이 페이지에서는 Apache HBase 클러스터의 데이터를Google Cloud의 Bigtable 인스턴스로 마이그레이션할 때의 고려사항과 프로세스를 설명합니다.
이 페이지에 설명된 프로세스를 진행하려면 애플리케이션을 오프라인으로 전환해야 합니다. 다운타임 없이 마이그레이션하려면 HBase에서 Bigtable로 복제의 온라인 마이그레이션 안내를 참고하세요.
Dataproc 또는 Compute Engine과 같이 Google Cloud 서비스에서 호스팅되는 HBase 클러스터에서 Bigtable로 데이터를 마이그레이션하려면 Google Cloud 에서 호스팅되는 HBase를 Bigtable로 마이그레이션을 참고하세요.
이 마이그레이션을 시작하기 전에 성능 영향, Bigtable 스키마 디자인, 인증 및 승인의 접근 방식, Bigtable 특성 세트를 고려해야 합니다.
마이그레이션 전 고려사항
이 섹션에서는 마이그레이션을 시작하기 전에 검토하고 고려할 몇 가지 사항을 설명합니다.
성능
일반적인 워크로드에서 Bigtable은 매우 예측 가능한 성능을 제공합니다. 데이터를 마이그레이션하기 전에 Bigtable 성능에 영향을 미치는 요인을 이해해야 합니다.
Bigtable 스키마 디자인
대부분의 경우 HBase에서와 동일한 스키마 디자인을 Bigtable에서 사용할 수 있습니다. 스키마를 변경하려는 경우 또는 사용 사례가 변경되는 경우 데이터를 마이그레이션하기 전에 스키마 디자인에 나와 있는 개념을 검토하세요.
인증 및 승인
Bigtable에 대한 액세스 제어를 설계하기 전에 기존 HBase 인증 및 승인 프로세스를 검토해야 합니다.
Bigtable은 Google Cloud의 표준 인증 메커니즘과 ID 및 액세스 관리를 사용하여 액세스 제어를 제공하므로 HBase의 기존 승인을 IAM으로 전환해야 합니다. 사용자는 HBase에 액세스 제어 메커니즘을 제공하는 기존 Hadoop 그룹을 다른 서비스 계정으로 매핑할 수 있습니다.
Bigtable을 사용하면 프로젝트, 인스턴스, 테이블 수준에서 액세스를 제어할 수 있습니다. 자세한 내용은 액세스 제어를 참조하세요.
다운타임 요구사항
이 페이지에 설명된 마이그레이션 접근 방식에서는 마이그레이션 기간 동안 애플리케이션을 오프라인으로 전환해야 합니다. Bigtable로 마이그레이션하는 동안 다운타임을 허용할 수 없는 비즈니스의 경우 HBase에서 Bigtable로 복제의 온라인 마이그레이션 안내를 참고하세요.
HBase를 Bigtable로 마이그레이션
HBase에서 Bigtable로 데이터를 마이그레이션하려면 각 테이블의 HBase 스냅샷을 Cloud Storage로 내보낸 다음 데이터를 Bigtable로 가져옵니다. 이 단계는 단일 HBase 클러스터에 대한 것으로 다음 여러 섹션에서 자세히 설명합니다.
- HBase 클러스터에 쓰기 전송을 중지합니다.
- HBase 클러스터 테이블의 스냅샷을 만듭니다.
- 스냅샷 파일을 Cloud Storage로 내보냅니다.
- 해시를 계산하여 Cloud Storage로 내보냅니다.
- Bigtable에서 대상 테이블을 만듭니다.
- HBase 데이터를 Cloud Storage에서 Bigtable로 가져옵니다.
- 가져온 데이터를 검증합니다.
- Bigtable에 쓰기를 라우팅합니다.
시작하기 전에
스냅샷을 저장할 Cloud Storage 버킷을 만듭니다. Dataflow 작업을 실행할 위치와 동일한 위치에 버킷을 만듭니다.
새 테이블을 저장할 Bigtable 인스턴스를 만듭니다.
내보낼 Hadoop 클러스터를 식별합니다. 마이그레이션 작업을 HBase 클러스터에서 또는 네트워크가 HBase 클러스터의 이름 노드와 데이터 노드에 연결된 별도의 Hadoop 클러스터에서 실행할 수 있습니다.
