DynamoDB から Bigtable に移行する
Bigtable と DynamoDB は、数百万の秒間クエリ数(QPS)をサポートできる分散 Key-Value ストアであり、ペタバイト規模のデータまでスケールアップできるストレージを提供して、ノードの障害を許容できます。
このドキュメントは、Bigtable への移行を計画している DynamoDB デベロッパーとデータベース管理者を対象としています。また、データストアとして Bigtable を使用するアプリケーションを設計する場合にも役立ちます。
まず、Google 提供の移行ツールを使用して、DynamoDB から Bigtable への移行を行います。このページでは、移行ツールについて説明し、2 つのデータベース システムを比較します。また、移行前に理解しておくことが重要な、異なる基盤となるアーキテクチャと動作の詳細について説明します。
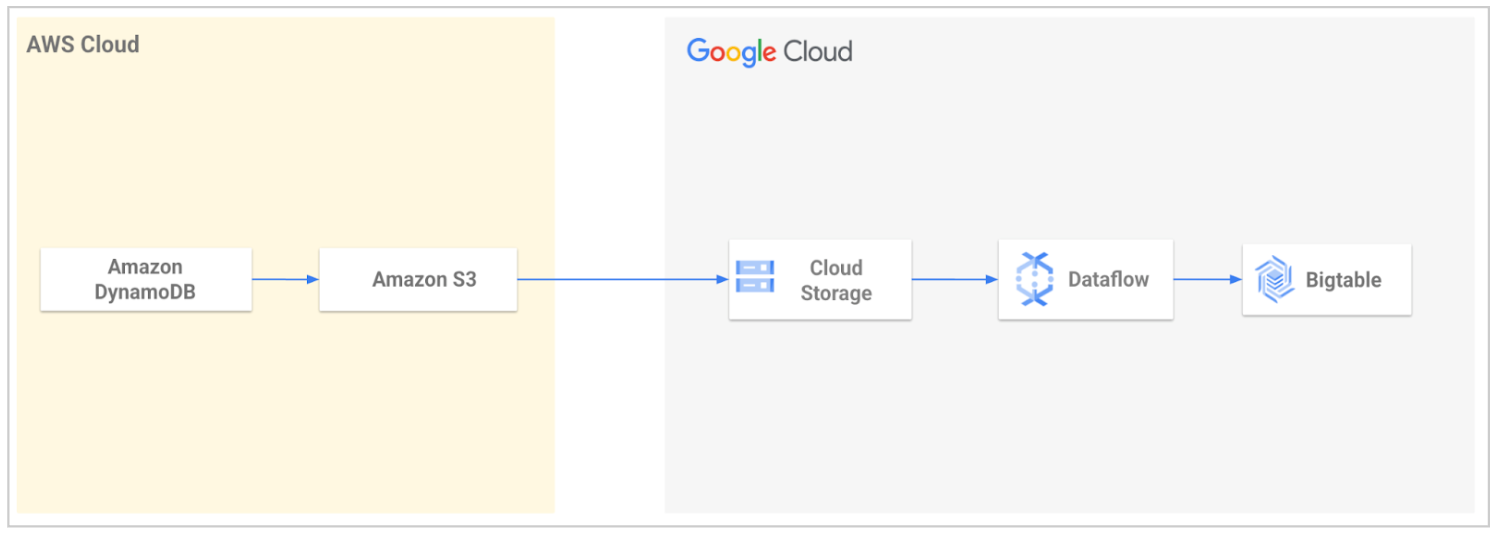
DynamoDB から Bigtable への移行ツールを使ってみる
Google Cloud Professional Services は、DynamoDB から Bigtable へのデータ移行を効率化するオープンソースの移行ツールを提供しています。このツールは、データを Google Cloud にインポートしてから Bigtable に読み込むプロセスを自動化します。
このツールを使用して、DynamoDB テーブルをエクスポートし、Cloud Storage に転送します。このツールは、Cloud Storage バケットからエクスポートされたファイルを読み取り、Dataflow テンプレートを使用して、Bigtable と互換性のあるデータに変換します。この変換には、DynamoDB 属性から Bigtable 行へのマッピングが含まれます。Dataflow ジョブは、変換されたデータを Bigtable テーブルに書き込みます。
詳細または使用を開始するには、DynamoDB から Bigtable への移行ユーティリティをご覧ください。
DynamoDB と Bigtable の比較
このセクションでは、DynamoDB と Bigtable の類似点と相違点について説明します。
コントロール プレーン
DynamoDB と Bigtable では、コントロール プレーンを使用して容量を構成し、リソースを設定して管理できます。DynamoDB はサーバーレス プロダクトであり、DynamoDB とのインタラクションの最上位レベルはテーブルレベルです。プロビジョニングされた容量モードでは、ここで読み取り / 書き込みリクエスト ユニットをプロビジョニングし、リージョンとレプリケーションを選択して、バックアップを管理します。Bigtable はサーバーレス プロダクトではありません。1 つ以上のクラスタを持つインスタンスを作成する必要があります。容量は、クラスタに含まれるノードの数によって決まります。これらのリソースの詳細については、インスタンス、クラスタ、ノードをご覧ください。
次の表は、DynamoDB と Bigtable のコントロール プレーン リソースを比較したものです。
| DynamoDB | Bigtable |
|---|---|
| テーブル: 主キーが定義されたアイテムのコレクション。テーブルには、バックアップ、レプリケーション、容量の設定があります。 | インスタンス: 異なる Google Cloud ゾーンやリージョンにある Bigtable クラスタのグループ。このクラスタ間では、レプリケーションや接続のルーティングが発生します。レプリケーション ポリシーはインスタンス レベルで設定されます。 クラスタ: 地理的に同じGoogle Cloud ゾーン、理想的にはレイテンシとレプリケーションの問題に対応するためにアプリケーション サーバーに配置された、ノードのグループ。容量は、各クラスタのノード数を調整することで管理されます。 テーブル: 行キーでインデックス付けされた値の論理構成。 バックアップはテーブルレベルで管理されます。 |
読み取り容量ユニット(RCU)と書き込み容量ユニット(WCU):
ペイロード サイズが固定された状態で、1 秒あたりの読み取りまたは書き込みを可能にする単位。ペイロード サイズが大きいオペレーションごとに、読み取りまたは書き込みユニットの料金が課金されます。UpdateItem オペレーションは、更新がアイテム属性のサブセットに関係する場合にも、更新された項目の最大サイズ(書き込み前または更新後)に使用された書き込み容量を消費します。 |
