本文档介绍了可在图表上显示为注解的事件类型。事件是指影响系统运行的活动,例如重启或崩溃。排查问题时,显示事件可帮助您关联来自不同来源的数据。
对于每个事件,我们都会提供参考文档或问题排查文档的链接,以及有关如何查询相应事件的信息。例如,当通过分析日志来识别事件时,系统会提供适合与 Logs Explorer 或基于日志的提醒政策搭配使用的查询。
如需向图表添加注解,请配置显示相应图表的信息中心或标签页。例如,您可以配置 Google Cloud 控制台的信息中心页面中列出的大多数信息中心以显示事件。同样,您可以配置一些服务特有的可观测性标签页(例如 Compute Engine 和 Google Kubernetes Engine 的标签页)来显示事件。如需了解配置信息,请参阅在信息中心内显示事件。
以下屏幕截图展示了一个图表,其中显示了通过分析日志条目识别的多个事件和一个 Service Health 事件:
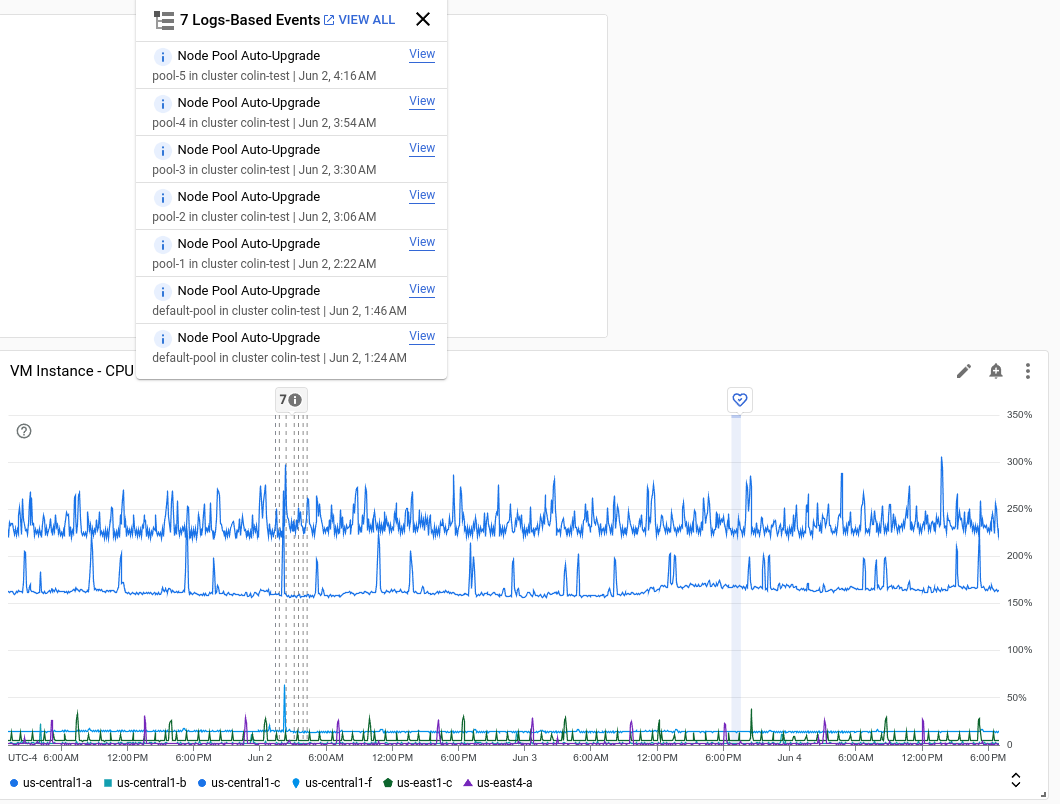
每条注解都可以列出多个事件。在上一个屏幕截图中,列出了一个 GKE 部署的事件。
提醒事件类型
本部分介绍了可在信息中心内显示的提醒事件类型。
已创建提醒
“已创建提醒”事件可帮助您将绘制成图表的数据与突发事件的创建时间相关联。如果满足以下条件,系统会显示已创建提醒事件:
- 相应突发事件是在信息中心指定的时间范围内创建的。
- 相应突发事件未关闭。
对于在信息中心指定的时间范围之外创建的突发事件,系统不会创建任何注解。同样,如果相应突发事件在信息中心指定的时间范围内先创建后关闭,则不会显示已创建提醒事件。
已创建提醒事件的提示包含以下内容:
- 提醒政策的名称。
- 摘要信息(如果提供了此信息)。例如,此信息可能会包括阈值和测量值。
- 突发事件的持续时间,以及突发事件的创建日期和时间。
- 指标和资源标签。提示可能不会显示所有标签。
- 查看按钮,用于打开突发事件的详细信息页面。
Google Kubernetes Engine 事件类型
本部分介绍了可在信息中心内显示的 Google Kubernetes Engine 事件类型。
已修补或更新 GKE 工作负载
此事件类型有助于您排查 GKE 工作负载部署或有状态集更改方面的问题,因为这些事件可能与性能下降或其他性能问题相关。当创建、更新或删除工作负载时,系统会显示此事件类型。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
GKE Pod 崩溃
此事件类型有助于您识别和排查 GKE Pod 崩溃问题。Pod 崩溃可能是由内存耗尽或应用错误引起的。当发生以下任一情况时,系统会显示此事件类型:
- Pod 状态为
CrashLoopBackoff - Pod 终止并带有非零退出代码。
- Pod 在内存不足的情况下终止。
- Pod 被逐出。
- 就绪性/活跃性探测失败。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
如需了解问题排查信息,请参阅问题排查:CrashLoopBackOff。
无法调度 GKE Pod
此事件类型有助于您识别和排查无法在节点上调度 Pod 这一问题。如果因以下任何原因导致 Pod 调度失败,系统会显示此事件类型:
- 节点 CPU 不足。
- 节点内存不足。
- 没有适用于污点或容忍的节点。
- 节点达到 Pod 数量上限。
- 节点池达到最大大小。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
如需了解问题排查信息,请参阅问题排查:Pod 无法调度。
