Halaman ini memberikan tips pemecahan masalah dan strategi debug yang mungkin berguna jika Anda mengalami masalah saat membangun atau menjalankan pipeline Dataflow. Informasi ini dapat membantu Anda mendeteksi kegagalan pipeline, menentukan alasan di balik kegagalan menjalankan pipeline, dan menyarankan beberapa tindakan untuk memperbaiki masalah.
Diagram berikut menunjukkan alur kerja pemecahan masalah Dataflow yang dijelaskan di halaman ini.

Dataflow memberikan masukan real-time tentang tugas Anda, dan ada serangkaian langkah dasar yang dapat Anda gunakan untuk memeriksa pesan error, log, dan kondisi seperti progres tugas Anda yang terhenti.
Untuk mendapatkan panduan tentang error umum yang mungkin Anda temui saat menjalankan job Dataflow, lihat Memecahkan masalah error Dataflow. Untuk memantau dan memecahkan masalah performa pipeline, lihat Memantau performa pipeline.
Praktik terbaik untuk pipeline
Berikut adalah praktik terbaik untuk pipeline Java, Python, dan Go.
Java
Untuk tugas batch, sebaiknya tetapkan time to live (TTL) untuk lokasi sementara.
Sebelum menyiapkan TTL dan sebagai praktik terbaik umum, pastikan Anda menyetel lokasi penyiapan dan lokasi sementara ke lokasi yang berbeda.
Jangan hapus objek di lokasi penyiapan karena objek ini akan digunakan kembali.
Jika tugas selesai atau dihentikan dan objek sementara tidak dibersihkan, hapus file ini secara manual dari bucket Cloud Storage yang digunakan sebagai lokasi sementara.
Python
Lokasi sementara dan penyiapan memiliki awalan <job_name>.<time>.
Pastikan Anda menetapkan lokasi sementara dan lokasi sementara ke lokasi yang berbeda.
Jika diperlukan, hapus objek di lokasi penahapan setelah tugas selesai atau berhenti. Selain itu, objek bertahap tidak digunakan kembali dalam pipeline Python.
Jika tugas berakhir dan objek sementara tidak dibersihkan, hapus file ini secara manual dari bucket Cloud Storage yang digunakan sebagai lokasi sementara.
Untuk tugas batch, sebaiknya tetapkan time to live (TTL) untuk lokasi sementara dan penyiapan.
Go
Lokasi sementara dan penyiapan memiliki awalan
<job_name>.<time>.Pastikan Anda menetapkan lokasi sementara dan lokasi sementara ke lokasi yang berbeda.
Jika diperlukan, hapus objek di lokasi penahapan setelah tugas selesai atau berhenti. Selain itu, objek bertahap tidak digunakan kembali di pipeline Go.
Jika tugas berakhir dan objek sementara tidak dibersihkan, hapus file ini secara manual dari bucket Cloud Storage yang digunakan sebagai lokasi sementara.
Untuk tugas batch, sebaiknya tetapkan time to live (TTL) untuk lokasi sementara dan penyiapan.
Memeriksa status pipeline
Anda dapat mendeteksi error dalam eksekusi pipeline menggunakan antarmuka pemantauan Dataflow.
- Buka Google Cloud console.
- Pilih project Google Cloud Platform Anda dari daftar project.
- Di menu navigasi, di bagian Big Data, klik Dataflow. Daftar tugas yang sedang berjalan akan muncul di panel sebelah kanan.
- Pilih tugas pipeline yang ingin Anda lihat. Anda dapat melihat status tugas secara sekilas di kolom Status: "Sedang berjalan", "Berhasil", atau "Gagal".