ノード: データを読み書きに関与する仮想コンピューティング リソース。クラスタによって、読み取り、書き込み、スキャンのスループット上限に換算されるノード数。レイテンシの目標、リクエスト数、ペイロード サイズの組み合わせに応じて、ノード数を調整できます。 RCU と WCU との有意差とは異なり、SSD ノードでは、読み取りや書き込みと同じスループットが供給されます。詳細については、通常のワークロードでのパフォーマンスをご覧ください。 |
| パーティション: ノードと同一場所に設置されたソリッド ステート ドライブ(SSD)によってバックアップされている連続行のブロック。 各パーティションは、1,000 個の WCU、3,000 個の RCU、10 GB のデータというハードリミットに従います。 |
タブレット: 最適なストレージ メディア(SSD または HDD)によってバックアップされる連続行のブロック。 ワークロードを調整するために、テーブルは複数のタブレットにシャーディングされます。タブレットは Bigtable のノードではなく、Google の分散ファイル システムに保存されます。これにより、スケーリング時にデータを迅速に再配布できます。また、複数のコピーを保持することで、耐久性を高めることができます。 |
| グローバル テーブル: 複数のリージョン間でデータ変更を自動的に伝達することで、データの可用性と耐久性を高める方法。 | レプリケーション: 複数のリージョンまたは同じリージョン内の複数のゾーンにデータの変更を自動的に伝達することで、データの可用性と耐久性を向上させる方法。 |
| 該当なし | アプリケーション プロファイル: クライアント API 呼び出しをインスタンス内の適切なクラスタに転送する方法を Bigtable に指示する設定。アプリ プロファイルをタグとして使用して、アトリビューションの指標をセグメント化することもできます。 |
地理的レプリケーション
レプリケーションは、次の顧客要件をサポートするために使用されます。
- ゾーンまたはリージョンの障害が発生した場合の事業継続のための高可用性。
- エンドユーザーのすぐ近くにサービスデータを配置することで、世界中のどこにいても低レイテンシでサービスを提供できます。
- 1 つのクラスタにバッチ ワークロードを実装し、サービスを提供するクラスタへのレプリケーションに依存する必要がある場合のワークロードの隔離。
Bigtable は、Bigtable が利用可能な最大 8 つのリージョンで利用可能な同じ数のゾーンの複製クラスタをサポートします。 Google Cloud ほとんどのリージョンには 3 つのゾーンがあります。詳細については、リージョンとゾーンをご覧ください。
Bigtable は、マルチプライマリ トポロジ内のクラスタ間で自動的にデータを複製します。つまり、任意のクラスタに対する読み取りと書き込みが可能です。Bigtable のレプリケーションには結果整合性があります。詳細については、レプリケーションの概要をご覧ください。
DynamoDB は、複数のリージョンにわたるテーブル レプリケーションをサポートするグローバル テーブルを提供します。グローバル テーブルはマルチプライマリであり、リージョン間で自動的に複製されます。レプリケーションには結果整合性があります。
次の表では、レプリケーションのコンセプトを一覧表示して、DynamoDB と Bigtable での可用性について説明します。
| プロパティ | DynamoDB | Bigtable |
|---|---|---|
| マルチプライマリ レプリケーション | はい。 任意のグローバル テーブルに対する読み取りと書き込が可能です。 |
はい。 任意の Bigtable クラスタに対する読み取りと書き込みが可能です。 |
| 整合性モデル | 結果整合性 グローバル テーブルのリージョン レベルで書き込み後読み取りの整合性。 |
結果整合性 すべてのテーブルのクラスタレベルで書き込み後読み取りの整合性。ただし、読み取りと書き込みの両方を同じクラスタに送信する。 |
| レプリケーション レイテンシ | サービスレベル契約(SLA)はありません。 数秒 |
サービスレベル契約(SLA)なし 数秒 |
| 構成の粒度 | テーブルレベル | インスタンス レベル インスタンスには複数のテーブルを含めることができます。 |
| 実装 | 選択した各リージョンにテーブル レプリカを含むグローバル テーブルを作成します。 地域単位。 テーブルをグローバル テーブルに変換して、レプリカ間で自動的にレプリケーションを行います。 テーブルでは、アイテムの新しいイメージと古いイメージの両方を含むストリームを使用して、DynamoDB Streams を有効にする必要があります。 リージョンを削除して、そのリージョンのグローバル テーブルを削除します。 |
