Dataflow モニタリング インターフェースには、各ジョブをグラフィカルに表現したジョブグラフが表示されます。ジョブグラフには、ジョブの概要、ジョブログ、パイプラインの各ステップに関する情報も表示されます。
ジョブのジョブグラフを表示する手順は次のとおりです。
Google Cloud コンソールで、[Dataflow] > [ジョブ] ページに移動します。
ジョブを選択します。
[ジョブグラフ] タブをクリックします。
パイプラインのジョブグラフでは、パイプライン内の各変換が 1 つのボックスとして表されます。各ボックスには、変換名と以下のようなジョブ ステータス情報が含まれています。
- 実行中: ステップが実行中
- キューに格納済み: FlexRS ジョブ内のステップがキューに格納されている
- 完了しました: ステップが正常に終了
- 停止しました: ジョブが停止したため、ステップが停止された
- 不明: ステータスを報告できなかった
- 失敗しました: ステップは完了しなかった
デフォルトでは、ジョブグラフ ページにグラフビューが表示されます。ジョブグラフを表形式で表示するには、[ジョブステップのビュー] で [表形式] を選択します。表形式には、同じ情報が別の形式で含まれています。表形式は次のシナリオで役立ちます。
- ジョブに多くのステージがあるため、ジョブグラフを操作しにくい。
- ジョブステップを特定のプロパティで並べ替えたい。たとえば、経過時間でテーブルを並べ替えると、遅いステップを特定できます。
基本的なジョブグラフ
パイプライン コード:Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
ジョブグラフ

|
複合変換
複合変換は、複数のネストされたサブ変換を含む変換です。ジョブグラフでは、複合変換は展開可能です。変換を展開してサブ変換を表示するには、矢印をクリックします。
パイプライン コード:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
ジョブグラフ
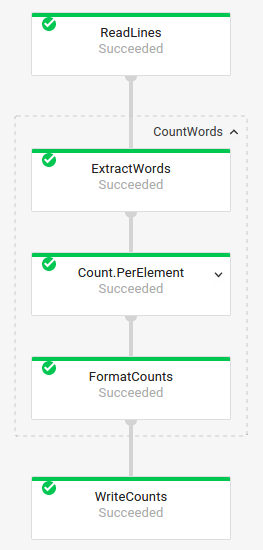
|
パイプラインのコードで、次のようなコードを使用して複合変換を呼び出す場合があります。
result = transform.apply(input);
このようにして呼び出された複合変換では、予期されるネストが省略されるため、Dataflow モニタリング インターフェースで展開して表示されることがあります。パイプラインでは、パイプラインの実行時に安定した一意名に関する警告やエラーが生成されることもあります。
これらの問題を回避するには、推奨される形式を使用して変換を呼び出してください。
result = input.apply(transform);
変換の名前
Dataflow には、モニタリング ジョブ グラフに表示される変換名を取得する方法がいくつかあります。変換名は、Dataflow モニタリング インターフェース、ログファイル、デバッグツールなど、一般公開されている場所で使用されます。個人を特定できる情報(ユーザー名や組織名など)を含む変換名は使用しないでください。
Java
- Dataflow では、変換を適用するときに割り当てる名前を使用できます。
applyメソッドに指定する最初の引数が変換名になります。 - Dataflow では、変換名を推定できます。(カスタム変換を作成した場合は)クラス名から、または(
ParDoなどのコア変換を使用している場合は)DoFn関数オブジェクトの名前から推定できます。
Python
- Dataflow では、変換を適用するときに割り当てる名前を使用できます。変換の
label引数を指定することで変換名を設定できます。 - Dataflow では、変換名を推定できます。(カスタム変換を作成した場合は)クラス名から、または(
ParDoなどのコア変換を使用している場合は)DoFn関数オブジェクトの名前から推定できます。
Go
- Dataflow では、変換を適用するときに割り当てる名前を使用できます。変換名を設定するには、
Scopeを指定します。 - Dataflow では、変換名を推定できます(構造
DoFnを使用している場合は構造体名から、または、関数DoFnを使用している場合は関数名から)。
ステップ情報を確認する
ジョブグラフのステップをクリックすると、[ステップ情報] パネルにステップの詳細情報が表示されます。詳細については、ジョブのステップ情報をご覧ください。