Migrar do DynamoDB para o Bigtable
O Bigtable e o DynamoDB são armazenamentos de chave-valor distribuídos que podem oferecer suporte a milhões de consultas por segundo (QPS), fornecer armazenamento que aumenta até petabytes de dados e tolerar falhas de nós.
Este documento é destinado a desenvolvedores do DynamoDB e administradores de banco de dados que querem migrar para o Bigtable. Também é útil ao projetar aplicativos para uso com o Bigtable como um repositório de dados.
Para começar, use uma ferramenta de migração fornecida pelo Google que ajuda você a migrar do DynamoDB para o Bigtable. Nesta página, descrevemos a ferramenta de migração, comparamos os dois sistemas de banco de dados e descrevemos a arquitetura subjacente e os detalhes de interação que são diferentes e importantes de entender antes da migração.
Começar a usar a ferramenta de migração do DynamoDB para o Bigtable
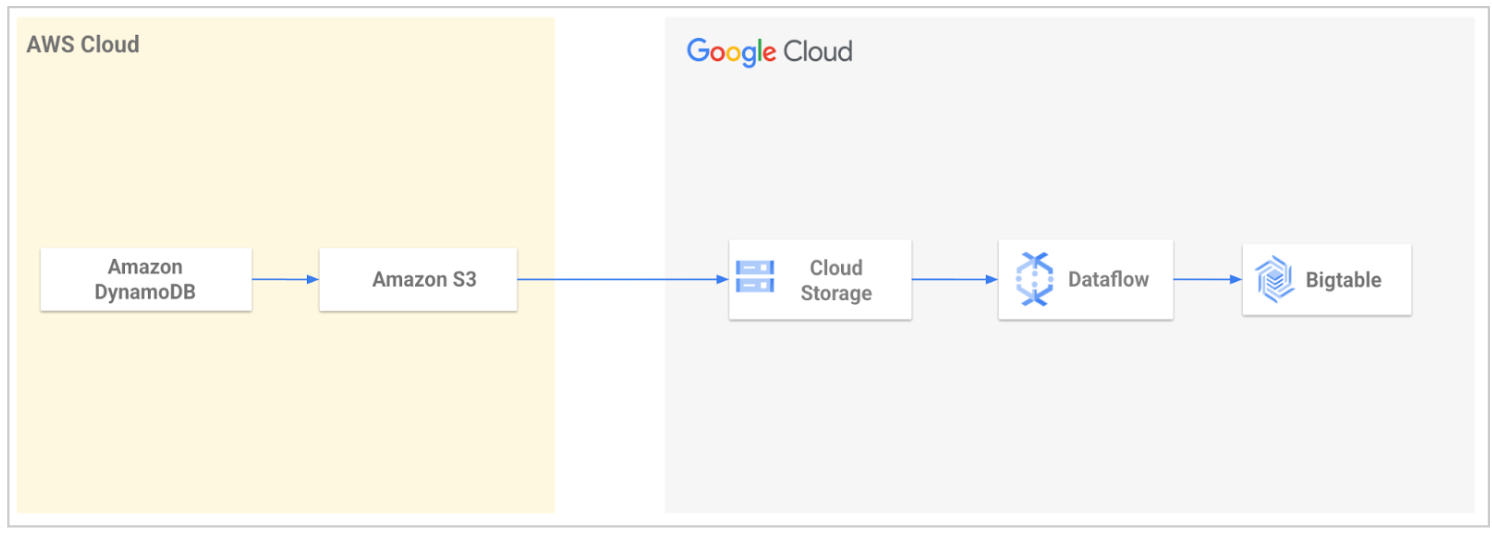
Uma ferramenta de migração de código aberto é fornecida pelos Google Cloud Serviços profissionais para simplificar a migração de dados do DynamoDB para o Bigtable. A ferramenta automatiza o processo de importação dos dados para o Google Cloud e, em seguida, carrega no Bigtable.
Com a ferramenta, você exporta a tabela do DynamoDB e a transfere para o Cloud Storage. A ferramenta lê os arquivos exportados do bucket do Cloud Storage e usa um modelo do Dataflow para transformar os dados de modo que eles sejam compatíveis com o Bigtable. Essa transformação inclui o mapeamento de atributos do DynamoDB para linhas do Bigtable. Em seguida, o job do Dataflow grava os dados transformados na tabela do Bigtable.