複数のクラスタを含むインスタンスを作成する。 レプリケーションは、そのインスタンス内のクラスタ間で自動的に行われます。 ゾーンレベル。 Bigtable インスタンスのクラスタを追加または削除します。 |
| レプリケーションのオプション | テーブルごと。 | インスタンス単位。 |
| トラフィック ルーティングと可用性 | 最も近い地理的レプリカにルーティングされるトラフィック。 障害が発生した場合は、カスタム ビジネス ロジックを適用して、リクエストを他のリージョンにリダイレクトするタイミングを決定します。 |
アプリケーション プロファイルを使用して、クラスタ トラフィック ルーティング ポリシーを構成します。 複数クラスタ ルーティングを使用して、トラフィックを最も近い正常なクラスタに自動的にルーティングします。 障害が発生した場合、Bigtable は HA のクラスタ間の自動フェイルオーバーをサポートします。 |
| スケーリング | 複製された書き込みリクエスト ユニット(R-WRU)の書き込み容量は、レプリカ間で同期されます。 複製された読み取り容量ユニット(R-RCU)の読み取り容量はレプリカによります。 |
必要に応じて、複製された各クラスタのノードを追加または削除することで、クラスタを個別にスケーリングできます。 |
| 費用 | R-WRU の費用は通常の WRU の 50% 増しです。 | クラスタのノードとストレージごとに課金されます。 ゾーン間のリージョン レプリケーションにはネットワーク レプリケーション費用はかかりません。 レプリケーションがリージョン間または大陸間で行われると、費用が発生します。 |
| SLA | 99.999% | 99.999% |
データプレーン
次の表は、DynamoDB と Bigtable のデータモデルのコンセプトを比較したものです。テーブルの各行は、類似した機能を表しています。たとえば、DynamoDB のアイテムは Bigtable の行に似ています。
| DynamoDB | Bigtable |
|---|---|
| アイテム: プライマリ キーによって他のすべてのアイテム間で一意に識別できる属性のグループ。最大許容サイズは 400 KB です。 | 行: 行キーで識別される単一のエンティティ。許容される最大サイズは 256 MB です。 |
| 該当なし | 列ファミリー: 列をグループ化するユーザー指定の名前空間。 |
| 属性: 名前と値のグループ。属性値は、スカラー型、セット型、ドキュメント型にできます。属性サイズ自体に明示的な制限はありません。ただし、各アイテムは 400 KB に制限されているため、属性が 1 つしかないアイテムの場合、属性は最大 400 KB から属性名が占めたサイズを差し引いた値になります。 | 列修飾子: 列のための列ファミリー内の一意の識別子。列の完全な識別子は、列ファミリー(列修飾子)として表します。列修飾子は、列ファミリー内で辞書順に並べ替えられます。 列修飾子の最大許容サイズは 16 KB です。 セル: 特定の行、列、タイムスタンプのデータを保持します。セルには、最大 100 MB の 1 つの値が含まれます。 |
| 主キー: テーブル内のアイテムの一意の識別子。パーティション キーまたは複合キーにできます。 パーティション キー: 1 つの属性で構成される単純な主キー。これにより、アイテムが配置される物理パーティションが決まります。最大許容サイズは 2 KB です。 並べ替えキー: パーティション内の行の順序を決定するキー。最大許容サイズは 1 KB です。 複合キー: パーティション キーと並べ替えキーまたは範囲属性の 2 つのプロパティで構成される主キー。 |
行キー: テーブル内のアイテムの一意の識別子。通常、値と区切り文字の連結で表されます。最大許容サイズは 4 KB です。 列修飾子を使用して、DynamoDB の並べ替えキーと同等の動作を実現できます。 連結された行キーと列修飾子を使用して、複合キーを構築できます。 詳細については、このドキュメントのスキーマ設計セクションにあるスキーマ変換の例をご覧ください。 |
