Nell'interfaccia di monitoraggio di Dataflow, il riquadro Informazioni passaggio mostra informazioni sui singoli passaggi di un job. Un passaggio rappresenta una singola trasformazione nella pipeline. Le trasformazioni composite contengono passaggi secondari.
Il riquadro Informazioni sul passaggio mostra le seguenti informazioni:
- Metriche per il passaggio.
- Informazioni sulle raccolte di input e output del passaggio.
- Quali fasi corrispondono a questo passaggio.
- Metriche di input secondario
Utilizza il riquadro Informazioni passaggio per capire il rendimento del job in ogni passaggio e per trovare i passaggi che possono essere potenzialmente ottimizzati.
Visualizzare le informazioni sul passo
Per visualizzare le informazioni sui passi, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Dataflow > Job.
Seleziona un lavoro.
Fai clic sulla scheda Grafico del job per visualizzare il grafico del job. Il grafico del job rappresenta ogni passaggio della pipeline come una casella.
Fai clic su un passaggio. Le informazioni sul passaggio vengono visualizzate nel riquadro Informazioni passaggio.
Per visualizzare i passaggi secondari di una trasformazione composita, fai clic sulla freccia Espandi nodo.
Metriche dei passi
Il riquadro Informazioni passaggio mostra le seguenti metriche per il passaggio.
Filigrana sistema e ritardo
La filigrana di sistema è il timestamp più recente per il quale tutti gli orari degli eventi sono stati elaborati completamente. Il ritardo della filigrana di sistema è il tempo massimo di attesa per l'elaborazione di un elemento di dati.
Livello dati e ritardo
La filigrana dei dati è il timestamp che indica il tempo di completamento stimato dell'input di dati per questo passaggio. Il ritardo del watermark dei dati è la differenza tra l'ora dell'ultimo evento di input e il watermark dei dati.
Tempo totale di esecuzione
Il tempo reale è il tempo totale approssimativo trascorso in tutti i thread di tutti i worker per le seguenti azioni:
- Inizializzazione del passaggio
- Elaborazione dei dati
- Rimescolamento dei dati
- Terminare il passaggio
Per i passaggi compositi, tempo totale di esecuzione è uguale alla somma del tempo trascorso nei passaggi componenti.
Il tempo reale può aiutarti a identificare i passaggi lenti e a diagnosticare quale parte della pipeline richiede più tempo del necessario.
Stato collo di bottiglia
Se Dataflow rileva un collo di bottiglia, viene visualizzato un avviso insieme alla causa, se nota. Per saperne di più, vedi Risolvere i problemi relativi ai colli di bottiglia.
Latenza massima operazione
La latenza massima operazione è il tempo massimo impiegato in questo passaggio per elaborare i messaggi in entrata o le scadenze delle finestre. Questa metrica viene misurata in modo aggregato tra i passaggi raggruppati in una singola fase, perciò il valore rappresenta l'intera fase.
Parallelismo delle chiavi
Il parallelismo delle chiavi è il numero approssimativo di chiavi in uso per l'elaborazione dei dati in questo passaggio.
Raccolte di input/output
Il riquadro Informazioni passaggio mostra le seguenti informazioni su ciascuna delle raccolte di input e output nel passaggio:
Grafico della velocità effettiva. Questo grafico mostra il throughput per la raccolta. Puoi visualizzare il grafico come elementi al secondo o come byte al secondo. Per ulteriori informazioni su questa metrica, consulta Throughput.
Conteggio degli elementi aggiunti alla raccolta.
Dimensioni stimate della raccolta, in byte.
Fasi ottimizzate
Una fase rappresenta una singola unità di lavoro eseguita da Dataflow. Quando selezioni un passaggio nel grafico del job, il riquadro Informazioni passaggio mostra i nomi delle fasi che eseguono questo passaggio, insieme allo stato attuale, ad esempio in esecuzione, interrotto o riuscito.
Per visualizzare maggiori informazioni sulle fasi del job, utilizza la scheda Dettagli esecuzione.
Metriche di input secondario
Un input aggiuntivo è un input aggiuntivo a cui una trasformazione può accedere ogni volta che elabora un elemento. Se una trasformazione crea o utilizza un input secondario, il riquadro Informazioni secondarie mostra le metriche per la raccolta di input secondari.
Se una trasformazione composita crea o utilizza un input laterale, espandi la trasformazione composita finché non vedi la trasformazione secondaria specifica che crea o utilizza l'input laterale. Seleziona la trasformazione secondaria per visualizzare le metriche di input laterale.
Trasformazioni che creano un input aggiuntivo
Se una trasformazione crea una raccolta di input secondari, la sezione Metriche input secondari mostra il nome della raccolta, insieme alle seguenti metriche:
- Tempo trascorso in scrittura: il tempo trascorso a scrivere la raccolta di input secondari.
- Byte scritti:il numero totale di byte scritti nella raccolta di input secondari.
- Ora e byte letti dall'input secondario:una tabella che contiene metriche aggiuntive per tutte le trasformazioni che utilizzano la raccolta di input secondari, chiamate consumer di input secondari.