Para mais informações ou para começar, consulte Utilitário de migração do DynamoDB para o Bigtable.
Comparação entre o DynamoDB e o Bigtable
Esta seção examina as semelhanças e diferenças entre o DynamoDB e o Bigtable.
Plano de controle
No DynamoDB e no Bigtable, o plano de controle permite configurar a capacidade e configurar e gerenciar recursos. O DynamoDB é um produto sem servidor, e o nível mais alto de interação com ele é a tabela. No modo de capacidade provisionada, é aqui que você provisiona as unidades de solicitação de leitura e gravação, seleciona as regiões e a replicação e gerencia os backups. O Bigtable não é um produto sem servidor. Você precisa criar uma instância com um ou mais clusters, cuja capacidade é determinada pelo número de nós que eles têm. Para mais detalhes sobre esses recursos, consulte Instâncias, clusters e nós.
A tabela a seguir compara os recursos do plano de controle para DynamoDB e Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tabela : uma coleção de itens com uma chave primária definida. As tabelas têm configurações para backups, replicação e capacidade. | Instância:um grupo de clusters do Bigtable em diferentes Google Cloud zonas ou regiões, entre as quais ocorrem replicação e roteamento de conexão. As políticas de replicação são definidas no nível da instância. Cluster:um grupo de nós na mesma zona geográfica do Google Cloud , idealmente colocalizado com o servidor de aplicativos por motivos de latência e replicação. A capacidade é gerenciada ajustando o número de nós em cada cluster. Tabela: uma organização lógica de valores indexados pela chave de linha. Os backups são controlados no nível da tabela. |
Unidade de capacidade de leitura (RCU) e unidade de capacidade de gravação (WCU)
: unidades que permitem leituras ou gravações por segundo com tamanho de payload fixo. Você recebe cobranças por unidades de leitura ou gravação para cada operação com tamanhos de payload maiores.As operações UpdateItem consomem a capacidade de gravação usada para o
maior tamanho de um item atualizado, antes ou depois da atualização,
mesmo que a atualização envolva um subconjunto dos atributos do item. |
Nó:um recurso de computação virtual responsável por ler e gravar dados. O número de nós que um cluster tem se traduz em limites de capacidade de leitura, gravação e verificação. É possível
ajustar o número de nós, dependendo da combinação das suas
metas de latência, contagem de solicitações e tamanho do payload. Os nós de SSD oferecem a mesma taxa de transferência para leituras e gravações, ao contrário da diferença significativa entre RCU e WCU. Para mais informações, consulte Desempenho em cargas de trabalho típicas. |
| Partição : um bloco de linhas contíguas, respaldado por unidades de estado sólido (SSDs) alocadas com nós. Cada partição está sujeita a um limite rígido de 1.000 WCUs, 3.000 RCUs e 10 GB de dados. |
Tablet : um bloco de linhas contíguas apoiado pelo meio de armazenamento escolhido (SSD ou HDD). As tabelas são fragmentadas em blocos para equilibrar a carga de trabalho. Os blocos não são armazenados em nós no Bigtable, mas sim no sistema de arquivos distribuídos do Google, que permite a redistribuição rápida de dados ao escalonar e oferece mais durabilidade ao manter várias cópias. |
| Tabelas globais : uma maneira de aumentar a disponibilidade e a durabilidade dos dados propagando automaticamente as mudanças em várias regiões. | Replicação : uma maneira de aumentar a disponibilidade e a durabilidade dos dados propagando automaticamente as mudanças em várias regiões ou zonas na mesma região. |
| Não relevante (N/A) | Perfil de aplicativo : configurações que informam ao Bigtable como encaminhar uma chamada da API do cliente para o cluster apropriado na instância. Também é possível usar um perfil do app como tag para segmentar métricas de atribuição. |
Replicação geográfica
A replicação é usada para atender aos requisitos dos clientes para o seguinte:
- Alta disponibilidade para continuidade dos negócios em caso de falha zonal ou regional.
- Colocar os dados do serviço perto dos usuários finais para atendimento de baixa latência em qualquer lugar do mundo.
- Isolamento de carga de trabalho quando você precisa implementar uma carga de trabalho em lote em um cluster e usar a replicação para veicular clusters.
