Questa pagina fornisce una panoramica della replica tra regioni di AlloyDB per PostgreSQL.
La replica tra regioni di AlloyDB consente di creare cluster e istanze secondari da un cluster principale per rendere le risorse disponibili in regioni diverse, in caso di interruzione nella regione principale. Questi cluster e istanze secondari funzionano come copie delle risorse del cluster e dell'istanza principali.
I concetti chiave di questa pagina includono:
Cluster principale. Un cluster di lettura e scrittura in un'unica regione.
Cluster secondario. Un cluster di sola lettura in una regione diversa da quella del cluster principale, che esegue la replica dal cluster principale in modo asincrono. In caso di errore di un cluster primario AlloyDB, puoi promuovere un cluster secondario a cluster primario.
Puoi creare fino a cinque cluster secondari per un cluster primario. Tutti i cluster secondari eseguono la replica da un singolo cluster primario. Se promuovi un cluster secondario, questo diventa un cluster primario indipendente.
Istanza secondaria. Un leader di sola lettura di un cluster secondario. È responsabile della ricezione di un flusso di replica da un cluster primario. Il flusso di replica aggiorna il volume di archiviazione nella regione secondaria in base al volume di archiviazione nella regione primaria. Se un cluster secondario viene promosso a cluster primario, l'istanza secondaria diventa l'istanza primaria.
Un'istanza secondaria può essere di base (zonale) o ad alta disponibilità (regionale).
Il seguente diagramma illustra come funziona la replica tra regioni:
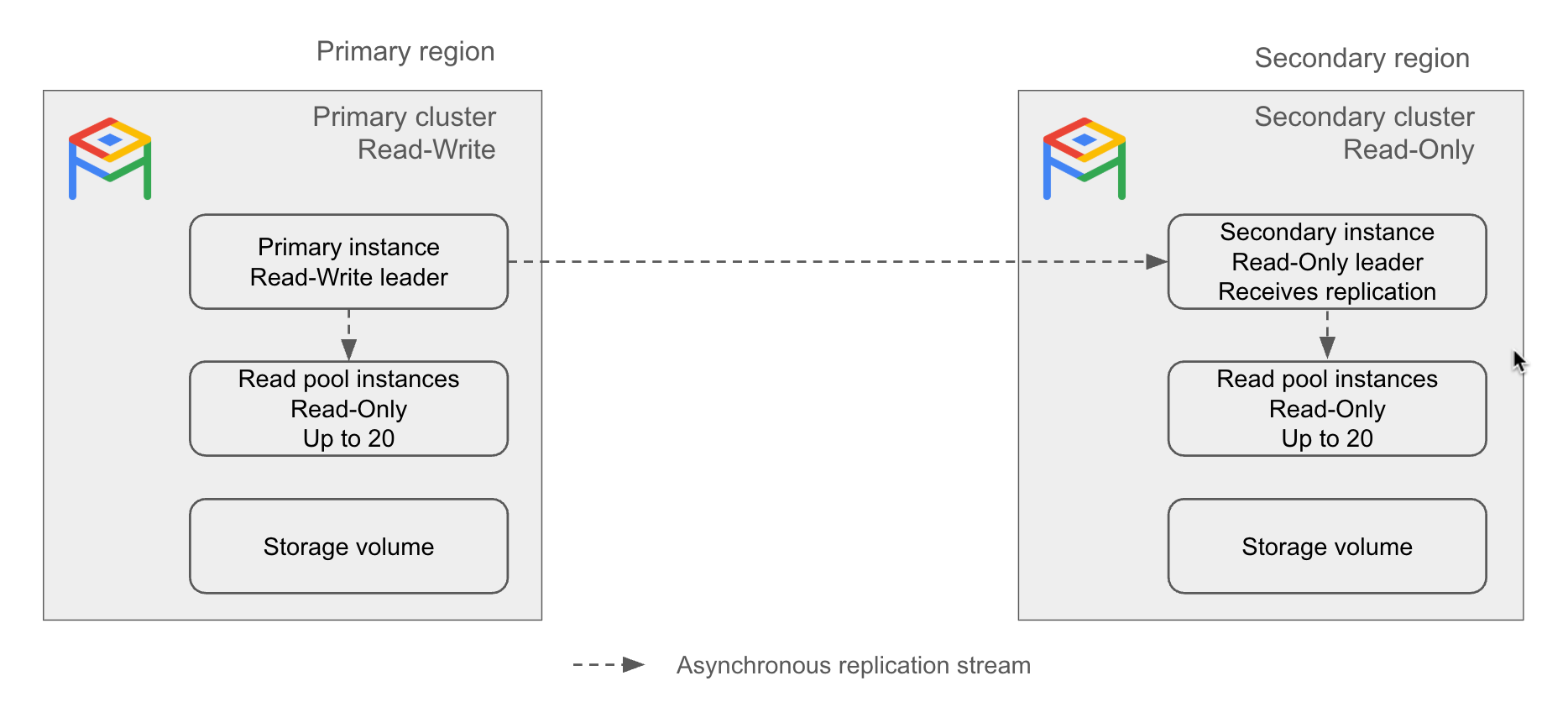
Figura 1. Esempio di architettura di replica tra regioni di AlloyDB.
