Halaman ini memberikan ringkasan replikasi lintas region AlloyDB untuk PostgreSQL.
Replikasi lintas region AlloyDB memungkinkan Anda membuat cluster dan instance sekunder dari cluster utama untuk membuat resource tersedia di berbagai region, jika terjadi pemadaman di region utama. Cluster dan instance sekunder ini berfungsi sebagai salinan resource cluster dan instance utama Anda.
Konsep utama di halaman ini meliputi:
Cluster utama. Cluster baca-tulis di satu region.
Cluster sekunder. Cluster hanya baca di region yang berbeda dengan cluster utama, yang mereplikasi dari cluster utama secara asinkron. Jika terjadi kegagalan cluster utama AlloyDB, Anda dapat mempromosikan cluster sekunder menjadi cluster utama.
Anda dapat membuat hingga lima cluster sekunder untuk cluster primer. Semua cluster sekunder mereplikasi dari satu cluster utama. Jika Anda mempromosikan cluster sekunder, cluster sekunder tersebut akan menjadi cluster primer yang independen.
Instance sekunder. Pemimpin hanya baca dari cluster sekunder. Cluster ini bertanggung jawab untuk menerima aliran replikasi dari cluster utama. Aliran replikasi memperbarui volume penyimpanan di region sekunder berdasarkan volume penyimpanan di region utama. Jika cluster sekunder dipromosikan menjadi cluster utama, instance sekunder akan menjadi instance utama.
Instance sekunder dapat berupa basic (zonal) atau ketersediaan tinggi (regional).
Diagram berikut menggambarkan cara kerja replikasi lintas region:
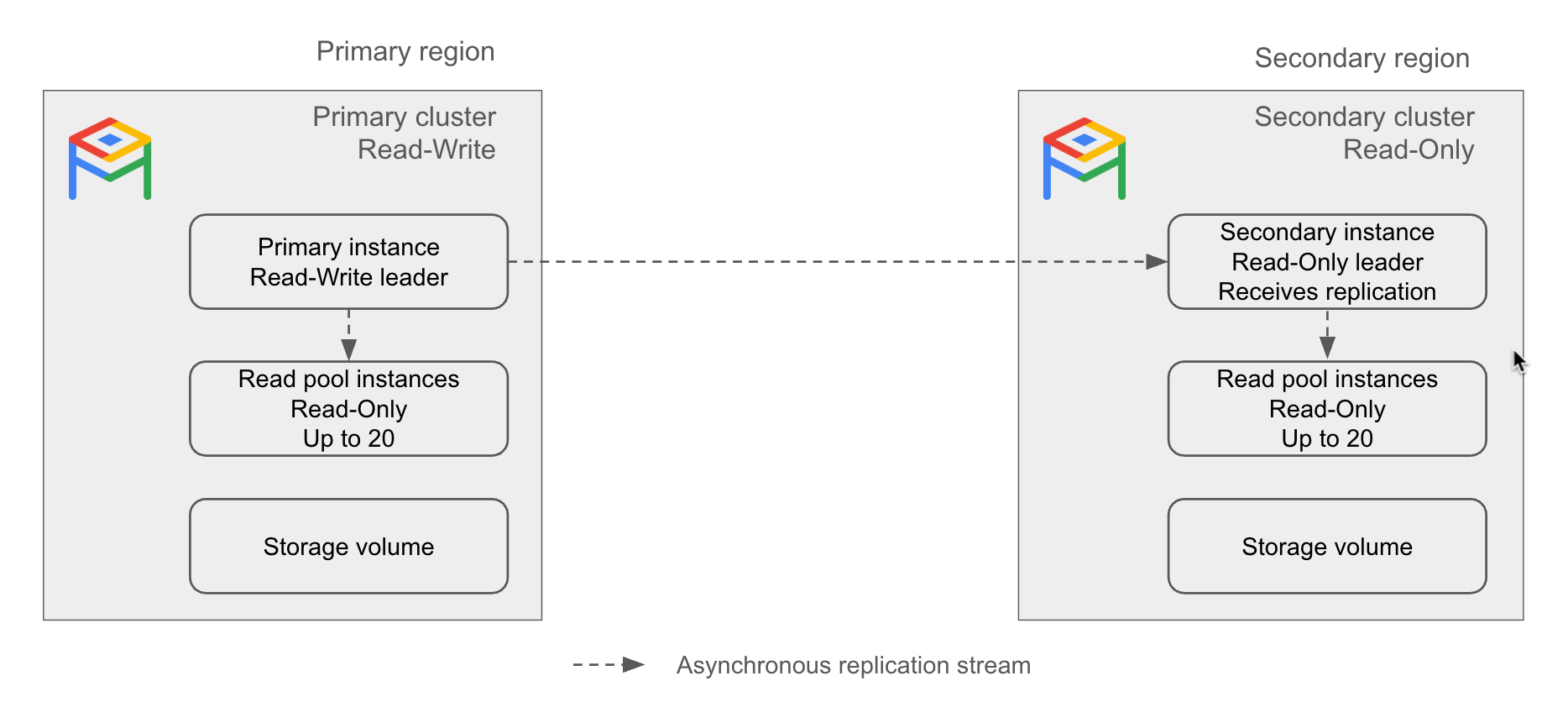
Gambar 1. Contoh arsitektur replikasi lintas region AlloyDB.
