用途:其他專案中的 Dataproc 叢集存取權控管
本頁說明在部署及執行使用其他 Google Cloud 專案中 Dataproc 叢集的管道時,如何管理存取權。
情境
根據預設,當 Cloud Data Fusion 執行個體在Google Cloud 專案中啟動時,會使用同一個專案中的 Dataproc 叢集部署及執行管道。不過,貴機構可能會要求您在其他專案中使用叢集。針對這項用途,您必須管理專案之間的存取權。下一個頁面將說明如何變更基準 (預設) 設定,並套用適當的存取權控制項。
事前準備
如要瞭解這個用途的解決方案,您需要瞭解以下背景資訊:
假設和範圍
此用途有以下需求:
解決方案
這個解決方案會比較基準和用途專屬的架構和設定。
架構
下列圖表比較了在使用同一個專案 (基準) 的叢集和透過租用戶專案 VPC 在不同專案中使用叢集時,建立 Cloud Data Fusion 執行個體和執行管道的專案架構。
基準架構
下圖顯示專案的基本架構:
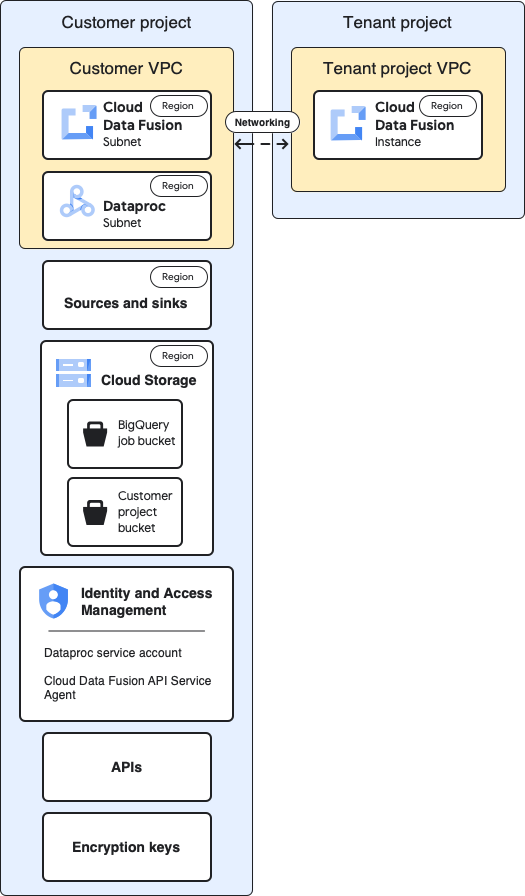
在基準設定中,您會建立私人 Cloud Data Fusion 執行個體,並執行管道,但不進行額外自訂:
- 您使用其中一個內建運算設定檔
- 來源和接收端與執行個體位於相同專案
- 未向任何服務帳戶授予其他角色
如要進一步瞭解用戶群和客戶專案,請參閱「網路」一文。
用途架構
下圖顯示在其他專案中使用叢集時的專案架構:
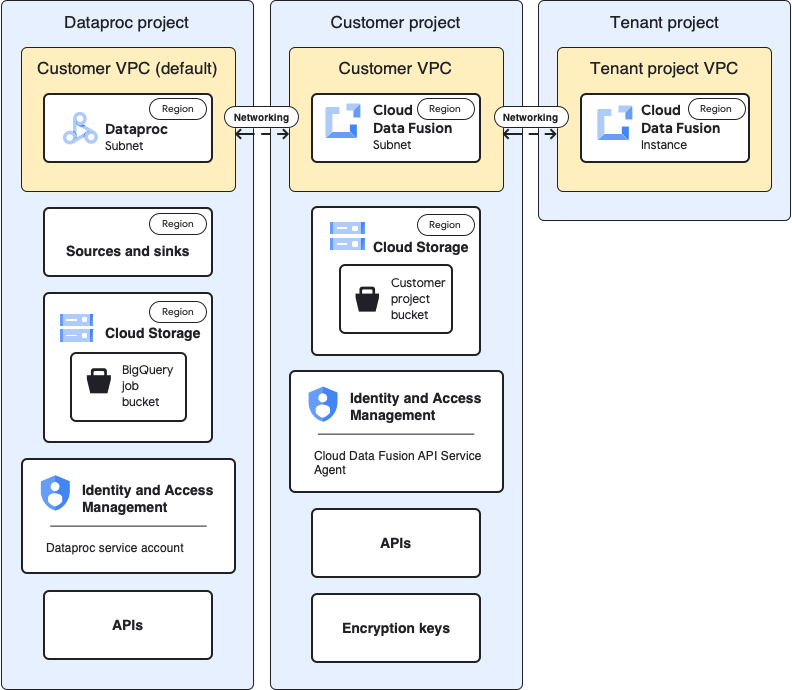
設定
以下各節會比較基準設定與用途專屬設定,說明如何透過預設租戶專案虛擬私有雲,在其他專案中使用 Dataproc 叢集。
在以下用途說明中,客戶專案是指 Cloud Data Fusion 執行個體的執行位置,而 Dataproc 專案則是指 Dataproc 叢集的啟動位置。
租用戶專案的 VPC 和執行個體
| 基準 |
用途 |
在上圖的基準架構圖中,租用戶專案包含下列元件:
- 系統會自動建立的預設 VPC。
- Cloud Data Fusion 執行個體的實體部署。
|
這類用途不需要額外設定。 |
客戶專案
| 基準 |
用途 |
| 您會在 Google Cloud 專案中部署及執行管道。根據預設,當您執行管道時,系統會在這個專案中啟動 Dataproc 叢集。 |
在這個用途中,您管理兩個專案。在本頁中,「客戶專案」是指 Cloud Data Fusion 執行個體的執行位置。
「Dataproc 專案」是指 Dataproc 叢集的啟動位置。 |
客戶虛擬私有雲
| 基準 |
用途 |
從客戶的角度來看,Cloud Data Fusion 會在邏輯上位於客戶 VPC 中。
重點摘要:
您可以在專案的「虛擬私有雲網路」頁面中找到客戶虛擬私有雲端網路詳細資料。
前往「VPC networks」(虛擬私有雲網路) |
這類用途不需要額外設定。 |
Cloud Data Fusion 子網路
| 基準 |
用途 |
從客戶的角度來看,這個子網路是 Cloud Data Fusion 的邏輯位置。
重點摘要:
這個子網路的區域與租用戶專案中的 Cloud Data Fusion 執行個體位置相同。 |
這類用途不需要額外設定。 |
Dataproc 子網路
| 基準 |
用途 |
執行管道時,Dataproc 叢集會在這個子網路中啟動。
重點整理:
- 在這個基準設定中,Dataproc 會在與 Cloud Data Fusion 執行個體相同的子網路中執行。
- Cloud Data Fusion 會在 Cloud Data Fusion 的執行個體和子網路所在的區域中找出子網路。如果這個區域只有一個子網路,則子網路會相同。
- Dataproc 子網路必須具備私人 Google 存取權。
|
這是在執行管道時,Dataproc 叢集會啟動的全新子網路。
重點整理:
- 針對這個新的子網路,將私人 Google 存取權設為「開啟」。
- Dataproc 子網路不必與 Cloud Data Fusion 執行個體位於相同位置。
