ジョブビルダーは、コードを記述せずに Google Cloud コンソールで Dataflow パイプラインを構築して実行するためのビジュアル UI です。
次のスクリーンショットは、ジョブビルダー UI の詳細を示しています。ここでは、Pub/Sub から BigQuery に読み込まれるパイプラインを作成しています。
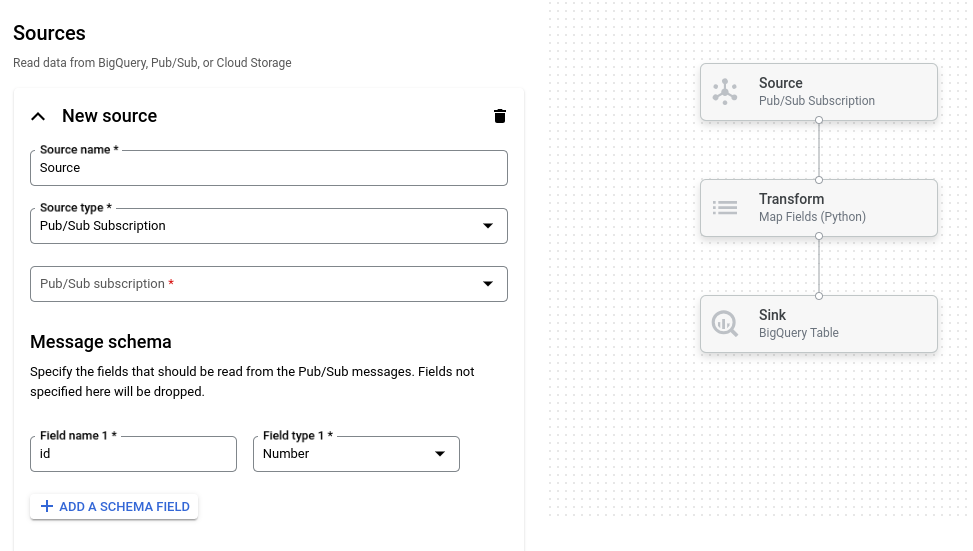
概要
ジョブビルダーは、次の種類のデータの読み取りと書き込みをサポートしています。
- Pub/Sub メッセージ
- BigQuery テーブルデータ
- Cloud Storage 内の CSV ファイル、JSON ファイル、テキスト ファイル
- PostgreSQL、MySQL、Oracle、SQL Server のテーブルデータ
フィルタ、マッピング、SQL、グループ化、結合、展開(配列のフラット化)などのパイプライン変換をサポートしています。
ジョブビルダーでは、次のことができます。
- 変換とウィンドウ集計を使用して Pub/Sub から BigQuery にストリーミングする
- Cloud Storage から BigQuery にデータを書き込む
- エラー処理を使用して誤ったデータをフィルタする(デッドレター キュー)
- SQL 変換を使用して SQL でデータを操作または集計する
- マッピング変換を使用してデータからフィールドを追加、変更、削除する
- 定期的なバッチジョブのスケジュール
ジョブビルダーは、パイプラインを Apache Beam YAML ファイルとして保存し、Beam YAML ファイルからパイプライン定義を読み込むこともできます。この機能を使用すると、ジョブビルダーでパイプラインを設計し、YAML ファイルを Cloud Storage またはソース管理リポジトリに保存して再利用できます。YAML ジョブ定義は、gcloud CLI を使用してジョブを起動するために使用することもできます。
次のようなユースケースで、ジョブビルダーの利用をご検討ください。
- コードを記述することなくパイプラインを迅速に構築したい。
- パイプラインを YAML に保存して再利用する必要がある。
- サポートされているソース、シンク、変換を使用してパイプラインを表現できる。
- ユースケースに一致する Google 提供のテンプレートが存在しない。
サンプルジョブを実行する
文字カウントの例は、Cloud Storage からテキストを読み取り、テキスト行を個別の単語にトークン化して各単語の出現頻度をカウントするバッチ パイプラインです。
Cloud Storage バケットがサービス境界外にある場合、バケットへのアクセスを許可する下り(外向き)ルールを作成します。
Word Count パイプラインを実行する手順は次のとおりです。
Google Cloud コンソールの [ジョブ] ページに移動します。
[テンプレートからジョブを作成] をクリックします
サイドペインで、 [ジョブビルダー] をクリックします。
[ブループリントを読み込む] をクリックします。
[単語数のカウント] をクリックします。ジョブビルダーに、パイプラインのグラフィック表現が渡されます。
ジョブビルダーにパイプラインの各ステップのカードが表示されます。ここには、そのステップの構成パラメータが示されます。たとえば、最初のステップでは、Cloud Storage からテキスト ファイルを読み取ります。ソースデータの場所が [テキストの場所] ボックスに設定されています。
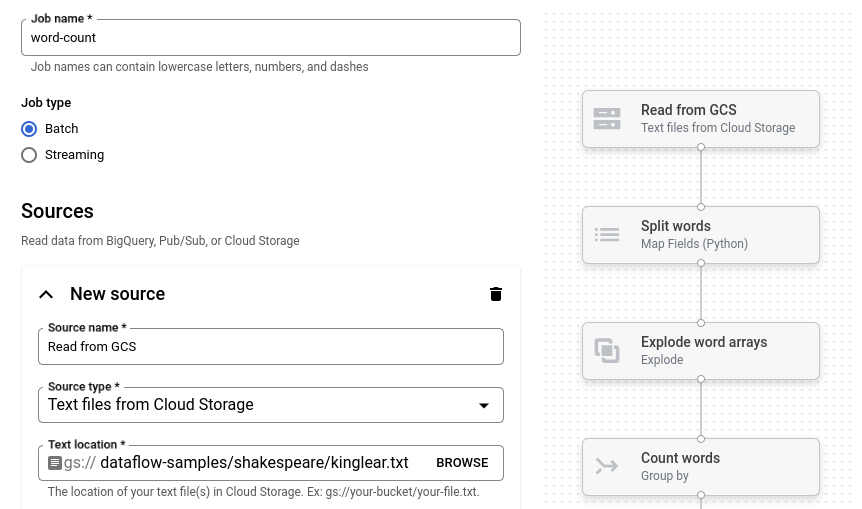
[新しいシンク] というタイトルのカードを見つけます。スクロールが必要な場合があります。
[テキストの場所] ボックスに、出力テキスト ファイルの Cloud Storage の場所のパス接頭辞を入力します。
[ジョブを実行] をクリックします。ジョブビルダーは Dataflow ジョブを作成し、ジョブグラフに移動します。ジョブが開始すると、ジョブグラフにパイプラインのグラフィック表示が表示されます。このグラフ表現は、ジョブビルダーに表示されるグラフ表現と似ています。パイプラインの各ステップが実行されると、ジョブグラフでステータスが更新されます。
[ジョブ情報] パネルには、ジョブの全体的なステータスが表示されます。ジョブが正常に完了すると、[ジョブ ステータス] フィールドが Succeeded に更新されます。
次のステップ
- Dataflow ジョブ モニタリング インターフェースを使用する。
- ジョブビルダーでカスタムジョブを作成する。
- ジョブビルダーで YAML ジョブ定義を保存して読み込む。
- Beam YAML の詳細を確認する。