| 有効期間: アイテムごとのタイムスタンプによって、アイテムが不要になるタイミングが決まります。指定されたタイムスタンプの日時を過ぎると、書き込みスループットを消費することなく、項目がテーブルから削除されます。 | ガベージ コレクション: セルごとのタイムスタンプにより、アイテムが不要になったタイミングが特定されます。ガベージ コレクションは、コンパクションと呼ばれるバックグラウンド プロセスの間に期限切れのアイテムを削除します。ガベージ コレクション ポリシーは、列ファミリー レベルで設定され、アイテムの削除を、アイテムの年齢だけでなく、ユーザーが維持するバージョンの数に基づいて行うこともできます。クラスタのサイズ設定時に、圧縮の容量を考慮する必要はありません。 |
| グローバル セカンダリ インデックス: テーブルの主キーとは異なる主キーで編成された、ベーステーブルから選択された属性を含むテーブル。インデックス キーにテーブルのキー属性を含める必要はありません。テーブルと同じキー スキーマである必要はありません。DynamoDB は、グローバル セカンダリ インデックスを非同期で更新します。 | 非同期セカンダリ インデックス: 異なるルックアップ パターンまたは属性を使用して同じデータをクエリするには、非同期セカンダリ インデックスを作成します。このタイプのインデックスには、ベーステーブルから選択された属性が含まれます。これらの属性は、テーブル独自のキーとは異なるキーで整理されます。この動作は、DynamoDB グローバル セカンダリ インデックスと似ています。 |
運用
データプレーン オペレーションを使用すると、テーブル内のデータに対して作成、読み取り、更新、削除(CRUD)のアクションを実行できます。次の表は、DynamoDB と Bigtable 用の類似のデータプレーン オペレーションを比較したものです。
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsBigtable は、書き込みオペレーションを upsert として扱います。 |
UpdateItem
|
Bigtable は、書き込みオペレーションを upsert として扱います。 |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows `(範囲、プレフィックス、リバース スキャン)Bigtable では、行キー接頭辞、正規表現パターン、行キーの範囲を前方または逆方向に効率的にスキャンできます。 |
データ型
Bigtable と DynamoDB はどちらもスキーマレスです。列の存在やデータ型に関するテーブル全体の適用なしで、書き込み時に列を定義できます。同様に、特定の列または属性のデータ型は、行やアイテムごとに異なる場合があります。ただし、DynamoDB API と Bigtable API では、データ型の処理方法が異なります。
各 DynamoDB 書き込みリクエストには、各属性の型定義が含まれています。これは、読み取りリクエストのレスポンスとともに返されます。
Bigtable はすべてをバイトとして扱い、クライアント コードが型とエンコードを認識して、クライアントがレスポンスを正しく解析することを想定しています。ただし、インクリメント オペレーションは例外で、値を 64 ビット ビッグ エンディアン符号付き整数として解釈します。
次の表は、DynamoDB と Bigtable のデータ型の違いを比較したものです。
| DynamoDB | Bigtable |
|---|---|
| スカラー型: サーバー レスポンスでデータ型記述子トークンとして返されます。 | バイト: バイトは、クライアント アプリケーションで意図した型にキャストされます。 Increment は、値を 64 ビット ビッグ エンディアン符号付き整数として解釈します。 |
| セット: 一意の要素の並べ替えられていないコレクション。 | 列ファミリー: 列修飾子をセット メンバー名として使用し、それぞれに 0 バイトのセル値を指定できます。セット メンバーは、列ファミリー内で辞書順に並べ替えられます。 |
| マップ: 一意のキーを持つ、並べ替えられていない Key-Value ペアのコレクション。 | 列ファミリー 列修飾子をマップキーとして使用し、セル値を値として使用します。マップキーは辞書順に並べ替えられます。 |
| リスト: 並べ替えられたアイテムのコレクション。 | 列修飾子 insert timestamp を使用して、list_append(insert timestamp for prepend の逆) と同等の動作を実現します。 |
スキーマの設計
スキーマ設計における重要な考慮事項は、データの保存方法です。Bigtable と DynamoDB の主な違いは、次の取り扱い方法です。
- 単一値の更新
- データの並べ替え
- データ バージョニング
- 大きな値の保存
単一値の更新