|
來源和接收器
| 基準 |
用途 |
資料擷取來源和資料載入接收器,例如 BigQuery 來源和接收器。
重點整理:
- 擷取及載入資料的工作必須在與資料集相同的位置處理,否則會產生錯誤。
|
本頁面上的用途專屬存取權控管設定適用於 BigQuery 來源和接收端。 |
Cloud Storage
| 基準 |
用途 |
客戶專案中的儲存值區,可協助在 Cloud Data Fusion 和 Dataproc 之間轉移檔案。
重點整理:
- 您可以透過 Cloud Data Fusion 網路介面,在暫時叢集的「Compute Profile」設定中指定這個值區。
- 針對批次和即時處理管道或複製工作:如果您未在運算設定檔中指定值區,Cloud Data Fusion 會在與執行個體相同的專案中建立值區,以便執行這項作業。
- 即使是靜態 Dataproc 叢集,在這個基準設定中,值區也是由 Cloud Data Fusion 建立,因此與 Dataproc 暫存和暫時值區不同。
- Cloud Data Fusion API 服務代理程式具有內建權限,可在包含 Cloud Data Fusion 執行個體的專案中建立這個值區。
|
這類用途不需要額外設定。 |
來源和接收端使用的暫時性 bucket
| 基準 |
用途 |
外掛程式為來源和接收端建立的暫存值區,例如 BigQuery 接收端外掛程式啟動的載入工作。
重點整理:
- 您可以在設定來源和匯出外掛程式屬性時定義這些分桶。
- 如果未定義值區,系統會在 Dataproc 執行的專案中建立一個值區。
- 如果資料集是多地區資料集,系統會在相同範圍內建立值區。
- 如果您在外掛程式設定中定義值區,則值區的區域必須與資料集的區域相符。
- 如果您未在外掛程式設定中定義值區,系統會在管道完成後刪除為您建立的值區。
|
在這個用途中,您可以在任何專案中建立值區。 |
值區是外掛程式資料的來源或接收器
| 基準 |
用途 |
| 客戶值區:您可以在外掛程式設定中指定這些值區,例如 Cloud Storage 外掛程式和 FTP 到 Cloud Storage 外掛程式。 |
這類用途不需要額外設定。 |
IAM:Cloud Data Fusion API 服務代理人
| 基準 |
用途 |
啟用 Cloud Data Fusion API 時,系統會自動將 Cloud Data Fusion API 服務代理人角色 (roles/datafusion.serviceAgent) 授予
Cloud Data Fusion 服務帳戶 (主要服務代理人)。
重點整理:
- 這個角色包含與執行個體相同專案中的服務權限,例如 BigQuery 和 Dataproc。如需瞭解所有支援的服務,請參閱角色詳細資料。
- Cloud Data Fusion 服務帳戶會執行以下操作:
- 資料層 (管道設計和執行) 與其他服務的通訊 (例如,在設計階段與 Cloud Storage、BigQuery 和 Datastream 通訊)。
- 佈建 Dataproc 叢集。
- 如果您要從 Oracle 來源複製資料,則必須在發生工作所在的專案中,將 Datastream 管理員和儲存空間管理員角色指派給這個服務帳戶。本頁未說明複製用途。
|
針對此用途,請將 Cloud Data Fusion API Service Agent 角色授予 Dataproc 專案中的服務帳戶。接著,在該專案中授予下列角色:
- Compute 網路使用者角色
- Dataproc 編輯者角色
|
IAM:Dataproc 服務帳戶
| 基準 |
用途 |
用於在 Dataproc 叢集中以工作形式執行管道的服務帳戶。根據預設,該帳戶為 Compute Engine 服務帳戶。
選用步驟:在基準設定中,您可以將預設服務帳戶變更為同一個專案中的其他服務帳戶。將下列身分與存取權管理角色授予新服務帳戶:
