Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Job builder adalah UI visual untuk membangun dan menjalankan pipeline Dataflow di konsol Google Cloud , tanpa perlu menulis kode.
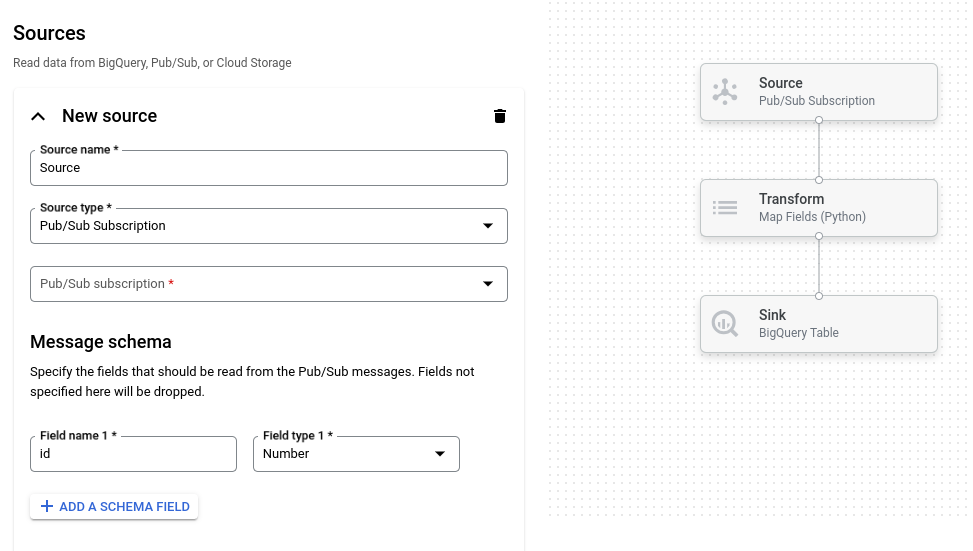
Gambar berikut menunjukkan detail dari UI pembuat tugas. Pada gambar ini, pengguna membuat pipeline untuk membaca dari Pub/Sub ke BigQuery:
Ringkasan
Pembangun tugas mendukung pembacaan dan penulisan jenis data berikut:
Pesan Pub/Sub
Data tabel BigQuery
File CSV, file JSON, dan file teks di Cloud Storage
Data tabel PostgreSQL, MySQL, Oracle, dan SQL Server
Alat ini mendukung transformasi pipeline termasuk filter, peta, SQL, pengelompokan menurut, gabung, dan explode (perataan array).
Dengan pembuat tugas, Anda dapat:
Streaming dari Pub/Sub ke BigQuery dengan transformasi dan agregasi berwindow
Menulis data dari Cloud Storage ke BigQuery
Menggunakan penanganan error untuk memfilter data yang salah (antrean pesan yang tidak terkirim)
Memanipulasi atau menggabungkan data menggunakan SQL dengan transformasi SQL
Menambahkan, mengubah, atau menghapus kolom dari data dengan transformasi pemetaan
Menjadwalkan tugas batch berulang
Pembangun tugas juga dapat menyimpan pipeline sebagai file
YAML Apache Beam
dan memuat definisi pipeline dari file YAML Beam. Dengan menggunakan fitur ini, Anda dapat mendesain pipeline di pembuat tugas
lalu menyimpan file YAML di Cloud Storage atau repositori kontrol sumber
untuk digunakan kembali. Definisi tugas YAML juga dapat digunakan untuk meluncurkan tugas menggunakan gcloud CLI.
Pertimbangkan pembuat tugas untuk kasus penggunaan berikut:
Anda ingin membuat pipeline dengan cepat tanpa menulis kode.
Anda ingin menyimpan pipeline ke YAML untuk digunakan kembali.
Pipeline Anda dapat dinyatakan menggunakan sumber, sink, dan transformasi yang didukung.