O Bigtable é compatível com clusters replicados em quantas zonas estiverem disponíveis em até 8 Google Cloud regiões em que o Bigtable está disponível. A maioria das regiões tem três zonas. Para mais informações, consulte Regiões e zonas.
O Bigtable replica automaticamente os dados entre clusters em uma topologia multi-primária, o que significa que você pode ler e gravar em qualquer cluster. A replicação do Bigtable tem consistência eventual. Para mais detalhes, consulte a Visão geral da replicação.
O DynamoDB oferece tabelas globais para oferecer suporte à replicação de tabelas em várias regiões. As tabelas globais são multi-primárias e replicadas automaticamente em todas as regiões. A replicação tem consistência eventual.
A tabela a seguir lista os conceitos de replicação e descreve a disponibilidade deles no DynamoDB e no Bigtable.
| Propriedade | DynamoDB | Bigtable |
|---|---|---|
| Replicação multi-primária | Sim. É possível ler e gravar em qualquer tabela global. |
Sim. É possível ler e gravar em qualquer cluster do Bigtable. |
| Modelo de consistência | Consistência eventual. Consistência na leitura das gravações no nível regional para tabelas globais. |
Consistência eventual. Consistência na leitura das gravações no nível do cluster para todas as tabelas, desde que você envie leituras e gravações para o mesmo cluster. |
| Latência de replicação | Não há contrato de nível de serviço (SLA). Segundos |
Sem SLA. Segundos |
| Granularidade da configuração | Nível da tabela. | Nível da instância. Uma instância pode conter várias tabelas. |
| Implementação | Crie uma tabela global com uma réplica em cada região selecionada. Nível regional. Replicação automática em réplicas ao converter uma tabela em uma tabela global. As tabelas precisam ter o DynamoDB Streams ativado, com o stream contendo as imagens novas e antigas do item. Exclua uma região para remover a tabela global nela. |
Crie uma instância com mais de um cluster. A replicação é automática em todos os clusters dessa instância. Nível zonal. Adicione e remova clusters de uma instância do Bigtable. |
| Opções de replicação | Por tabela. | Por instância. |
| Roteamento e disponibilidade de tráfego | O tráfego é roteado para a réplica geográfica mais próxima. Em caso de falha, aplique uma lógica de negócios personalizada para determinar quando redirecionar solicitações para outras regiões. |
Use perfis de aplicativo para configurar
políticas de roteamento de tráfego de cluster. Use o roteamento de vários clusters para encaminhar o tráfego automaticamente para o cluster íntegro mais próximo. Em caso de falha, o Bigtable oferece suporte ao failover automático entre clusters para alta disponibilidade. |
| Escalonamento | A capacidade de gravação em unidades de solicitação de gravação replicada (R-WRU) é sincronizada entre as réplicas. A capacidade de leitura em unidades de capacidade de leitura replicadas (R-RCU) é por réplica. |
É possível escalonar clusters de forma independente adicionando ou removendo nós de cada cluster replicado conforme necessário. |
| Custo | As WRUs de resposta custam 50% mais do que as WRUs comuns. | Você recebe uma cobrança pelos nós e pelo armazenamento de cada cluster. Não há custos de replicação de rede para a replicação regional entre zonas. Os custos são incorridos quando a replicação é entre regiões ou continentes. |
| SLA | 99,999% | 99,999% |
Plano de dados
A tabela a seguir compara conceitos de modelo de dados para DynamoDB e Bigtable. Cada linha na tabela descreve recursos semelhantes. Por exemplo, um item no DynamoDB é semelhante a uma linha no Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Item : um grupo de atributos que é identificado de forma exclusiva entre todos os outros itens pela chave primária. O tamanho máximo permitido é 400 KB. | Linha : uma única entidade identificada pela chave de linha. O tamanho máximo permitido é 256 MB. |
| N/A | Grupo de colunas:um namespace especificado pelo usuário que agrupa colunas. |
| Atributo : um agrupamento de um nome e um valor. Um valor de atributo pode ser um escalar, um conjunto ou um tipo de documento. Não há um limite explícito para o tamanho do atributo. No entanto, como cada item é limitado a 400 KB, para um item que tem apenas um atributo, o atributo pode ter até 400 KB menos o tamanho ocupado pelo nome do atributo. | Qualificador de coluna : o identificador exclusivo de uma coluna em um grupo de colunas. O identificador completo de uma coluna é expresso como grupo-de-colunas:qualificador-de-coluna. Os qualificadores de coluna são classificados lexicograficamente dentro do grupo de colunas. O tamanho máximo permitido para um qualificador de coluna é de 16 KB. Célula:uma célula contém os dados de uma determinada linha, coluna e carimbo de data/hora. Uma célula contém um valor que pode ter até 100 MB. |
| Chave primária : um identificador exclusivo de um item em uma tabela. Pode ser uma chave de partição ou uma chave composta. Chave de partição: uma chave primária simples, composta por um atributo. Isso determina a partição física em que o item está localizado. O tamanho máximo permitido é de 2 KB. Chave de classificação: uma chave que determina a ordenação das linhas em uma partição. O tamanho máximo permitido é 1 KB. Chave composta: uma chave primária composta por duas propriedades, a chave de partição e uma chave de classificação ou um atributo de intervalo. |
Chave de linha : um identificador exclusivo de um item em uma tabela.