Hadoop 클러스터의 모든 노드와 작업이 시작되는 호스트에 Cloud Storage 커넥터를 설치하고 구성합니다. 자세한 설치 단계는 Cloud Storage 커넥터 설치를 참조하세요.
HBase 클러스터와 Bigtable 프로젝트에 연결할 수 있는 호스트에서 명령어 셸을 엽니다. 여기서 다음 단계를 완료합니다.
스키마 변환 도구를 가져옵니다.
wget BIGTABLE_HBASE_TOOLS_URLBIGTABLE_HBASE_TOOLS_URL을 도구의 Maven 저장소에서 제공하는 최신JAR with dependencies의 URL로 바꿉니다. 파일 이름은https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar와 유사합니다.URL을 찾거나 JAR을 수동으로 다운로드하려면 다음을 수행합니다.
- 저장소로 이동합니다.
- 최신 버전 번호를 클릭합니다.
JAR with dependencies file을 식별합니다(일반적으로 맨 위에 있음).- 마우스 오른쪽 버튼을 클릭하고 URL을 복사하거나 클릭하여 파일을 다운로드합니다.
가져오기 도구를 가져옵니다.
wget BIGTABLE_BEAM_IMPORT_URLBIGTABLE_BEAM_IMPORT_URL을 도구의 Maven 저장소에서 제공하는 최신shaded JAR의 URL로 바꿉니다. 파일 이름은https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar와 유사합니다.URL을 찾거나 JAR을 수동으로 다운로드하려면 다음을 수행합니다.
- 저장소로 이동합니다.
- 최신 버전 번호를 클릭합니다.
- 다운로드를 클릭합니다.
- shaded.jar 위로 마우스를 가져갑니다.
- 마우스 오른쪽 버튼을 클릭하고 URL을 복사하거나 클릭하여 파일을 다운로드합니다.
다음 환경 변수를 설정합니다.
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORY다음을 바꿉니다.
PROJECT_ID: 인스턴스가 있는 Google Cloud 프로젝트INSTANCE_ID: 데이터를 가져올 Bigtable 인스턴스의 식별자REGION: Bigtable 인스턴스의 클러스터 중 하나가 포함된 리전. 예:northamerica-northeast2CLUSTER_NUM_NODES: Bigtable 인스턴스의 노드 수TRANSLATE_JAR: Maven에서 다운로드한bigtable hbase toolsJAR 파일의 이름과 버전 번호. 값은bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar과 같아야 합니다.IMPORT_JAR: Maven에서 다운로드한bigtable-beam-importJAR 파일의 이름과 버전 번호. 값은bigtable-beam-import-1.24.0-shaded.jar과 같아야 합니다.BUCKET_NAME: 스냅샷을 저장하는 Cloud Storage 버킷의 이름ZOOKEEPER_QUORUM: 도구가 연결될 Zkeeper 호스트(host1.myownpersonaldomain.com형식)MIGRATION_SOURCE_DIRECTORY: 마이그레이션하려는 데이터가 포함된 HBase 호스트의 디렉터리(hdfs://host1.myownpersonaldomain.com:8020/hbase형식)
(선택사항) 변수가 올바르게 설정되었는지 확인하려면
printenv명령어를 실행하여 모든 환경 변수를 봅니다.
HBase에 쓰기 전송 중지
HBase 테이블의 스냅샷을 생성하기 전에 HBase 클러스터에 쓰기 전송을 중지합니다.
HBase 테이블 스냅샷 만들기
HBase 클러스터가 더 이상 데이터를 수집하지 않으면 Bigtable로 마이그레이션하려는 각 테이블의 스냅샷을 만듭니다.
스냅샷은 처음에 HBase 클러스터에 최소한의 스토리지 사용 공간이 있지만 시간이 지나면 원래 테이블과 동일한 크기로 증가할 수 있습니다. 스냅샷은 CPU 리소스를 소비하지 않습니다.
각 스냅샷에 고유한 이름을 사용하여 각 테이블에 대해 다음 명령어를 실행합니다.
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
다음을 바꿉니다.
TABLE_NAME: 데이터를 내보낼 HBase 테이블의 이름SNAPSHOT_NAME: 새 스냅샷 이름
HBase 스냅샷을 Cloud Storage로 내보내기
스냅샷을 만든 후에 내보내야 합니다. 프로덕션 HBase 클러스터에서 내보내기 작업을 실행할 때 클러스터와 다른 HBase 리소스를 모니터링하여 클러스터가 양호한 상태로 있는지 확인합니다.