- Cloud Data Fusion 執行者角色。這個角色可讓 Dataproc 與 Cloud Data Fusion API 通訊。
- Dataproc 工作站角色。這個角色可讓工作在 Dataproc 叢集中執行。
重點整理:
- 新服務的 API 代理人服務帳戶必須獲得 Dataproc 服務帳戶的服務帳戶使用者角色,才能讓服務 API 代理人使用該帳戶啟動 Dataproc 叢集。
|
本應用實例假設您使用 Dataproc 專案的預設 Compute Engine 服務帳戶 (PROJECT_NUMBER-compute@developer.gserviceaccount.com)。
將下列角色授予 Dataproc 專案中的預設 Compute Engine 服務帳戶。
- Dataproc 工作站角色
- 儲存空間管理員角色 (或至少具備 `storage.buckets.create` 權限),讓 Dataproc 為 BigQuery 建立暫時性資料夾。
- BigQuery 工作使用者角色。這個角色可讓 Dataproc 建立載入工作。根據預設,工作會在 Dataproc 專案中建立。
- BigQuery 資料集編輯者角色。這個角色可讓 Dataproc 在載入資料時建立資料集。
將「服務帳戶使用者」角色授予 Dataproc 專案預設 Compute Engine 服務帳戶的 Cloud Data Fusion 服務帳戶。這項操作必須在 Dataproc 專案中執行。
將 Dataproc 專案的預設 Compute Engine 服務帳戶新增至 Cloud Data Fusion 專案。並授予下列角色:
- Storage 物件檢視者角色,可從 Cloud Data Fusion 消費者值區擷取管道工作相關的構件。
- Cloud Data Fusion 執行者角色,以便 Dataproc 叢集在執行時與 Cloud Data Fusion 通訊。
|
API
| 基準 |
用途 |
啟用 Cloud Data Fusion API 時,系統也會啟用下列 API。如要進一步瞭解這些 API,請前往專案的「API 和服務」頁面。
前往「API 和服務」頁面
- Cloud Autoscaling API
- Dataproc API
- Cloud Dataproc Control API
- Cloud DNS API
- Cloud OS Login API
- Pub/Sub API
- Compute Engine API
- Container Filesystem API
- Container Registry API
- Service Account Credentials API
- Identity and Access Management API
- Google Kubernetes Engine API
啟用 Cloud Data Fusion API 時,系統會自動將下列服務帳戶新增至專案:
- Google API 服務代理
- Compute Engine 服務代理人
- Kubernetes Engine 服務代理人
- Google Container Registry 服務代理人
- Google Cloud Dataproc 服務代理人
- Cloud KMS 服務代理人
- Cloud Pub/Sub 服務帳戶
|
針對此用途,請在包含 Dataproc 專案的專案中啟用下列 API:
- Compute Engine API
- Dataproc API (這項專案可能已啟用)。啟用 Dataproc API 時,系統會自動啟用 Dataproc Control API。
- Resource Manager API。
|
加密金鑰
| 基準 |
用途 |
在基準設定中,加密金鑰可以由 Google 代管或CMEK
管理
重點整理:
如果您使用 CMEK,基準設定必須符合下列條件:
- 金鑰必須是區域性質,且必須與 Cloud Data Fusion 執行個體位於相同區域。