Normalmente representado por uma concatenação de valores e delimitadores.
O tamanho máximo permitido é 4 KB. Os qualificadores de coluna podem ser usados para oferecer um comportamento equivalente ao da chave de classificação do DynamoDB. As chaves compostas podem ser criadas usando chaves de linha concatenadas e qualificadores de coluna. Para mais detalhes, consulte o exemplo de tradução de esquema na seção "Design de esquema" deste documento. |
| Time to live : os carimbos de data/hora por item determinam quando um item não é mais necessário. Depois da data e hora do carimbo de data/hora especificado, o item é excluído da tabela sem consumir nenhuma capacidade de gravação. | Coleta de lixo : os carimbos de data/hora por célula determinam quando um item não é mais necessário. A coleta de lixo exclui itens expirados durante um processo em segundo plano chamado compactação. As políticas de coleta de lixo são definidas no nível do grupo de colunas e podem excluir itens não apenas com base na idade, mas também de acordo com o número de versões que o usuário quer manter. Não é necessário acomodar a capacidade de compactação ao dimensionar os clusters. |
| Índice secundário global : uma tabela que contém atributos selecionados da tabela de base, organizada por uma chave primária diferente da tabela. A chave de índice não precisa incluir nenhum dos atributos de chave da tabela. Não precisa ter o mesmo esquema de chave da tabela. O DynamoDB atualiza os índices secundários globais de forma assíncrona. | Índice secundário assíncrono : para consultar os mesmos dados usando diferentes padrões ou atributos de pesquisa, você pode criar um índice secundário assíncrono. Esse tipo de índice contém atributos selecionados da tabela de base. Esses atributos são organizados por uma chave diferente da chave da tabela. O comportamento é semelhante aos índices secundários globais do DynamoDB. |
Operações
Com as operações do plano de dados, é possível realizar ações de criação, leitura, atualização e exclusão (CRUD) em dados de uma tabela. A tabela a seguir compara operações semelhantes do plano de dados para o DynamoDB e o Bigtable.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsO Bigtable trata as operações de gravação como upserts. |
UpdateItem
|
O Bigtable trata as operações de gravação como upserts. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (intervalo, prefixo, varredura inversa)O Bigtable oferece suporte a varreduras eficientes por prefixo de chave de linha, padrão de expressão regular ou intervalo de chave de linha para frente ou para trás. |
Tipos de dados
O Bigtable e o DynamoDB não têm esquema. As colunas podem ser definidas no momento da gravação sem nenhuma imposição em toda a tabela para existência de colunas ou tipos de dados. Da mesma forma, um determinado tipo de dados de coluna ou atributo pode variar de uma linha ou item para outro. No entanto, as APIs do DynamoDB e do Bigtable lidam com tipos de dados de maneiras diferentes.
Cada solicitação de gravação do DynamoDB inclui uma definição de tipo para cada atributo, que é retornada com a resposta para solicitações de leitura.
O Bigtable trata tudo como bytes e espera que o código do cliente saiba o tipo e a codificação para que o cliente possa analisar as respostas corretamente. Uma exceção são as operações de incremento, que interpretam os valores como números inteiros com sinal big-endian de 64 bits.