La tabella Ora e byte letti dall'input secondario contiene le seguenti informazioni per ogni consumer di input secondario:
- Consumer input secondario: il nome della trasformazione del consumer input secondario.
- Tempo trascorso a leggere:il tempo trascorso da questo consumatore a leggere la raccolta di input secondari.
- Byte letti:il numero di byte letti da questo consumer dalla raccolta di input secondari.
L'immagine seguente mostra le metriche di input laterale per una trasformazione che crea una raccolta di input laterali:
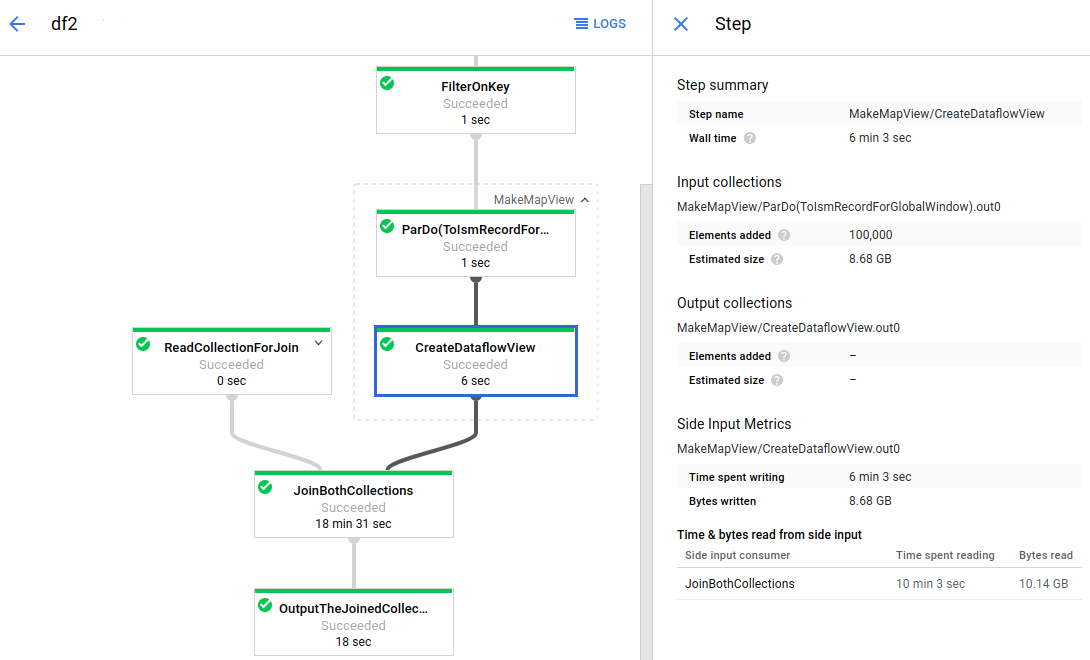
Il grafico del job ha una trasformazione composita espansa (MakeMapView). Viene selezionata la
trasformazione secondaria che crea l'input secondario (CreateDataflowView) e
le metriche dell'input secondario sono visibili nel riquadro Informazioni passaggio.
Trasformazioni che utilizzano input aggiuntivi
Se una trasformazione utilizza uno o più input secondari, la sezione Metriche input secondari mostra la tabella Ora e byte letti dall'input secondario. Questa tabella contiene le seguenti informazioni per ogni raccolta di input secondari:
- Raccolta input secondario:il nome della raccolta input secondario.
- Tempo trascorso a leggere:il tempo trascorso dalla trasformazione a leggere questa raccolta di input secondari.
- Byte letti:il numero di byte letti dalla trasformazione da questa raccolta di input secondari.
L'immagine seguente mostra le metriche di input laterale per una trasformazione che legge da una raccolta di input laterali.
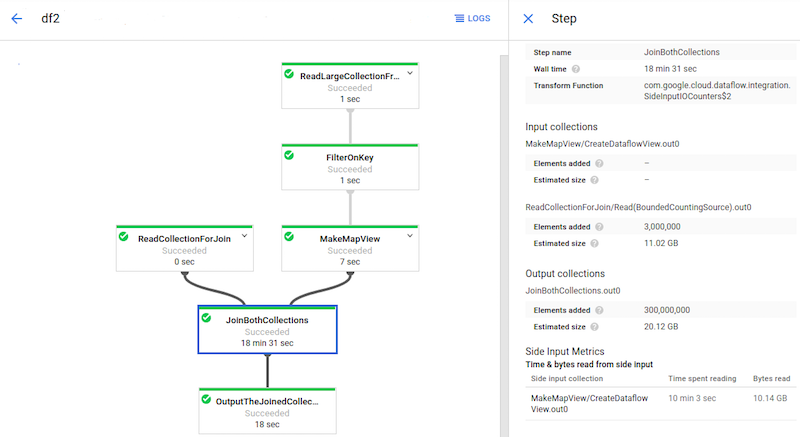
La trasformazione JoinBothCollections legge da una raccolta di input secondari.
JoinBothCollections è selezionato nel grafico del job e le metriche di input laterali
sono visibili nel riquadro Informazioni passaggio.