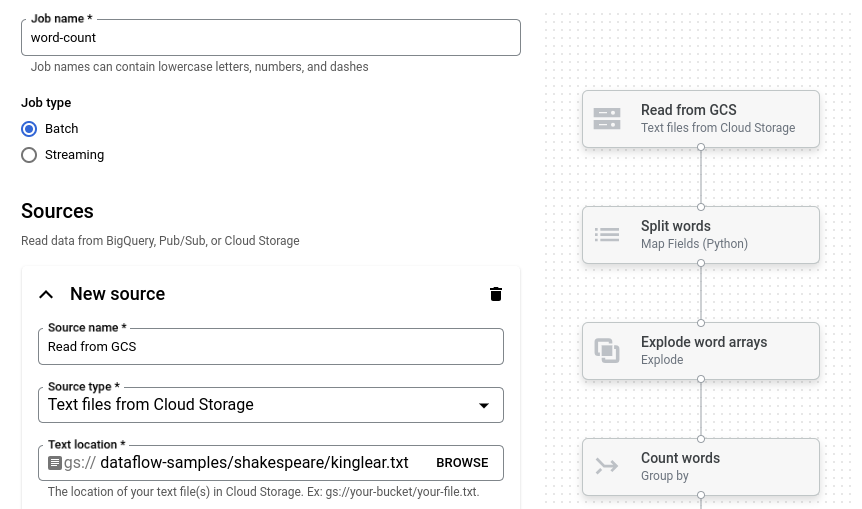
Contoh Word Count adalah pipeline batch yang membaca teks dari Cloud Storage, membuat token baris teks menjadi kata individual, dan menjalankan penghitungan frekuensi pada setiap kata.
Jika bucket Cloud Storage berada di luar perimeter layanan Anda, buat aturan keluar yang mengizinkan akses ke bucket tersebut.
Untuk menjalankan pipeline Word Count, ikuti langkah-langkah berikut:
Klik Jumlah Kata. Penyusun tugas diisi dengan representasi grafis pipeline.
Untuk setiap langkah pipeline, builder tugas menampilkan kartu yang menentukan parameter konfigurasi untuk langkah tersebut. Misalnya, langkah pertama membaca
file teks dari Cloud Storage. Lokasi data sumber sudah diisi otomatis di kotak Lokasi teks.
Cari kartu berjudul Wastafel baru. Anda mungkin perlu men-scroll.
Di kotak Text location, masukkan awalan jalur lokasi Cloud Storage untuk file teks output.
Klik Run job. Builder tugas membuat tugas Dataflow, lalu
membuka grafik tugas. Saat tugas dimulai, grafik tugas akan menampilkan representasi grafis pipeline. Representasi
grafik ini mirip dengan yang ditampilkan di pembuat tugas. Saat setiap
langkah pipeline berjalan, status akan diperbarui dalam grafik tugas.