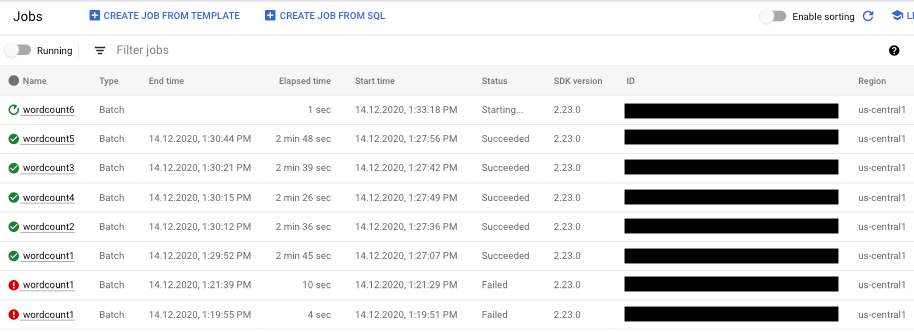
Menemukan informasi tentang kegagalan pipeline
Jika salah satu tugas pipeline gagal, Anda dapat memilih tugas untuk melihat informasi yang lebih mendetail tentang error dan hasil yang dijalankan. Saat memilih tugas, Anda dapat melihat diagram utama untuk pipeline, grafik eksekusi, panel Info tugas, dan panel Log dengan tab Log tugas, Log pekerja, Diagnostik, dan Rekomendasi.
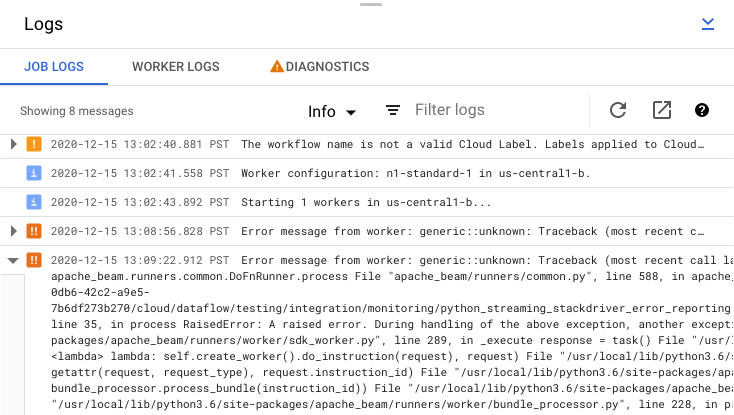
Memeriksa pesan error tugas
Untuk melihat Log Tugas yang dihasilkan oleh kode pipeline dan layanan Dataflow, di panel Log, klik segmentTampilkan.
Anda dapat memfilter pesan yang muncul di Log tugas dengan mengklik Infoarrow_drop_down dan filter_listFilter. Untuk hanya menampilkan pesan error, klik Infoarrow_drop_down, lalu pilih Error.
Untuk meluaskan pesan error, klik bagian yang dapat diluaskan arrow_right.
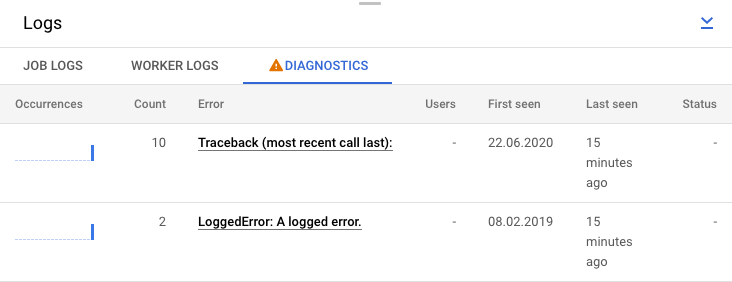
Atau, Anda dapat mengklik tab Diagnostik. Tab ini menunjukkan tempat terjadinya error di sepanjang linimasa yang dipilih, jumlah semua error yang dicatat, dan kemungkinan rekomendasi untuk pipeline Anda.
Melihat log langkah untuk tugas Anda
Saat Anda memilih langkah dalam grafik pipeline, panel log akan beralih dari menampilkan Log Tugas yang dihasilkan oleh layanan Dataflow ke menampilkan log dari instance Compute Engine yang menjalankan langkah pipeline Anda.