- 在建立金鑰的專案中,於金鑰層級 (而非 Google Cloud 控制台的 IAM 頁面) 將 Cloud KMS CryptoKey 加密者/解密者角色授予下列服務帳戶:
- Cloud Data Fusion API 服務帳戶
- Dataproc 服務帳戶,預設為 Compute Engine 服務代理 (
service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com)
- Google Cloud Dataproc 服務代理人 (
service-PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com)
- Cloud Storage 服務代理人 (
service-PROJECT_NUMBER@gs-project-accounts.iam.gserviceaccount.com)
視管道中使用的服務而定 (例如 BigQuery 或 Cloud Storage),服務帳戶也必須具備 Cloud KMS CryptoKey 加密者/解密者角色:
- BigQuery 服務帳戶 (
bq-PROJECT_NUMBER@bigquery-encryption.iam.gserviceaccount.com)
- Pub/Sub 服務帳戶 (
service-PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com)
- Spanner 服務帳戶 (
service-PROJECT_NUMBER@gcp-sa-spanner.iam.gserviceaccount.com)
|
如果您不使用 CMEK,則無須針對此用途進行額外變更。
如果您使用 CMEK,必須在建立 CMEK 的專案中,將 Cloud KMS CryptoKey 加密者/解密者角色提供給下列服務帳戶:
- Cloud Storage 服務代理人 (
service-PROJECT_NUMBER@gs-project-accounts.iam.gserviceaccount.com)
視管道中使用的服務而定 (例如 BigQuery 或 Cloud Storage),其他服務帳戶也必須在金鑰層級獲得 Cloud KMS CryptoKey 加密者/解密者角色。例如:
- BigQuery 服務帳戶 (
bq-PROJECT_NUMBER@bigquery-encryption.iam.gserviceaccount.com)
- Pub/Sub 服務帳戶 (
service-PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com)
- Spanner 服務帳戶 (
service-PROJECT_NUMBER@gcp-sa-spanner.iam.gserviceaccount.com)
|
完成這些用途專屬設定後,資料管道就能開始在其他專案的叢集中執行。
後續步驟
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2025-10-19 (世界標準時間)。
[[["容易理解","easyToUnderstand","thumb-up"],["確實解決了我的問題","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["難以理解","hardToUnderstand","thumb-down"],["資訊或程式碼範例有誤","incorrectInformationOrSampleCode","thumb-down"],["缺少我需要的資訊/範例","missingTheInformationSamplesINeed","thumb-down"],["翻譯問題","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["上次更新時間:2025-10-19 (世界標準時間)。"],[],[]]