Identifica i problemi di prestazioni dell'input secondario
Gli input aggiuntivi possono influire sul rendimento della pipeline. Quando la pipeline utilizza un input aggiuntivo, Dataflow scrive la raccolta in un livello persistente, ad esempio un disco, e le trasformazioni leggono da questa raccolta persistente. Queste letture e scritture influiscono sulla durata di esecuzione del job.
La reiterazione è un problema comune di prestazioni dell'input secondario. Se l'input laterale
PCollection è troppo grande, i worker non possono memorizzare nella cache l'intera raccolta.
Di conseguenza, i worker devono leggere ripetutamente la raccolta di input laterali persistenti.
Nell'immagine seguente, le metriche di input laterale mostrano che i byte totali letti dalla raccolta di input laterale sono molto maggiori della dimensione della raccolta, che viene visualizzata come byte totali scritti. La raccolta di input laterali è di 563 MB e la somma dei byte letti dalle trasformazioni di consumo è quasi 12 GB.
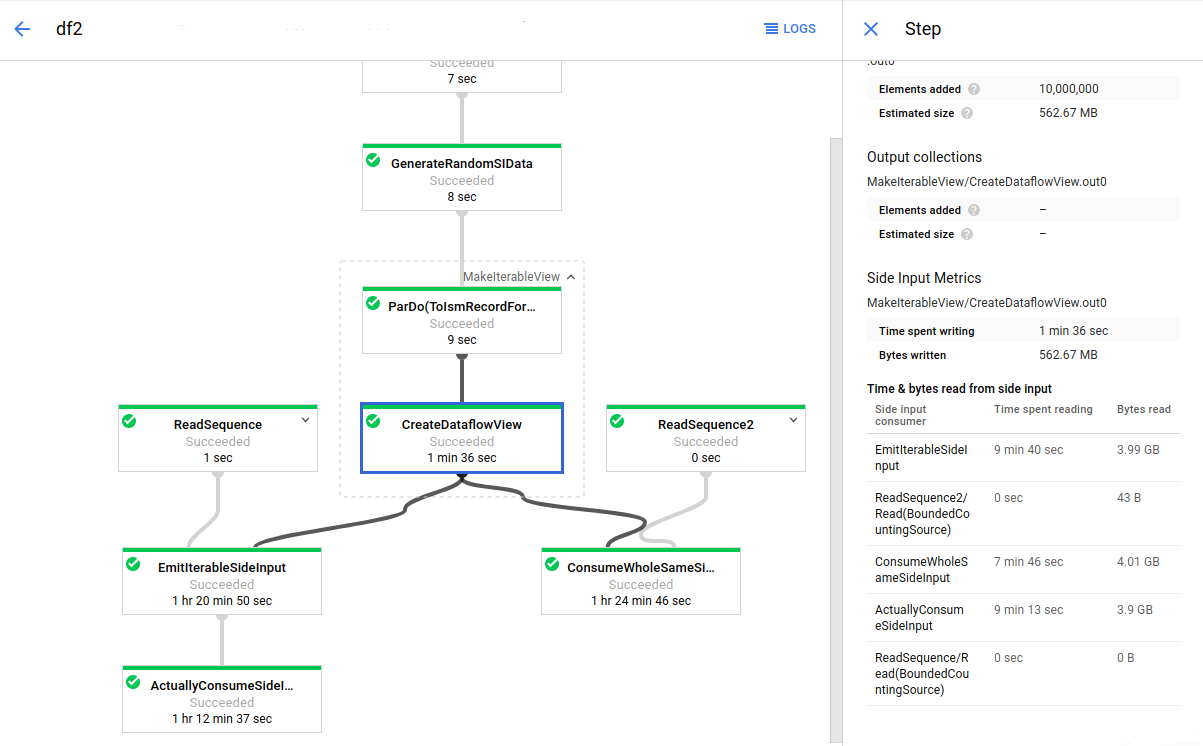
Per migliorare il rendimento di questa pipeline, riprogetta l'algoritmo per evitare di iterare o recuperare nuovamente i dati di input secondari. In questo esempio, la pipeline crea il prodotto cartesiano di due raccolte. L'algoritmo esegue l'iterazione nell'intera raccolta di input secondari per ogni elemento della raccolta principale. Puoi migliorare il pattern di accesso della pipeline raggruppando più elementi della raccolta principale. Questa modifica riduce il numero di volte in cui i worker devono rileggere la raccolta di input secondari.
Un altro problema di rendimento comune può verificarsi se la pipeline esegue un'unione
applicando un ParDo con uno o più input secondari di grandi dimensioni. In questo caso, i worker
trascorrono una percentuale elevata del tempo di elaborazione dell'operazione di join leggendo
dalle raccolte di input secondari.
L'immagine seguente mostra le metriche di input laterale per questo problema:
La trasformazione JoinBothCollections ha un tempo di elaborazione totale superiore a 18 minuti. I worker trascorrono la maggior parte del tempo di elaborazione (10 minuti) leggendo
dalla raccolta di input laterali da 10 GB. Per migliorare il rendimento di questa
pipeline, utilizza
CoGroupByKey
anziché gli input secondari.