내보내려는 스냅샷마다 다음을 실행합니다.
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
SNAPSHOT_NAME을 내보낼 스냅샷의 이름으로 바꿉니다.
해시 계산 및 내보내기
그런 다음 마이그레이션이 완료된 후 검증에 사용할 해시를 만듭니다.
HashTable은 HBase에서 제공하는 검증 도구로, 행 범위의 해시를 계산하여 파일로 내보냅니다. 대상 테이블에서 sync-table 작업을 실행하여 해시와 일치시키고 마이그레이션된 데이터의 무결성에 대한 확신을 얻을 수 있습니다.
내보낸 테이블마다 다음 명령어를 실행합니다.
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
다음을 바꿉니다.
TABLE_NAME: 스냅샷을 만들고 내보낸 HBase 테이블의 이름
대상 테이블 만들기
다음 단계는 내보낸 각 스냅샷의 Bigtable 인스턴스에 대상 테이블을 만드는 것입니다. 인스턴스에 대한 bigtable.tables.create 권한이 있는 계정을 사용합니다.
이 가이드에서는 테이블을 자동으로 만드는 Bigtable 스키마 변환 도구를 사용합니다. 그러나 Bigtable 스키마가 HBase 스키마와 정확하게 일치하지 않게 하려면 cbt 명령줄 도구나 Google Cloud 콘솔을 사용하여 테이블을 만들면 됩니다.
Bigtable 스키마 변환 도구에서 테이블 이름, column family, 가비지 컬렉션 정책, 분할을 포함한 HBase 테이블의 스키마를 캡처합니다. 그런 다음 Bigtable에 비슷한 테이블을 만듭니다.
가져오려는 테이블마다 다음을 실행하여 HBase의 스키마를 Bigtable로 복사합니다.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
TABLE_NAME을 가져오려는 HBase 테이블의 이름으로 바꿉니다. 스키마 변환 도구는 새 Bigtable 테이블에 이 이름을 사용합니다.
원하는 경우 TABLE_NAME을 만들려는 모든 테이블을 캡처하는 '.*'와 같은 정규 표현식으로 바꾼 다음 명령어를 한 번만 실행할 수 있습니다.
Dataflow를 사용하여 HBase 데이터를 Bigtable로 가져오기
데이터를 마이그레이션할 테이블이 준비되면 데이터를 가져오고 검증할 수 있습니다.
압축되지 않은 테이블
HBase 테이블이 압축되지 않으면 마이그레이션하려는 테이블마다 다음 명령어를 실행합니다.
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
다음을 바꿉니다.
TABLE_NAME: 가져올 HBase 테이블의 이름입니다. 스키마 변환 도구는 새 Bigtable 테이블에 이 이름을 사용합니다. 새 테이블 이름은 지원되지 않습니다.SNAPSHOT_NAME: 가져오려는 테이블의 스냅샷에 할당한 이름
이 명령어를 실행하면 도구에서 HBase 스냅샷을 Cloud Storage 버킷으로 복원한 후 가져오기 작업을 시작합니다. 스냅샷 크기에 따라 스냅샷 복원 프로세스를 완료하는 데 몇 분 정도 걸릴 수 있습니다.
가져올 때 다음 팁에 유의하세요.
- 데이터 로드 성능을 개선하려면
maxNumWorkers를 설정하세요. 이 값은 합리적인 시간 내에 가져오기 작업을 완료하는 데 충분하지만 Bigtable 인스턴스에 부담을 주지 않는 만큼의 컴퓨팅 성능을 제공합니다.- 다른 워크로드에도 Bigtable 인스턴스를 사용하지 않으면 Bigtable 인스턴스의 노드 수에 3을 곱하고
maxNumWorkers에 해당 숫자를 사용합니다. - HBase 데이터를 가져오는 동시에 다른 워크로드의 인스턴스를 사용하는 경우
maxNumWorkers값을 적절하게 줄입니다.
- 다른 워크로드에도 Bigtable 인스턴스를 사용하지 않으면 Bigtable 인스턴스의 노드 수에 3을 곱하고
- 기본 작업자 유형을 사용합니다.