Panel Info tugas menampilkan status keseluruhan tugas. Jika tugas selesai
dengan berhasil, kolom Status tugas akan diperbarui menjadi Succeeded.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[[["\u003cp\u003eThe Job Builder is a visual, code-free UI in the Google Cloud console for building and running Dataflow pipelines.\u003c/p\u003e\n"],["\u003cp\u003eThe Job Builder supports various data sources (Pub/Sub, BigQuery, Cloud Storage files), sinks, and transforms (filter, join, map, group-by, explode).\u003c/p\u003e\n"],["\u003cp\u003ePipelines built in the Job Builder can be saved as Apache Beam YAML files for reuse, storage, or modification.\u003c/p\u003e\n"],["\u003cp\u003eUsers can validate their pipelines for syntax errors before launching using the built-in validation feature, which will look for issues with Python filters or SQL expressions.\u003c/p\u003e\n"],["\u003cp\u003eUsers can create new batch or streaming pipelines, adding sources, transforms and sinks as desired, then run or save it for later.\u003c/p\u003e\n"]]],[],null,["# Job builder UI overview\n\nThe job builder is a visual UI for building and running Dataflow\npipelines in the Google Cloud console, without writing code.\n\nThe following image shows a detail from the job builder UI. In this image, the\nuser is creating a pipeline to read from Pub/Sub to BigQuery:\n\nOverview\n--------\n\nThe job builder supports reading and writing the following types of data:\n\n- Pub/Sub messages\n- BigQuery table data\n- CSV files, JSON files, and text files in Cloud Storage\n- PostgreSQL, MySQL, Oracle, and SQL Server table data\n\nIt supports pipeline transforms including filter, map, SQL, group-by, join, and explode (array flatten).\n\nWith the job builder you can:\n\n- Stream from Pub/Sub to BigQuery with transforms and windowed aggregation\n- Write data from Cloud Storage to BigQuery\n- Use error handling to filter erroneous data (dead-letter queue)\n- Manipulate or aggregate data using SQL with the SQL transform\n- Add, modify, or drop fields from data with mapping transforms\n- Schedule recurring batch jobs\n\nThe job builder can also save pipelines as\n[Apache Beam YAML](https://beam.apache.org/documentation/sdks/yaml/)\nfiles and load pipeline definitions from Beam YAML files. By using this feature, you can design your pipeline in the job builder\nand then store the YAML file in Cloud Storage or a source control repository\nfor reuse. YAML job definitions can also be used to launch jobs using the gcloud CLI.\n\nConsider the job builder for the following use cases:\n\n- You want to build a pipeline quickly without writing code.\n- You want to save a pipeline to YAML for re-use.\n- Your pipeline can be expressed using the supported sources, sinks, and transforms.\n- There is no [Google-provided template](/dataflow/docs/guides/templates/provided-templates) that matches your use case.\n\nRun a sample job\n----------------\n\nThe Word Count example is a batch pipeline that reads text from Cloud Storage, tokenizes the text lines into individual words, and performs a frequency count on each of the words.\n\nIf the Cloud Storage bucket is outside of your [service perimeter](/vpc-service-controls/docs/overview), create an [egress rule](/vpc-service-controls/docs/ingress-egress-rules) that allows access to the bucket.\n\nTo run the Word Count pipeline, follow these steps:\n\n1. Go to the **Jobs** page in the Google Cloud console.\n\n [Go to Jobs](https://console.cloud.google.com/dataflow)\n2. Click add_box**Create job from\n template**.\n\n3. In the side pane, click edit **Job builder**.\n\n4. Click **Load blueprints** expand_more.\n\n5. Click **Word Count**. The job builder is populated with a graphical\n representation of the pipeline.\n\n For each pipeline step, the job builder displays a card that specifies the\n configuration parameters for that step. For example, the first step reads\n text files from Cloud Storage. The location of the source data is\n pre-populated in the **Text location** box.\n\n1. Locate the card titled **New sink**. You might need to scroll.\n\n2. In the **Text location** box, enter the Cloud Storage location path prefix for the output text files.\n\n3. Click **Run job** . The job builder creates a Dataflow job and then\n navigates to the [job graph](/dataflow/docs/guides/job-graph). When the job\n starts, the job graph shows a graphical representation of the pipeline. This\n graph representation is similar to the one shown in the job builder. As each\n step of the pipeline runs, the status is updated in the job graph.\n\nThe **Job info** panel shows the overall status of the job. If the job completes\nsuccessfully, the **Job status** field updates to `Succeeded`.\n\nWhat's next\n-----------\n\n- [Use the Dataflow job monitoring interface](/dataflow/docs/guides/monitoring-overview).\n- [Create a custom job](/dataflow/docs/guides/job-builder-custom-job) in the job builder.\n- [Save and load](/dataflow/docs/guides/job-builder-save-load-yaml) YAML job definitions in the job builder.\n- Learn more about [Beam YAML](https://beam.apache.org/documentation/sdks/yaml/)."]]