DynamoDB の UpdateItem オペレーションは、更新がアイテムの属性のサブセットを含む場合でも、アイテムサイズの「前」と「後」の大きい方の書き込み容量を消費します。つまり、DynamoDB では、論理的には他の列の場合と同様に同じ行に配置される場合でも、頻繁に更新される列が別々の行に配置されることがあります。
Bigtable では、セルが特定の行の唯一の列か数千の列の中の一つの列かにかかわらず、セルを効率的に更新できます。詳しくは、シンプルな書き込みをご覧ください。
データの並べ替え
DynamoDB では、パーティション キーをハッシュして、ランダムに分散しますが、その一方で、Bigtable では、行キーの辞書順に行を保存して、ハッシングをユーザーに任せます。
ランダムキーの配布が、すべてのアクセス パターンに最適なわけではありません。これにより、ホットロー範囲のリスクは軽減されますが、パーティション境界を越えるスキャンを伴うアクセス パターンはコストが高く、非効率になります。このような無制限のスキャンは、特に時間ディメンションを含むユースケースで一般的です。
このタイプのアクセス パターン(パーティションの境界をまたぐスキャン)を処理するには、DynamoDB のセカンダリ インデックスが必要ですが、Bigtable では必要ありません。Bigtable では、多くのスキャン パターンを効率的に処理するように辞書式順序の行キーを設計できますが、Bigtable は、代替クエリ パターンに対して効率的で最終的に整合性のあるルックアップを提供するために、継続的マテリアライズド ビューとして実装する非同期セカンダリ インデックスもサポートしています。同様に、DynamoDB では、クエリとスキャンのオペレーションが 1 MB のデータスキャンに制限され、この上限を超えるとページ分けが必要になります。Bigtable にはこのような制限はありません。
パーティション キーがランダムに分散されているにもかかわらず、選択したパーティション キーがスループットに悪影響を及ぼすトラフィックを均一に分散していない場合、DynamoDB にホット パーティションを持つ場合があります。この問題に対処するために、DynamoDB では、書き込みを複数の論理パーティション キー値にランダムに分割する書き込みシャーディングを提案しています。
この設計パターンを適用するには、固定セットから乱数(たとえば 1 ~ 10)を作成してから、この数値を論理パーティション キーとして使用する必要があります。パーティション キーをランダム化しているため、テーブルへの書き込みはすべてのパーティション キー値に均等に分散されます。
Bigtable ではこの手順をキー ソルティングと呼んでいます。ホット タブレットを避けるには効果的な方法です。
データ バージョニング
各 Bigtable セルにはタイムスタンプがあり、最新のタイムスタンプは常に任意の列のデフォルト値です。タイムスタンプの一般的なユースケースは、バージョニングであり、新しいセルを列に書き込みます。この列は、タイムスタンプによって、その行や列のデータの以前のバージョンと区別されます。
DynamoDB にはそのようなコンセプトがないため、バージョニングをサポートするには複雑なスキーマ設計が必要です。この方法では、各アイテムの 2 つのコピーを作成する必要があります。1 つは、ソートキーの先頭にバージョン番号の接頭辞 0(v0_ など)が付いたコピー、もう 1 つは、バージョン番号の接頭辞 1(v1_ など)が付いたコピーです。アイテムが更新されるたびに、更新されたバージョンの並べ替えキーで次に高いバージョン プレフィックスを使用し、バージョン プレフィックスが 0 のアイテムに更新されたコンテンツをコピーします。これにより、任意のアイテムの最新バージョンをゼロ接頭辞を使用して特定できるようにします。この戦略では、アプリケーション側のロジックを維持する必要があるだけでなく、各書き込みで前の値の読み取りと 2 回の書き込みが必要になるため、データの書き込みが非常に高価で遅くなります。
複数行トランザクションと大きい行の容量
Bigtable は、複数行トランザクションをサポートしていません。ただし、DynamoDB に存在するアイテムよりもはるかに大きい行を保存できるため、多くの場合、共有行キーの下に関連するアイテムをグループ化するスキーマを設計することで、目的のトランザクション性を実現できます。このアプローチを示す例については、単一テーブル設計パターンをご覧ください。
大きな値の保存
