta il riferimento allo snapshot Pub/Sub. - Durante l'operazione di snapshot, il job Dataflow viene messo in pausa e riprende dopo che lo snapshot è pronto. Il tempo necessario dipende dalle dimensioni dello stato della pipeline. Ad esempio, il tempo necessario per creare snapshot nei job di Streaming Engine è generalmente inferiore rispetto ai job non Streaming Engine.
- Puoi annullare il job mentre è in corso uno snapshot, che viene quindi annullato.
- Non puoi aggiornare o svuotare il job mentre è in corso uno snapshot. Devi attendere che il job venga ripristinato dal processo di snapshot prima di poterlo aggiornare o svuotare.
- Nella console Google Cloud , vai alla pagina Snapshot di Dataflow.
- Seleziona lo snapshot e fai clic su Elimina.
- Nella finestra di dialogo Elimina snapshot, fai clic su Elimina per confermare.
SNAPSHOT_ID: l'ID snapshotREGION: la regione in cui esiste lo snapshot- Nella shell o nel terminale, crea un nuovo job da uno snapshot. Ad esempio:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=MAIN_CLASS \ -Dexec.args="--project=PROJECT_ID \ --stagingLocation=gs://STORAGE_BUCKET/staging/ \ --inputFile=gs://apache-beam-samples/shakespeare/* \ --output=gs://STORAGE_BUCKET/output \ --runner=DataflowRunner \ --enableStreamingEngine \ --createFromSnapshot=SNAPSHOT_ID \ --region=REGION"
Sostituisci quanto segue:
MAIN_CLASSoMODULE: Per le pipeline Java, la posizione della classe principale che contiene il codice della pipeline. Per le pipeline Python, la posizione del modulo che contiene il codice della pipeline. Ad esempio, quando utilizzi l'esempio Wordcount, il valore èorg.apache.beam.examples.WordCount.PROJECT_ID: il tuo ID progetto Google CloudSTORAGE_BUCKET: il bucket Cloud Storage che utilizzi per gli asset temporanei del job e l'output finaleSNAPSHOT_ID: l'ID dello snapshot da cui vuoi creare un nuovo job.REGION: la località in cui vuoi eseguire il nuovo job Dataflow.
- Nella shell o nel terminale, crea un nuovo job da uno snapshot. Ad esempio:
python -m MODULE \ --project PROJECT_ID \ --temp_location gs://STORAGE_BUCKET/tmp/ \ --input gs://apache-beam-samples/shakespeare/* \ --output gs://STORAGE_BUCKET/output \ --runner DataflowRunner \ --enable_streaming_engine \ --create_from_snapshot=SNAPSHOT_ID \ --region REGION \ --streaming
Sostituisci quanto segue:
MAIN_CLASSoMODULE: Per le pipeline Java, la posizione della classe principale che contiene il codice della pipeline. Per le pipeline Python, la posizione del modulo che contiene il codice della pipeline. Ad esempio, quando utilizzi l'esempio Wordcount, il valore èorg.apache.beam.examples.WordCount.PROJECT_ID: il tuo ID progetto Google CloudSTORAGE_BUCKET: il bucket Cloud Storage che utilizzi per gli asset temporanei del job e l'output finaleSNAPSHOT_ID: l'ID dello snapshot da cui vuoi creare un nuovo job.REGION: la località in cui vuoi eseguire il nuovo job Dataflow.
- I job creati dagli snapshot devono essere eseguiti nella stessa regione in cui è archiviato lo snapshot.
Se uno snapshot Dataflow include snapshot di origini Pub/Sub, i job creati da uno snapshot Dataflow
seekautomaticamente a questi snapshot Pub/Sub come origini. Quando crei job dallo snapshot Dataflow, devi specificare gli stessi argomenti Pub/Sub utilizzati dal job di origine.Se uno snapshot Dataflow non include snapshot delle origini Pub/Sub e il job di origine utilizza un'origine Pub/Sub, devi specificare un argomento Pub/Sub quando crei job da questo snapshot Dataflow.
I nuovi job creati da uno snapshot sono comunque soggetti a un controllo di compatibilità degli aggiornamenti.