Vantaggi
I vantaggi della replica tra regioni su AlloyDB includono quanto segue:
Ripristino di emergenza. Se la regione del cluster principale non è più disponibile, puoi promuovere le risorse AlloyDB in un'altra regione per gestire le richieste.
Tempi di inattività ridotti. Il supporto dell'alta affidabilità (HA) sui cluster secondari riduce i tempi di inattività durante gli eventi di manutenzione o le interruzioni non pianificate.
Dati distribuiti geograficamente. La distribuzione geografica dei dati li avvicina e riduce la latenza di lettura.
Scalabilità di lettura aumentata:ogni replica tra regioni (o cluster secondario) può supportare fino a 20 nodi di lettura, consentendoti di scalare ulteriormente le letture.
Passaggio con perdita di dati pari a zero. Per le configurazioni di replica tra regioni, AlloyDB supporta il cambio tra istanza primaria e secondaria senza perdita di dati.
Utilizzare la replica tra regioni
L'utilizzo della replica tra regioni di AlloyDB prevede le seguenti attività:
Crea un cluster secondario. Un cluster secondario è una copia aggiornata continuamente del cluster primario AlloyDB.
Visualizza un cluster secondario. Dopo aver creato un cluster secondario, puoi visualizzarne i dettagli nella pagina Cluster della console Google Cloud .
Aggiungi istanze del pool di lettura. Puoi aggiungere istanze del pool di lettura a un cluster secondario. Se vuoi scalare orizzontalmente la capacità di lettura, puoi aggiungere fino a 20 nodi di lettura al cluster secondario.
Promuovi un cluster secondario. Puoi leggere i dati da un cluster secondario, ma non puoi scriverci finché non lo promuovi a cluster primario autonomo e con tutte le funzionalità. Quando promuovi un cluster secondario, anche l'istanza secondaria del cluster viene promossa come istanza primaria con funzionalità di lettura e scrittura.
Il caso d'uso principale per la promozione di un cluster secondario è il ripristino di emergenza. Se si verifica un'interruzione a livello regionale nella regione del cluster primario, puoi promuovere il cluster secondario a cluster primario autonomo e riprendere a pubblicare l'applicazione.
Switchover senza perdita di dati. Il cambio di ruolo ti consente di invertire i ruoli del cluster primario e secondario senza perdita di dati. Puoi eseguire un failover per testare la configurazione di ripristino di emergenza o eseguire la migrazione del tuo workload. Quando completi il failover, la direzione di replica viene invertita.
Se hai più cluster secondari, il cluster secondario che riceve il comando di switchover diventa un cluster primario; il cluster primario precedente diventa un cluster secondario, che esegue la replica dal nuovo cluster primario. Tutti gli altri cluster secondari passano alla replica dal nuovo cluster primario.
Esistono due scenari comuni per il passaggio al cluster secondario:
- Simulazioni di ripristino di emergenza. Puoi eseguire test delle procedure di ripristino di emergenza passando la tua applicazione a un'altra regione senza perdita di dati per simulare un'interruzione a livello regionale.
- Migrazione regionale. Esegui una migrazione pianificata delle risorse AlloyDB dalla regione principale a un'altra regione. Il failover garantisce che il cluster secondario diventi un cluster primario con un Recovery Point Objective (RPO) pari a 0, assicurando che la migrazione non comporti la perdita di dati.
Configura backup automatici e continui. Per impostazione predefinita, AlloyDB copia automaticamente le configurazioni di backup automatico e continuo dal cluster primario a un cluster secondario appena creato. Se vuoi utilizzare configurazioni di backup diverse per il cluster secondario, puoi modificare la configurazione di backup quando crei un cluster secondario.
Se il cluster primario utilizza la crittografia con chiave di crittografia gestita dal cliente (CMEK) per i backup, esegui una delle seguenti operazioni quando crei un cluster secondario:
- Fornisci le impostazioni di crittografia CMEK per i backup del cluster secondario.
- Disattiva i backup per il cluster secondario.
Per ulteriori informazioni sulla crittografia dei backup con CMEK, consulta Utilizzare CMEK
Puoi modificare le impostazioni di backup automatico e continuo per il cluster secondario dopo la sua creazione.