A tabela a seguir compara as diferenças nos tipos de dados entre o DynamoDB e o Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tipos escalares : retornados como tokens descritor de tipo de dados na resposta do servidor. | Bytes : são convertidos para os tipos pretendidos no aplicativo cliente. Increment interpreta o valor como um número inteiro assinado big-endian de 64 bits |
| Conjunto : uma coleção não classificada de elementos exclusivos. | Grupo de colunas : é possível usar qualificadores de coluna como nomes de membros do conjunto e, para cada um, fornecer um único byte 0 como valor da célula. Os membros do conjunto são classificados lexicograficamente dentro da família de colunas. |
| Mapa : uma coleção não classificada de pares de chave-valor com chaves exclusivas. | Grupo de colunas Use o qualificador de coluna como chave de mapa e valor da célula para o valor. As chaves de mapa são classificadas lexicograficamente. |
| Lista : uma coleção classificada de itens. | Qualificador de coluna Use o carimbo de data/hora de inserção para alcançar o equivalente ao comportamento list_append, o inverso do carimbo de data/hora de inserção para prepend. |
Design de esquema
Uma consideração importante no design de esquema é como os dados são armazenados. Entre as principais diferenças entre o Bigtable e o DynamoDB estão as seguintes:
- Atualizações em valores únicos
- Classificação de dados
- Controle de versões de dados
- Armazenamento de valores grandes
Atualizações em valores únicos
As operações UpdateItem no DynamoDB consomem a capacidade de gravação para o maior dos tamanhos de item "antes" e "depois", mesmo que a atualização envolva um subconjunto dos atributos do item. Isso significa que, no DynamoDB, você pode colocar colunas atualizadas com frequência em linhas separadas, mesmo que logicamente elas pertençam à mesma linha com outras colunas.
O Bigtable pode atualizar uma célula com a mesma eficiência, seja ela a única coluna em uma determinada linha ou uma entre milhares. Para mais detalhes, consulte Gravações simples.
Classificação de dados
O DynamoDB faz hash e distribui aleatoriamente as chaves de partição, enquanto o Bigtable armazena as linhas em ordem lexicográfica por chave de linha e deixa qualquer hash para o usuário.
A distribuição aleatória de chaves não é ideal para todos os padrões de acesso. Ela reduz o risco de intervalos de linhas ativas, mas torna caros e ineficientes os padrões de acesso que envolvem verificações que cruzam limites de partição. Essas verificações sem limites são comuns, especialmente para casos de uso que têm uma dimensão de tempo.
Para processar esse tipo de padrão de acesso (verificações que cruzam limites de partição), é necessário um índice secundário no DynamoDB, mas não no Bigtable. Embora seja possível projetar a chave de linha lexicográfica no Bigtable para processar muitos padrões de verificação de forma eficiente, o Bigtable também oferece suporte a índices secundários assíncronos que você implementa como visualizações materializadas contínuas para fornecer pesquisas eficientes e eventualmente consistentes para padrões de consulta alternativos. Da mesma forma, no DynamoDB, as operações de consulta e verificação são limitadas a 1 MB de dados verificados, o que exige paginação além desse limite. O Bigtable não tem esse limite.
Apesar das chaves de partição distribuídas aleatoriamente, o DynamoDB ainda pode ter partições ativas se uma chave de partição escolhida não distribuir uniformemente o tráfego que está afetando negativamente a capacidade de transferência. Para resolver esse problema, o DynamoDB recomenda o write-sharding, que divide aleatoriamente as gravações em vários valores de chave de partição lógica.
Para aplicar esse padrão de design, crie um número aleatório de um conjunto fixo (por exemplo, de 1 a 10) e use esse número como a chave de partição lógica. Como você está randomizando a chave de partição, as gravações na tabela são distribuídas de maneira uniforme em todos os valores da chave de partição.
O Bigtable se refere a esse procedimento como adição de sal à chave, e ele pode ser uma maneira eficaz de evitar blocos ativos.
Controle de versões de dados
Cada célula do Bigtable tem um carimbo de data/hora, e o mais recente é sempre o valor padrão de qualquer coluna. Um caso de uso comum para carimbos de data/hora é o controle de versões: gravar uma nova célula em uma coluna que é diferenciada das versões anteriores dos dados para essa linha e coluna pelo carimbo de data/hora.