- Non puoi creare job dagli snapshot utilizzando i modelli o l'editor Dataflow SQL.
- Non puoi aggiornare o svuotare un job mentre è in corso un'istantanea. Devi attendere che il job sia ripreso dalla procedura di snapshot prima di poterlo aggiornare o svuotare.
- Il periodo di scadenza dello snapshot può essere impostato solo tramite Google Cloud CLI.
- Gli snapshot sink non sono supportati. Ad esempio, non puoi creare uno snapshot BigQuery quando crei uno snapshot Dataflow.
Crea uno snapshot
Console
gcloud
Crea uno snapshot:
gcloud dataflow snapshots create \
--job-id=JOB_ID \
--snapshot-ttl=DURATION \
--snapshot-sources=true \
--region=REGIONSostituisci quanto segue:
Il flag snapshot-sources specifica se creare uno snapshot delle
origini Pub/Sub insieme allo snapshot
Dataflow. Se true, le origini Pub/Sub vengono
acquisite automaticamente e gli ID snapshot Pub/Sub vengono
mostrati nella risposta di output. Dopo aver eseguito il comando
create, controlla lo stato dello snapshot eseguendo il comando
list
o
describe.
Quando crei snapshot Dataflow, si applicano le seguenti regole:
Utilizzare la pagina degli snapshot
Dopo aver creato uno snapshot, puoi utilizzare la pagina Snapshot nella console Google Cloud per visualizzare e gestire gli snapshot del tuo progetto.
Se fai clic su uno snapshot, si apre la pagina Dettagli snapshot. Puoi visualizzare metadati aggiuntivi sullo snapshot, nonché un link al job di origine e a eventuali snapshot Pub/Sub.
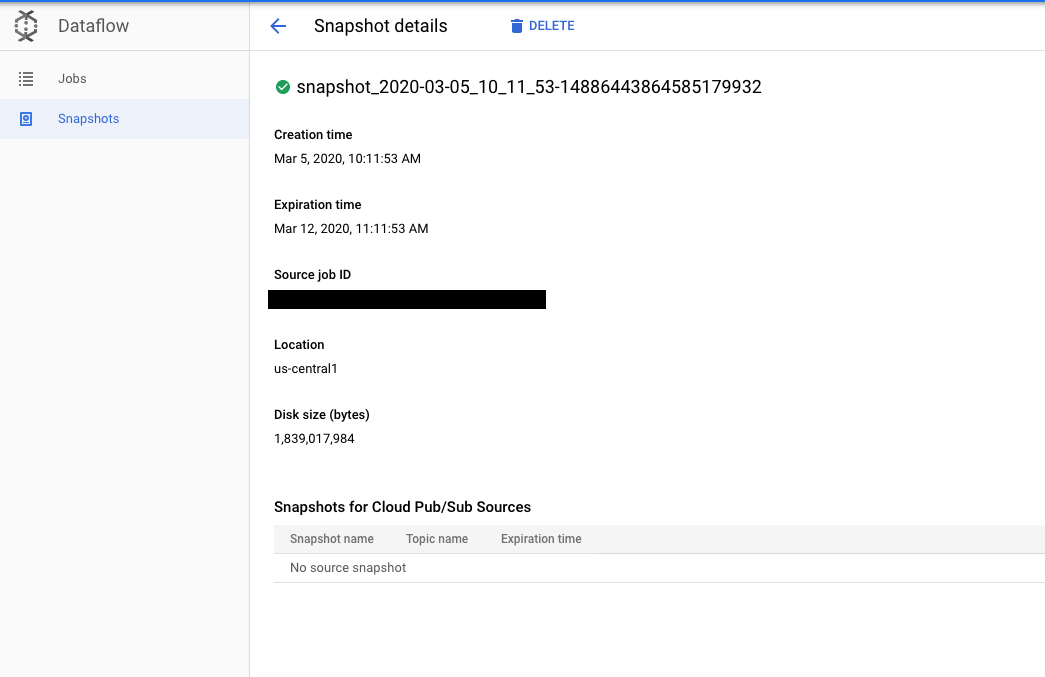
Elimina uno snapshot
L'eliminazione di uno snapshot è un modo per interrompere il processo di snapshot e riprendere il job. Inoltre, l'eliminazione degli snapshot Dataflow non comporta l'eliminazione automatica degli snapshot Pub/Sub associati.