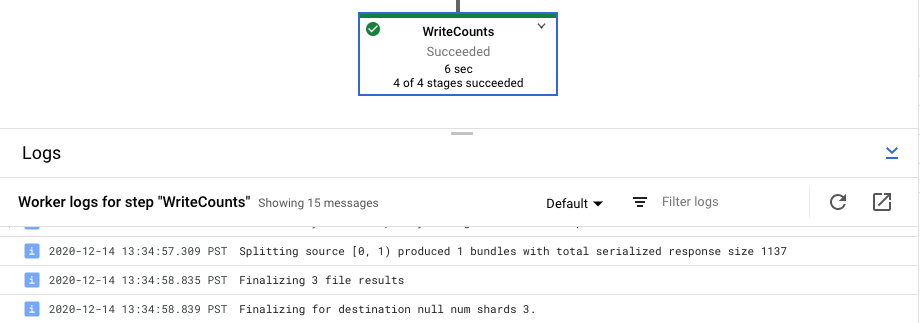
Cloud Logging menggabungkan semua log yang dikumpulkan dari instance Compute Engine project Anda di satu lokasi. Lihat Mencatat pesan pipeline untuk mengetahui informasi selengkapnya tentang penggunaan berbagai kemampuan logging Dataflow.
Menangani penolakan pipeline otomatis
Dalam beberapa kasus, layanan Dataflow mengidentifikasi bahwa pipeline Anda mungkin memicu masalah SDK yang diketahui. Untuk mencegah pengiriman pipeline yang kemungkinan akan mengalami masalah, Dataflow akan otomatis menolak pipeline Anda dan menampilkan pesan berikut:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Setelah membaca peringatan dalam detail bug yang ditautkan, jika Anda ingin mencoba menjalankan pipeline, Anda dapat mengganti penolakan otomatis. Tambahkan tanda
--experiments=<override-flag> dan kirim ulang pipeline Anda.
Menentukan penyebab kegagalan pipeline
Biasanya, eksekusi pipeline Apache Beam yang gagal dapat disebabkan oleh salah satu penyebab berikut:
- Error pembuatan grafik atau pipeline. Error ini terjadi saat Dataflow mengalami masalah saat membuat grafik langkah-langkah yang membentuk pipeline Anda, seperti yang dijelaskan oleh pipeline Apache Beam Anda.
- Error dalam validasi tugas. Layanan Dataflow memvalidasi tugas pipeline yang Anda luncurkan. Error dalam proses validasi dapat mencegah tugas Anda berhasil dibuat atau dijalankan. Error validasi dapat mencakup masalah pada bucket Cloud Storage project Anda, atau pada izin project Anda. Google Cloud
- Pengecualian dalam kode pekerja. Error ini terjadi saat ada error atau bug dalam kode yang disediakan pengguna yang didistribusikan Dataflow ke pekerja paralel, seperti instance
DoFndari transformasiParDo. - Error yang disebabkan oleh kegagalan sementara di layanan Google Cloud lain. Pipeline Anda mungkin gagal karena gangguan sementara atau masalah lain di Google Cloud layanan yang menjadi dependensi Dataflow, seperti Compute Engine atau Cloud Storage.
Mendeteksi error pembuatan grafik atau pipeline
Error pembuatan grafik dapat terjadi saat Dataflow membuat grafik eksekusi untuk pipeline Anda dari kode dalam program Dataflow Anda. Selama waktu konstruksi grafik, Dataflow memeriksa operasi ilegal.