O DynamoDB não tem esse conceito e exige designs de esquema complexos para oferecer suporte ao controle de versões. Essa abordagem envolve a criação de duas cópias de cada item: uma com um prefixo de número de versão zero, como v0_, no início da chave de classificação, e outra com um prefixo de número de versão um, como v1_. Sempre que o item for atualizado, use o próximo prefixo de versão mais alto na
chave de classificação da versão atualizada e copie o conteúdo atualizado para o item
com prefixo de versão zero. Isso garante que a versão mais recente de qualquer item possa
ser localizada usando o prefixo zero. Essa estratégia não apenas exige
lógica do lado do aplicativo para manutenção, mas também torna as gravações de dados muito caras e
lentas, porque cada gravação requer uma leitura do valor anterior mais duas
gravações.
Transações com várias linhas x grande capacidade de linhas
O Bigtable não é compatível com transações de várias linhas. No entanto, como ele permite armazenar linhas muito maiores do que os itens podem ser no DynamoDB, muitas vezes é possível obter a transacionalidade pretendida projetando seus esquemas para agrupar itens relevantes em uma chave de linha compartilhada. Para um exemplo que ilustra essa abordagem, consulte Padrão de design de tabela única.
Como armazenar valores grandes
Como um item do DynamoDB, que é análogo a uma linha do Bigtable, é limitado a 400 KB, o armazenamento de valores grandes exige dividir o valor entre itens ou armazenar em outras mídias, como o S3. Ambas as abordagens adicionam complexidade ao aplicativo. Por outro lado, uma célula do Bigtable pode armazenar até 100 MB, e uma linha do Bigtable pode ter até 256 MB.
Exemplos de tradução de esquema
Os exemplos nesta seção traduzem esquemas do DynamoDB para o Bigtable considerando as diferenças no design do esquema de chave.
Migrar esquemas básicos
Os catálogos de produtos são um bom exemplo para demonstrar o padrão básico de chave-valor. Confira a seguir como um esquema desse tipo pode ser exibido no DynamoDB.
| Chave primária | Atributos | |||
|---|---|---|---|---|
| Chave de partição | Chave de classificação | Descrição | Preço | Miniatura |
| chapéus | fedoras#brandA | Feito de lã premium… | 30 | https://storage… |
| chapéus | fedoras#brandB | Tela resistente à água e durável feita para… | 28 | https://storage… |
| chapéus | newsboy#brandB | Adicione um toque de charme vintage ao seu visual do dia a dia. | 25 | https://storage… |
| calçados | tênis#marcaA | Saia com estilo e conforto com… | 40 | https://storage… |
| calçados | tênis#brandB | Recursos clássicos com materiais contemporâneos… | 50 | https://storage… |
Para essa tabela, o mapeamento do DynamoDB para o Bigtable é simples: você converte a chave primária composta do DynamoDB em uma chave de linha composta do Bigtable. Você cria um grupo de colunas (SKU) que contém o mesmo conjunto de colunas.
| SKU | |||
|---|---|---|---|
| Chave de linha | Descrição | Preço | Miniatura |
| chapéus#fedoras#brandA | Feito de lã premium… | 30 | https://storage… |
| chapéus#fedoras#marcaB | Tela resistente à água e durável feita para… | 28 | https://storage… |
| hats#newsboy#brandB | Adicione um toque de charme vintage ao seu visual do dia a dia. | 25 | https://storage… |
| shoes#sneakers#brandA | Saia com estilo e conforto com… | 40 | https://storage… |
| shoes#sneakers#brandB | Recursos clássicos com materiais contemporâneos… | 50 | https://storage… |
Padrão de design de tabela única
Um padrão de design de tabela única reúne o que seriam várias tabelas em um banco de dados relacional em uma única tabela no DynamoDB. Você pode usar a abordagem do exemplo anterior e duplicar esse esquema como está no Bigtable. No entanto, é melhor resolver os problemas do esquema no processo.
Nesse esquema, a chave de partição contém o ID exclusivo de um vídeo, o que ajuda a alocar todos os atributos relacionados a ele para acesso mais rápido. Devido às limitações de tamanho de itens do DynamoDB, não é possível colocar um número ilimitado de comentários de texto livre em uma única linha. Portanto, uma chave de classificação com o padrão
VideoComment#reverse-timestamp é usada para tornar cada comentário uma linha separada
na partição, classificada em ordem cronológica inversa.