Console
gcloud
Elimina uno snapshot:
gcloud dataflow snapshots delete SNAPSHOT_ID \
--region=REGIONSostituisci quanto segue:
Per ulteriori informazioni, consulta il
delete
riferimento dei comandi.
Crea un job da uno snapshot
Dopo aver creato uno snapshot, puoi ripristinare lo stato del job Dataflow creando un nuovo job da quello snapshot.
Java
Per creare un nuovo job da uno snapshot, utilizza i flag
--createFromSnapshot e --enableStreamingEngine.
Python
Gli snapshot Dataflow richiedono l'SDK Apache Beam per Python, versione 2.29.0 o successive.
Per creare un nuovo job da uno snapshot, utilizza i flag
--createFromSnapshot e --enableStreamingEngine.
Quando crei job dagli snapshot Dataflow, si applicano le seguenti condizioni:
Limitazioni note
Ai snapshot di Dataflow si applicano le seguenti limitazioni:
Risoluzione dei problemi
Questa sezione fornisce istruzioni per la risoluzione dei problemi comuni riscontrati durante l'interazione con gli snapshot Dataflow.
Prima di contattare l'assistenza, assicurati di aver escluso i problemi relativi alle limitazioni note e nelle seguenti sezioni per la risoluzione dei problemi.
La richiesta di creazione dello snapshot viene rifiutata
Dopo l'invio di una richiesta di creazione dello snapshot, dalla consoleGoogle Cloud o da gcloud CLI, il servizio Dataflow esegue un controllo delle precondizioni e restituisce eventuali messaggi di errore. La richiesta di creazione dello snapshot può essere rifiutata per vari motivi specificati nei messaggi di errore, ad esempio se un tipo di job non è supportato o una regione non è disponibile.
Se la richiesta viene rifiutata perché il job è troppo vecchio, devi aggiornarlo prima di richiedere un'istantanea.
Creazione dello snapshot non riuscita
La creazione di snapshot potrebbe non riuscire per diversi motivi. Ad esempio, il job di origine è stato annullato o il progetto non dispone delle autorizzazioni corrette per creare snapshot Pub/Sub. I log job-message del job contengono messaggi di errore relativi alla creazione dello snapshot. Se la creazione dello snapshot non va a buon fine, il job di origine riprende.
Creazione del job dallo snapshot non riuscita
Quando crei un job da uno snapshot, assicurati che lo snapshot esista e non sia scaduto. Il nuovo job deve essere eseguito su Streaming Engine.
Per i problemi comuni di creazione dei job, consulta la guida alla risoluzione dei problemi di Dataflow. In particolare, i nuovi job creati dagli snapshot sono soggetti a un controllo di compatibilità degli aggiornamenti in cui il nuovo job deve essere compatibile con il job di origine di cui è stato creato lo snapshot.
Il job creato dallo snapshot fa pochi progressi
I log job-message del job contengono messaggi di errore per la creazione del job. Ad esempio, potresti notare che il job non riesce a trovare gli snapshot Pub/Sub. In questo caso, verifica che gli snapshot Pub/Sub esistano e non siano scaduti. Gli snapshot Pub/Sub scadono non appena il messaggio più vecchio di uno snapshot ha più di sette giorni. Gli snapshot Pub/Sub scaduti potrebbero essere rimossi automaticamente dal servizio Pub/Sub.
Per i job creati da snapshot Dataflow che includono snapshot dell'origine Pub/Sub, il nuovo job potrebbe avere backlog Pub/Sub di grandi dimensioni da elaborare. Lo scaling automatico dello streaming potrebbe aiutare il nuovo job a eliminare il backlog più rapidamente.
Il job di origine di cui è stato creato lo snapshot potrebbe già essere in uno stato non integro prima che sia stato creato lo snapshot. Capire perché il job di origine non è integro potrebbe aiutarti a risolvere i problemi del nuovo job. Per suggerimenti comuni per il debug dei job, consulta la guida alla risoluzione dei problemi di Dataflow.