Bigtable の行に似た DynamoDB アイテムは 400 KB に制限されているため、大きな値を格納するには、アイテムをアイテム間で分割するか、S3 のような他のメディアに保存する必要があります。どちらのアプローチでも、アプリケーションの複雑さが増します。一方、Bigtable セルは最大 100 MB を格納でき、Bigtable 行は最大 256 MB をサポートできます。
スキーマ変換の例
このセクションの例では、キー スキーマの設計の違いを考慮して、DynamoDB から Bigtable にスキーマを変換します。
基本的なスキーマを移行する
商品カタログは、基本的なキーと値のパターンを示す良い例です。このようなスキーマは、DynamoDB では次のようになります。
| 主キー | 属性 | |||
|---|---|---|---|---|
| パーティション キー | ソートキー | 説明 | 料金 | サムネイル |
| hats | fedoras#brandA | プレミアム ウールから作られています。 | 30 | https://storage… |
| hats | fedoras#brandB | 耐久性のある防水キャンバスで制作します。 | 28 | https://storage… |
| hats | newsboy#brandB | ヴィンテージの魅力を日常の印象に変えましょう。 | 25 | https://storage… |
| shoes | sneakers#brandA | スタイリングと快適さで | 40 | https://storage… |
| shoes | sneakers#brandB | クラシックな機能に現代的な素材を使用 | 50 | https://storage… |
このテーブルでは、DynamoDB から Bigtable へのマッピングは簡単にできます。DynamoDB の複合主キーを複合 Bigtable 行キーに変換します。同じ列セットを含む 1 つの列ファミリー(SKU)を作成します。
| SKU | |||
|---|---|---|---|
| 行キー | 説明 | 料金 | サムネイル |
| hats#fedoras#brandA | プレミアム ウールから作られています。 | 30 | https://storage… |
| hats#fedoras#brandB | 耐久性のある防水キャンバスで制作します。 | 28 | https://storage… |
| hats#newsboy#brandB | ヴィンテージの魅力を日常の印象に変えましょう。 | 25 | https://storage… |
| shoes#sneakers#brandA | スタイリングと快適さで | 40 | https://storage… |
| shoes#sneakers#brandB | クラシックな機能に現代的な素材を使用 | 50 | https://storage… |
単一テーブル設計パターン
単一テーブル設計パターンは、リレーショナル データベースで複数のテーブルになりそうなものを DynamoDB で 単一のテーブルにまとめます。前の例のアプローチを採用して、このスキーマを Bigtable にそのまま複製できます。ただし、プロセスでスキーマの問題に対処することをおすすめします。
このスキーマでは、パーティション キーに動画の一意の ID が含まれているため、その動画に関連するすべての属性を同じ場所に配置してすばやくアクセスできます。DynamoDB のアイテムサイズの制限により、1 行にフリー コメントを無制限に入力することはできません。そのため、パターン VideoComment#reverse-timestamp のソートキーを使用して、各コメントをパーティション内の個別の行にし、逆時系列順に並べ替えます。
この動画に 500 件のコメントがあり、所有者が動画を削除したいとします。この場合、コメントと動画の属性もすべて削除する必要があります。DynamoDB でこれを行うには、このパーティション内のすべてのキーをスキャンしてから、複数の削除リクエストを発行し、それぞれで反復処理する必要があります。DynamoDB は複数行のトランザクションをサポートしていますが、この削除リクエストは単一のトランザクションで行うには大きすぎます。
| 主キー | 属性 | |||
|---|---|---|---|---|
| パーティション キー | ソートキー | アップロード日 | 形式 | |
| 0123 | 動画 | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | コンテンツ | |||
| これすごく好き特別な効果が素晴らしい。 | ||||