- 가져오기 중에 Bigtable 인스턴스의 CPU 사용량을 모니터링해야 합니다. Bigtable 인스턴스의 CPU 사용률이 너무 높으면 노드를 추가해야 할 수도 있습니다. 클러스터가 추가 노드의 성능 이점을 제공하는 데 최대 20분이 걸릴 수 있습니다.
Bigtable 인스턴스 모니터링에 대한 자세한 내용은 모니터링을 참고하세요.
Snappy 압축 테이블
Snappy 압축 테이블을 가져오는 경우 Dataflow 파이프라인에서 커스텀 컨테이너 이미지를 사용해야 합니다. 압축된 데이터를 Bigtable로 가져오는 데 사용하는 커스텀 컨테이너 이미지에서 Hadoop 기본 압축 라이브러리 지원을 제공합니다. Dataflow Runner v2를 사용하려면 Apache Beam SDK 버전 2.30.0 이상과 Java용 HBase 클라이언트 라이브러리 버전 2.3.0 이상이 있어야 합니다.
Snappy 압축 테이블을 가져오려면 압축되지 않은 테이블에서 실행하는 동일한 명령어를 실행하되 다음 옵션을 추가합니다.
--enableSnappy=true
Bigtable에서 가져온 데이터 검증
가져온 데이터의 유효성을 검사하려면 sync-table 작업을 실행해야 합니다. sync-table 작업은 Bigtable의 행 범위에 대한 해시를 계산한 후 이전에 계산한 HashTable 출력과 일치시킵니다.
sync-table 작업을 실행하려면 명령어 셸에서 다음을 실행합니다.
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
TABLE_NAME을 가져오려는 HBase 테이블의 이름으로 바꿉니다.
sync-table 작업이 완료되면 Dataflow 작업 세부정보 페이지를 열고 작업의 커스텀 카운터 섹션을 검토합니다. 가져오기 작업에서 성공적으로 모든 데이터를 가져오면 ranges_matched 값에 값 하나가 있고 ranges_not_matched 값은 0이 됩니다.

ranges_not_matched에 값이 표시되면 로그 페이지를 열고 작업자 로그를 선택한 다음 불일치 범위를 기준으로 필터링합니다. 이러한 로그의 머신이 읽을 수 있는 출력은 동기화 테이블 outputPrefix 옵션에서 만드는 출력 대상의 Cloud Storage에 저장됩니다.
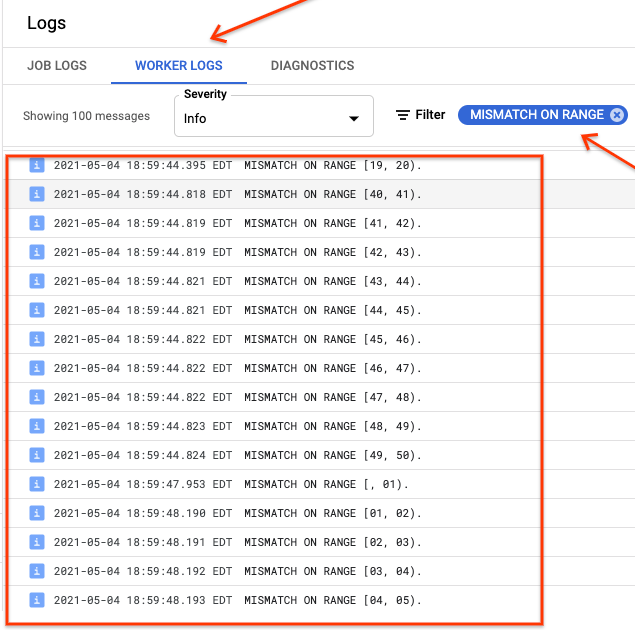
가져오기 작업을 다시 시도하거나 출력 파일을 읽는 스크립트를 작성하여 불일치가 발생한 위치를 확인할 수 있습니다. 출력 파일의 각 줄은 불일치 범위의 직렬화된 JSON 레코드입니다.
Bigtable에 쓰기 라우팅
클러스터의 각 테이블에 대한 데이터를 검증한 후에는 모든 해당 트래픽을 Bigtable로 라우팅하기 위해 애플리케이션을 구성한 다음 HBase 인스턴스를 지원 중단합니다.
마이그레이션이 완료되면 HBase 인스턴스에서 스냅샷을 삭제할 수 있습니다.
다음 단계
- Cloud Storage 자세히 알아보기