Suponha que esse vídeo tenha 500 comentários e o proprietário queira removê-lo. Isso significa que todos os comentários e atributos do vídeo também precisam ser excluídos. Para fazer isso no DynamoDB, é necessário verificar todas as chaves nessa partição e emitir várias solicitações de exclusão, iterando por cada uma delas. O DynamoDB é compatível com transações de várias linhas, mas esta solicitação de exclusão é muito grande para ser feita em uma única transação.
| Chave primária | Atributos | |||
|---|---|---|---|---|
| Chave de partição | Chave de classificação | UploadDate | Formatos | |
| 0123 | Vídeo | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Conteúdo | |||
| Gostei muito. Os efeitos especiais são incríveis. | ||||
| VideoComment#86751345 | Conteúdo | |||
| Parece que há uma falha de áudio em 1:05. | ||||
| VideoStatsLikes | Count | |||
| 3 | ||||
| VideoStatsViews | Count | |||
| 156 | ||||
| 0124 | Vídeo | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Conteúdo | |||
| Compartilhei com todos os meus amigos. | ||||
| VideoComment#87616471 | Conteúdo | |||
| O estilo me lembra um diretor de cinema, mas não consigo identificar. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Modifique esse esquema durante a migração para simplificar o código e fazer solicitações de dados mais rápidas e baratas. As linhas do Bigtable têm uma capacidade muito maior do que os itens do DynamoDB e podem processar um grande número de comentários. Para lidar com um caso em que um vídeo recebe milhões de comentários, defina uma política de coleta de lixo para manter apenas um número fixo dos comentários mais recentes.
Como os contadores podem ser atualizados sem o custo de atualizar a linha inteira, não é necessário dividi-los. Você não precisa usar uma coluna "UploadDate" ou calcular um carimbo de data/hora invertido e usá-lo como chave de classificação, porque os carimbos de data/hora do Bigtable fornecem automaticamente os comentários ordenados cronologicamente de forma inversa. Isso simplifica muito o esquema. Se um vídeo for removido, você poderá remover transacionalmente a linha dele, incluindo todos os comentários, em uma única solicitação.
Por fim, como as colunas no Bigtable são ordenadas lexicograficamente, para otimizar, você pode renomear as colunas de forma que permita uma verificação rápida de intervalo (das propriedades do vídeo aos N comentários mais recentes) em uma única solicitação de leitura, que é o que você faria quando o vídeo fosse carregado. Depois, você pode passar pelo restante dos comentários à medida que o espectador rola a tela.
| Atributos | ||||
|---|---|---|---|---|
| Chave de linha | Formatos | Marcações com "Gostei" | visualizações | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | Gostei muito. Os efeitos especiais são incríveis. @
2023-09-10T19:01:15 Parece que há uma falha de áudio em 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | O estilo me lembra um diretor de cinema, mas não consigo identificar. @2023-10-12T07:08:51 | |
Padrão de projeto de lista de adjacência
Considere uma versão um pouco diferente desse design, que o DynamoDB geralmente chama de padrão de design de lista de adjacência.
| Chave primária | Atributos | |||
|---|---|---|---|---|
| Chave de partição | Chave de classificação | DateCreated | Detalhes | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
Nesta tabela, as chaves de classificação não são baseadas no tempo, mas sim em IDs de pagamento. Assim, é possível usar um padrão de coluna ampla diferente e fazer com que esses IDs sejam colunas separadas no Bigtable, com benefícios semelhantes ao exemplo anterior.
| Fatura | Pagamento | |||
|---|---|---|---|---|
| chave de linha | Detalhes | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| chave de linha | Detalhes | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Como você pode ver nos exemplos anteriores, com o design de esquema certo, o modelo de coluna larga do Bigtable pode ser bastante eficiente e oferecer muitos casos de uso que exigiriam transações caras de várias linhas, indexação secundária ou comportamento de exclusão em cascata em outros bancos de dados.
A seguir
- Leia sobre o design do esquema do Bigtable.
- Saiba mais sobre o emulador do Bigtable.
- Confira arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Confira o Centro de arquitetura do Cloud.