本頁說明如何在 Cloud Data Fusion 中針對現有的 Dataproc 叢集執行管道。
根據預設,Cloud Data Fusion 會為每個管道建立暫時叢集:在管道執行開始時建立叢集,然後在管道執行完畢後刪除。雖然這項行為可確保資源只在需要時建立,進而節省成本,但在下列情況下,這項預設行為可能不符合需求:
如果為每個管道建立新叢集所需的時間,對您的用途來說過於耗時。
如果貴機構需要集中管理叢集建立作業,例如,您想針對所有 Dataproc 叢集強制執行特定政策。
在這些情況下,請改為按照下列步驟,對現有叢集執行管道。
事前準備
你需要下列項目:
Cloud Data Fusion 執行個體。
現有的 Dataproc 叢集。
如果您在 Cloud Data Fusion 6.2 版中執行管道,請使用與 Hadoop 2.x 搭配執行的舊版 Dataproc 映像檔 (例如 1.5-debian10),或升級至最新的 Cloud Data Fusion 版本。
連線至現有叢集
在 Cloud Data Fusion 6.2.1 以上版本中,您可以建立新的 Compute Engine 設定檔,然後連線至現有的 Dataproc 叢集。
前往您的執行個體:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 頁面。
如要在 Cloud Data Fusion Studio 中開啟執行個體,請依序按一下「Instances」和「View instance」。
按一下「系統管理員」。
按一下 [設定] 標籤。
按一下 系統運算設定檔。
按一下「建立新資料」。系統會開啟提供者頁面。
按一下「現有的 Dataproc」。
輸入設定檔、叢集和監控資訊。
按一下 [建立]。
設定管道以使用自訂設定檔
前往您的執行個體:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 頁面。
如要在 Cloud Data Fusion Studio 中開啟執行個體,請依序按一下「Instances」和「View instance」。
前往「Studio」頁面查看管道。
按一下 [設定]。
按一下「Compute 設定」。
按一下您建立的設定檔。
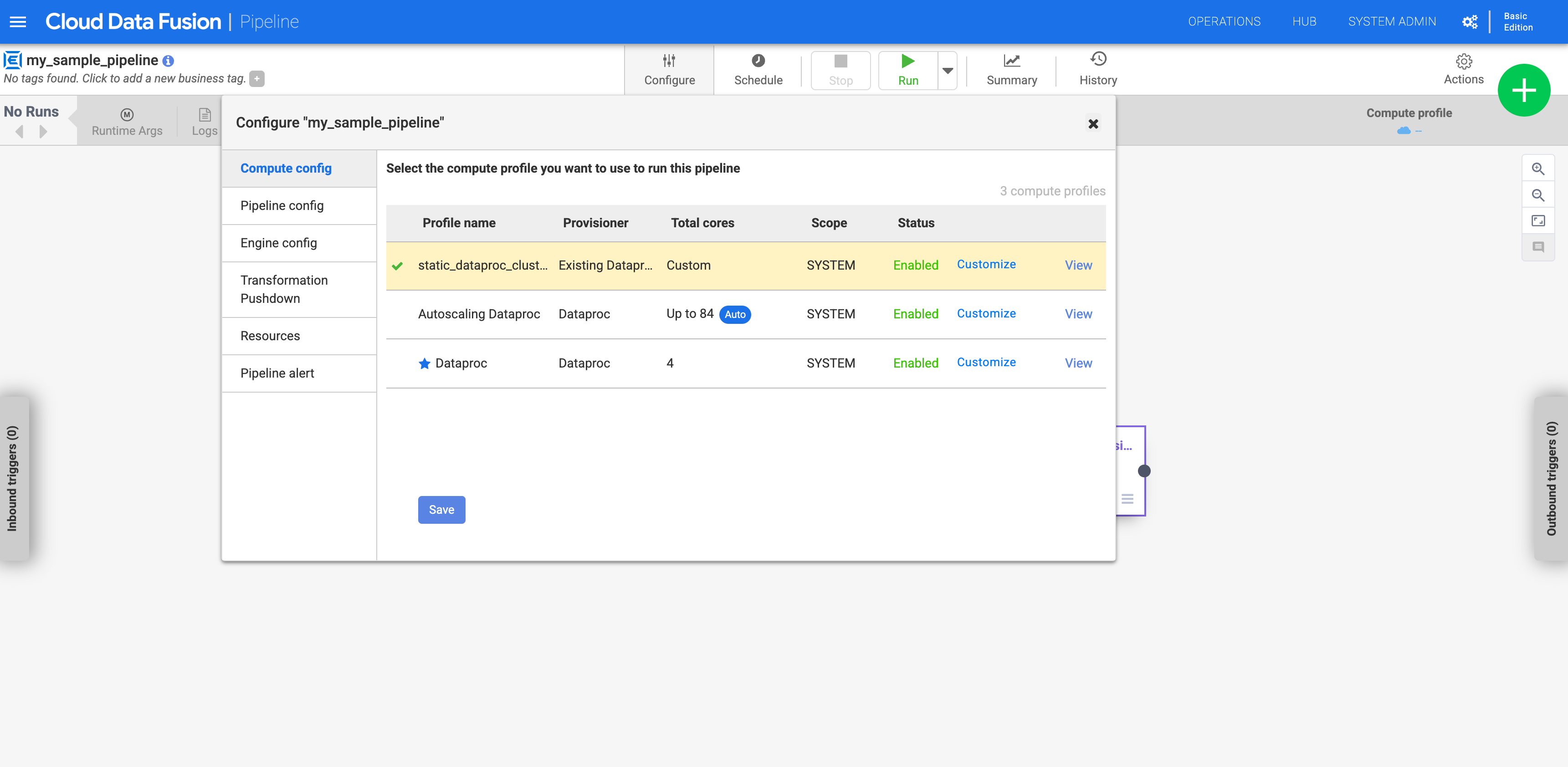
圖 1:按一下自訂設定檔 執行管道。並對現有的 Dataproc 叢集執行。