Jika Dataflow mendeteksi error dalam pembuatan grafik, perlu diingat bahwa tidak ada tugas yang dibuat di layanan Dataflow. Oleh karena itu, Anda tidak akan melihat masukan apa pun di antarmuka pemantauan Dataflow. Sebagai gantinya, pesan error yang mirip dengan berikut akan muncul di konsol atau jendela terminal tempat Anda menjalankan pipeline Apache Beam:
Java
Misalnya, jika pipeline Anda mencoba melakukan agregasi seperti
GroupByKey pada PCollection tanpa batas yang tidak dipicu dan memiliki jendela global,
pesan error yang mirip dengan berikut akan muncul:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Misalnya, jika pipeline Anda menggunakan petunjuk jenis dan jenis argumen di salah satu transformasi tidak sesuai yang diharapkan, pesan error yang mirip dengan berikut akan terjadi:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
Misalnya, jika pipeline Anda menggunakan `DoFn` yang tidak menerima input apa pun, pesan error yang mirip dengan berikut akan muncul:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Jika Anda mengalami error seperti itu, periksa kode pipeline untuk memastikan bahwa operasi pipeline Anda sah.
Mendeteksi error dalam validasi tugas Dataflow
Setelah layanan Dataflow menerima grafik pipeline Anda, layanan tersebut akan mencoba memvalidasi tugas Anda. Validasi ini mencakup hal berikut:
- Memastikan layanan dapat mengakses bucket Cloud Storage terkait tugas Anda untuk penyiapan file dan output sementara.
- Memeriksa izin yang diperlukan di Google Cloud project Anda.
- Memastikan layanan dapat mengakses sumber input dan output, seperti file.
Jika tugas Anda gagal dalam proses validasi, pesan error akan muncul di antarmuka pemantauan Dataflow, serta di konsol atau jendela terminal jika Anda menggunakan eksekusi pemblokiran. Pesan error terlihat mirip dengan yang berikut ini:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
Validasi tugas yang dijelaskan di bagian ini saat ini tidak didukung untuk Go. Error karena masalah ini muncul sebagai pengecualian pekerja.
Mendeteksi pengecualian dalam kode pekerja
Saat tugas Anda berjalan, Anda mungkin mengalami error atau pengecualian dalam kode pekerja. Error ini umumnya berarti bahwa DoFn dalam kode pipeline Anda telah menghasilkan pengecualian yang tidak tertangani, yang mengakibatkan tugas gagal dalam tugas Dataflow Anda.
Pengecualian dalam kode pengguna (misalnya, instance DoFn Anda) dilaporkan di
antarmuka pemantauan Dataflow.
Jika Anda menjalankan pipeline dengan eksekusi pemblokiran, pesan error akan dicetak di jendela konsol atau terminal, seperti berikut:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Pertimbangkan untuk mencegah terjadinya error dalam kode Anda dengan menambahkan pengendali pengecualian. Misalnya, jika Anda ingin menghilangkan elemen yang gagal dalam beberapa validasi input kustom yang dilakukan di ParDo, tangani pengecualian dalam DoFn dan hilangkan elemen tersebut.
Anda juga dapat melacak elemen yang gagal dengan beberapa cara:
- Anda dapat mencatat elemen yang gagal dan memeriksa output menggunakan Cloud Logging.
- Anda dapat memeriksa log startup pekerja dan pekerja Dataflow untuk melihat peringatan atau error dengan mengikuti petunjuk di Melihat log.
- Anda dapat meminta
ParDomenulis elemen yang gagal ke output tambahan untuk diperiksa nanti.
Untuk melacak properti pipeline yang sedang berjalan, Anda dapat menggunakan class Metrics,
seperti yang ditunjukkan dalam contoh berikut:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Memecahkan masalah pipeline yang berjalan lambat atau tidak ada output
Lihat halaman berikut:
- Memecahkan masalah tugas streaming yang lambat atau macet.
- Memecahkan masalah tugas batch yang lambat atau macet.
Error umum dan langkah-langkah yang harus dilakukan
Jika Anda mengetahui error yang menyebabkan kegagalan pipeline, lihat halaman Memecahkan masalah error Dataflow untuk mendapatkan panduan pemecahan masalah error.