Migrer d'Apache Cassandra vers Bigtable
Ce document vous guide tout au long du processus de migration des données d'Apache Cassandra vers Bigtable avec un minimum d'interruptions. Elle explique comment utiliser des outils Open Source, tels que l'adaptateur de proxy Cassandra vers Bigtable ou le client Cassandra vers Bigtable pour Java, afin d'effectuer la migration. Avant de commencer, assurez-vous de maîtriser Bigtable pour les utilisateurs de Cassandra.
Choisir une approche de migration
Vous pouvez migrer d'Apache Cassandra vers Bigtable en utilisant l'une des approches suivantes :
- L'adaptateur de proxy Cassandra vers Bigtable vous permet de connecter des applications basées sur Cassandra à Bigtable sans modifier les pilotes Cassandra. Cette approche est idéale pour les applications qui nécessitent des modifications minimales du code.
- Le client Cassandra vers Bigtable pour Java vous permet de vous intégrer directement à Bigtable et de remplacer vos pilotes Cassandra. Cette approche est idéale pour les applications qui nécessitent des performances et une flexibilité élevées.
Adaptateur de proxy Cassandra vers Bigtable
L'adaptateur de proxy Cassandra vers Bigtable vous permet de connecter des applications basées sur Cassandra à Bigtable. L'adaptateur de proxy fonctionne comme une interface Cassandra compatible avec les câbles et permet à votre application d'interagir avec Bigtable à l'aide de CQL. L'utilisation de l'adaptateur de proxy ne nécessite pas de modifier les pilotes Cassandra, et les ajustements de configuration sont minimes.
Pour configurer l'adaptateur de proxy, consultez Adaptateur de proxy Cassandra vers Bigtable.
Pour savoir quelles versions de Cassandra sont compatibles avec l'adaptateur de proxy, consultez Versions de Cassandra compatibles.
Limites
L'adaptateur de proxy Cassandra vers Bigtable offre une compatibilité limitée avec certains types de données, fonctions, requêtes et clauses.
Pour en savoir plus, consultez Proxy Cassandra vers Bigtable : limites.
Espace de clés Cassandra
Un espace de clés Cassandra stocke vos tables et gère les ressources de la même manière qu'une instance Bigtable. L'adaptateur de proxy Cassandra vers Bigtable gère la dénomination des espaces de clés de manière transparente, ce qui vous permet d'effectuer des requêtes à l'aide des mêmes espaces de clés. Toutefois, vous devez créer une instance Bigtable pour regrouper logiquement vos tables. Vous devez également configurer la réplication Bigtable séparément.
Compatibilité avec le LDD
L'adaptateur de proxy Cassandra vers Bigtable est compatible avec les opérations LDD (langage de définition de données). Les opérations LDD vous permettent de créer et de gérer des tables directement à l'aide de commandes CQL. Nous vous recommandons cette approche pour configurer votre schéma, car elle est semblable à SQL, mais vous n'avez pas besoin de définir votre schéma dans des fichiers de configuration, puis d'exécuter des scripts pour créer des tables.
Les exemples suivants montrent comment l'adaptateur de proxy Cassandra vers Bigtable est compatible avec les opérations LDD :
Pour créer une table Cassandra à l'aide de CQL, exécutez la commande
CREATE TABLE:CREATE TABLE keyspace.table ( id bigint, name text, age int, PRIMARY KEY ((id), name) );Pour ajouter une colonne à la table, exécutez la commande
ALTER TABLE:ALTER TABLE keyspace.table ADD email text;Pour supprimer une table, exécutez la commande
DROP TABLE:DROP TABLE keyspace.table;
Pour en savoir plus, consultez Prise en charge du LDD pour la création de schémas (méthode recommandée).
Compatibilité avec le LMD
L'adaptateur de proxy Cassandra vers Bigtable est compatible avec les opérations LMD (langage de manipulation de données) telles que INSERT, DELETE, UPDATE et SELECT.