| VideoComment#86751345 | コンテンツ | |||
| 1 分 5 秒のところで音声の不具合があるようです。 | ||||
| VideoStatsLikes | 数 | |||
| 3 | ||||
| VideoStatsViews | 数 | |||
| 156 | ||||
| 0124 | 動画 | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | コンテンツ | |||
| この情報をすべての友人と共有しました。 | ||||
| VideoComment#87616471 | コンテンツ | |||
| このスタイルは映画監督を思い出させるものですが、それが誰かはっきりしません。 | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
移行時にこのスキーマを修正することで、コードを簡素化し、データ リクエストをより迅速かつ低コストで行うことができます。Bigtable の行は DynamoDB のアイテムよりも容量がはるかに大きく、大量のコメントを処理できます。動画に数百万件のコメントが寄せられる場合は、ガベージ コレクション ポリシーを設定して、最新のコメント数を決めてそれだけを保持するようにします。
カウンタは、行全体を更新するオーバーヘッドなしで更新できるため、カウンタを分割する必要もありません。Bigtable のタイムスタンプを使用すると、コメントが新しい順で自動的に並べ替えられるため、UploadDate 列を使用する必要も、新しい順のタイムスタンプを計算して並べ替えキーにする必要もありません。これによりスキーマが大幅に簡素化され、動画が削除された場合は、単一のリクエストで、すべてのコメントを含む動画の行をトランザクションで削除できます。
最後に、Bigtable の列は辞書順に整理されているため、動画の読み込み時に単一の読み込みリクエストで高速の範囲スキャン(動画プロパティから最新の N 個のコメントまで)を行えるように列の名前を変更できます。その後、視聴者がスクロールすると、残りのコメントをページをめくるように見ることができます。
| 属性 | ||||
|---|---|---|---|---|
| 行キー | 形式 | 高評価 | ビュー | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | これすごく好き特別な効果が素晴らしい。@
2023-09-10T19:01:15 There seems to be an audio glitch at 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | このスタイルは映画監督を思い出させるものですが、それが誰かはっきりしません。@2023-10-12T07:08:51 | |
隣接リスト設計パターン
この設計の少し異なるバージョンについて考えてみましょう。これは、DynamoDB では隣接リスト設計パターンとよく呼ばれます。
| 主キー | 属性 | |||
|---|---|---|---|---|
| パーティション キー | ソートキー | DateCreated | 詳細 | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
このテーブルでは、並べ替えキーは時間ではなく支払い ID に基づいているため、別のワイドカラム パターンを使用して、Bigtable でこれらの ID を別々の列にすることができるため上記と同様のメリットが得られます。
| 請求書 | お支払い | |||
|---|---|---|---|---|
| 行キー | 詳細 | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| 行キー | 詳細 | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
前の例からわかるように、適切なスキーマ設計により、Bigtable のワイドカラム型モデルは非常に強力であり、高コストな複数行トランザクション、セカンダリ インデキシング、または他のデータベースでの on-delete cascade 処理が必要な多くのユースケースに使用できます。
次のステップ
- Bigtable のスキーマ設計について確認する。
- Bigtable エミュレータについて確認する。
- Google Cloudに関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。