Manfaat
Manfaat replikasi lintas region di AlloyDB meliputi hal-hal berikut:
Pemulihan dari bencana. Jika region cluster utama menjadi tidak tersedia, Anda dapat mempromosikan resource AlloyDB di region lain untuk melayani permintaan.
Mengurangi periode nonaktif. Dukungan ketersediaan tinggi (HA) di cluster sekunder mengurangi periode nonaktif selama peristiwa pemeliharaan atau pemadaman layanan yang tidak direncanakan.
Data yang didistribusikan secara geografis. Mendistribusikan data secara geografis akan mendekatkan data kepada Anda dan mengurangi latensi baca.
Peningkatan penskalaan baca: Setiap replika lintas region (atau cluster sekunder) dapat mendukung hingga 20 node baca, sehingga Anda dapat menskalakan baca lebih lanjut.
Pengalihan dengan nol kehilangan data. Untuk penyiapan replikasi lintas region, AlloyDB mendukung pengalihan antara instance utama dan sekunder tanpa kehilangan data.
Bekerja dengan replikasi lintas region
Bekerja dengan replikasi lintas region AlloyDB melibatkan tugas-tugas berikut:
Buat cluster sekunder. Cluster sekunder adalah salinan cluster utama AlloyDB yang terus diperbarui.
Melihat cluster sekunder. Setelah membuat cluster sekunder, Anda dapat melihat detailnya di halaman Cluster di konsol Google Cloud .
Tambahkan instance kumpulan baca. Anda dapat menambahkan instance pool baca ke cluster sekunder. Jika ingin menskalakan kapasitas baca secara horizontal, Anda dapat menambahkan hingga 20 node baca ke cluster sekunder.
Mempromosikan cluster sekunder. Anda dapat membaca data dari cluster sekunder, tetapi Anda tidak dapat menulis ke cluster tersebut hingga Anda mempromosikannya ke cluster utama mandiri yang memiliki fitur lengkap. Saat Anda mempromosikan cluster sekunder, instance sekunder cluster juga dipromosikan sebagai instance utama dengan kemampuan baca dan tulis.
Kasus penggunaan utama untuk mempromosikan cluster sekunder adalah pemulihan dari bencana. Jika terjadi pemadaman layanan regional di region cluster utama, Anda dapat mempromosikan cluster sekunder ke cluster utama mandiri, dan melanjutkan penyajian aplikasi.
Pengalihan dengan nol kehilangan data. Pengalihan memungkinkan Anda membalikkan peran cluster primer dan sekunder tanpa kehilangan data. Anda dapat melakukan pengalihan untuk menguji penyiapan pemulihan dari bencana atau melakukan migrasi workload Anda. Saat Anda menyelesaikan pengalihan, arah replikasi akan dibalik.
Jika Anda memiliki beberapa cluster sekunder, cluster sekunder yang menerima perintah pengalihan akan menjadi cluster primer; cluster primer sebelumnya akan menjadi cluster sekunder, yang mereplikasi dari cluster primer baru. Semua cluster sekunder lainnya beralih mereplikasi dari cluster utama baru.
Ada dua skenario umum untuk melakukan pengalihan cluster sekunder:
- Simulasi pemulihan dari bencana. Anda dapat menjalankan pengujian proses pemulihan bencana dengan mengalihkan aplikasi ke region lain tanpa kehilangan data untuk menyimulasikan pemadaman layanan regional.
- Migrasi regional. Lakukan migrasi terencana resource AlloyDB dari region utamanya ke region lain. Pengalihan memastikan bahwa cluster sekunder menjadi cluster primer dengan Toleransi Durasi Kehilangan Data (RPO) 0, sehingga memastikan bahwa migrasi tidak kehilangan data apa pun.
Konfigurasi pencadangan otomatis dan berkelanjutan. Secara default, AlloyDB otomatis menyalin konfigurasi pencadangan otomatis dan berkelanjutan dari cluster utama ke cluster sekunder yang baru dibuat. Jika ingin menggunakan konfigurasi pencadangan yang berbeda untuk cluster sekunder, Anda dapat mengubah konfigurasi pencadangan saat membuat cluster sekunder.
Jika cluster utama Anda menggunakan enkripsi kunci enkripsi yang dikelola pelanggan (CMEK) untuk cadangan, lakukan salah satu hal berikut saat Anda membuat cluster sekunder:
- Berikan setelan enkripsi CMEK untuk cadangan cluster sekunder.
- Nonaktifkan pencadangan untuk cluster sekunder.
Untuk mengetahui informasi selengkapnya tentang cara mengenkripsi cadangan Anda dengan CMEK, lihat Menggunakan CMEK.
Anda dapat mengubah setelan pencadangan otomatis dan berkelanjutan untuk cluster sekunder setelah dibuat.