Pour exécuter les requêtes LMD brutes, toutes les valeurs, à l'exception des valeurs numériques, doivent être entre guillemets simples, comme indiqué dans les exemples suivants :
SELECT * FROM keyspace.table WHERE name='john doe';INSERT INTO keyspace.table (id, name) VALUES (1, 'john doe');
Effectuer une migration sans temps d'arrêt
Vous pouvez utiliser l'adaptateur de proxy Cassandra vers Bigtable avec l'outil de proxy Zero Downtime Migration (ZDM) Open Source et l'outil Cassandra Data Migrator pour migrer des données avec un temps d'arrêt minimal.
Le schéma suivant illustre les étapes de la migration de Cassandra vers Bigtable à l'aide de l'adaptateur de proxy :
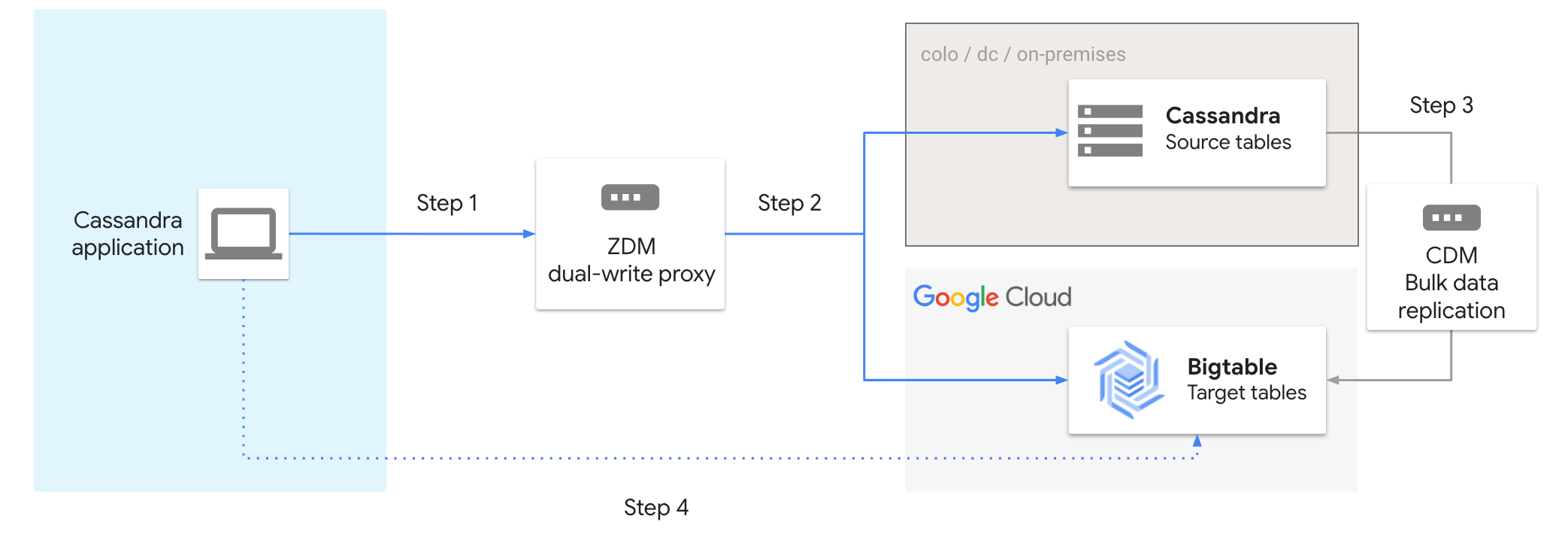
Pour migrer Cassandra vers Bigtable, procédez comme suit :
- Connectez votre application Cassandra à l'outil proxy ZDM.
- Activez les doubles écritures dans Cassandra et Bigtable.
- Migrez les données de manière groupée à l'aide de l'outil Cassandra Data Migrator.
- Validez votre migration. Une fois la validation effectuée, vous pouvez mettre fin à la connexion à Cassandra et vous connecter directement à Bigtable.
Lorsque vous utilisez l'adaptateur de proxy avec l'outil de proxy ZDM, les fonctionnalités de migration suivantes sont compatibles :
- Écriture double : maintenir la disponibilité des données pendant la migration
- Lectures asynchrones : mettez à l'échelle et testez la résistance de votre instance Bigtable
- Vérification et reporting automatisés des données : assurez l'intégrité des données tout au long du processus.
- Mappage des données : mappez les champs et les types de données pour répondre à vos normes de production.
Pour vous entraîner à migrer Cassandra vers Bigtable, consultez l'atelier de programmation Migration de Cassandra vers Bigtable avec un proxy Dual-Write.
Client Cassandra vers Bigtable pour Java
Vous pouvez effectuer une intégration directe à Bigtable et remplacer vos pilotes Cassandra. La bibliothèque cliente Cassandra vers Bigtable pour Java vous permet d'intégrer des applications Java basées sur Cassandra à Bigtable à l'aide de CQL.
Pour obtenir des instructions sur la création de la bibliothèque et l'inclusion de la dépendance dans le code de l'application, consultez Client Cassandra vers Bigtable pour Java.
L'exemple suivant montre comment configurer votre application avec le client Cassandra vers Bigtable pour Java :
Comprendre les performances
Bigtable est conçu pour un haut débit, une faible latence et une évolutivité massive. Il peut gérer des millions de requêtes par seconde sur des pétaoctets de données. Lorsque vous migrez depuis Cassandra à l'aide du client Cassandra vers Bigtable pour Java ou de l'adaptateur de proxy Cassandra vers Bigtable, tenez compte des implications suivantes en termes de performances :
Latence du client et du proxy
Les deux approches de migration entraînent une surcharge de performances minimale. Ils servent de couche de traduction entre le langage de requête Cassandra (CQL) et l'API Bigtable Data, qui est optimisée pour l'efficacité.
Performances avec les types de collecte Cassandra
Si votre modèle de données Cassandra utilise des types de collections tels que des mappages, des ensembles ou des listes pour implémenter des schémas dynamiques, Bigtable peut gérer efficacement ces modèles. L'adaptateur de proxy et le client pour Java mappent ces opérations de collecte au modèle de données sous-jacent de Bigtable, qui est bien adapté aux ensembles de données épars et larges.
Les opérations au niveau des éléments de ces collections sont très efficaces. Cela inclut les actions suivantes :
- Pour lire ou écrire une seule valeur dans une carte.
- Pour ajouter ou supprimer un élément d'un ensemble.
- Pour ajouter un élément à la fin ou au début d'une liste.
Bigtable optimise ces types d'opérations ponctuelles sur des éléments de collection individuels. Leurs performances sont identiques à celles des opérations sur les colonnes scalaires standards.
Effectuer un benchmark de votre charge de travail
Les performances de Bigtable peuvent varier en fonction de votre charge de travail, de la conception de votre schéma, des modèles d'accès aux données et de la configuration de votre cluster. Pour obtenir des métriques de performances précises pour votre cas d'utilisation et vous assurer que Bigtable répond à vos exigences spécifiques, nous vous recommandons de comparer vos charges de travail Cassandra à Bigtable à l'aide de l'une des approches de migration.
Pour en savoir plus sur les bonnes pratiques concernant les performances de Bigtable, consultez Analyser les performances.
Outils Open Source Cassandra supplémentaires
La compatibilité du proxy adaptateur Cassandra vers Bigtable avec CQL vous permet d'utiliser des outils supplémentaires dans l'écosystème Open Source Cassandra. Voici quelques exemples d'outils :
- Cqlsh : le shell CQL vous permet de vous connecter directement à Bigtable via l'adaptateur de proxy. Vous pouvez l'utiliser pour le débogage et la recherche rapide de données à l'aide de CQL.
- Cassandra Data Migrator (CDM) : cet outil basé sur Spark est adapté à la migration de grands volumes de données historiques (jusqu'à des milliards de lignes). Cet outil fournit des fonctionnalités de validation, de création de rapports de différences et de relecture. Il est également entièrement compatible avec l'adaptateur de proxy.