无法创建 GKE 容器
此事件类型有助于您识别和排查 GKE 容器创建失败问题。容器创建可能会由于卷装载失败或映像拉取失败等原因而失败。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
如需了解有关映像拉取的问题排查信息,请参阅排查映像拉取问题。
Pod 自动扩缩器扩容和缩容
此事件可让您了解 Pod 横向自动扩缩器重新扩缩的情况,即增加或减少用于工作负载的运行 Pod 数量。如需了解详情,请参阅 Pod 横向自动扩缩。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
集群自动扩缩器扩容和缩容
此事件可让您了解集群自动扩缩器对集群节点池中的节点数量进行扩容或缩容的情况。如需了解详情,请参阅集群自动扩缩简介和查看集群自动扩缩器事件。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
集群创建和删除
此事件可跟踪 GKE 集群创建和删除操作。如需了解详情,请参阅创建 Autopilot 集群、创建可用区级集群和删除集群。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
集群更新
此事件可跟踪 GKE 集群的更新。更新包括控制平面版本自动升级,以及手动升级和集群配置更改。如需了解详情,请参阅手动升级集群或节点池和 Standard 集群升级。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
节点池更新
此事件可跟踪 GKE 节点池的更新。更新包括节点池版本自动升级,以及手动升级、配置更改和调整大小。如需了解详情,请参阅手动升级集群或节点池和 Standard 集群升级。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Cloud Run 事件类型
本部分介绍了可在信息中心内显示的 Cloud Run 事件类型。
Cloud Run 部署
此事件类型有助于您识别和排查 Cloud Run 部署失败问题。部署可能会因服务账号已删除、权限不正确、容器导入失败或容器未能启动等原因而失败。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
如需了解问题排查信息,请参阅问题排查:Cloud Run 问题。
Cloud SQL 事件类型
本部分介绍了可在信息中心内显示的 Cloud SQL 事件类型。
Cloud SQL 故障切换
此事件类型有助于您确定发生手动或自动故障切换的情况。当实例或可用区发生故障,并且备用实例成为新的主实例时,系统会进行故障切换。在故障切换期间,Cloud SQL 会自动切换为从备用实例传送数据。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
如需了解详情,请参阅高可用性简介。
Cloud SQL 启动或停止
此事件类型有助于您确定手动启动、停止或重启 Cloud SQL 实例的情况。当实例停止时,所有连接、打开的文件和正在执行的操作会一并停止。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
如需了解详情,请参阅高可用性简介和启动、停止和重启实例。
Cloud SQL 存储
此事件类型有助于您识别与 Cloud SQL 存储相关的事件,包括数据库存储空间已满的情况,以及数据库因达到存储空间容量而关闭的情况。存储空间容量已用尽且未启用自动存储功能的数据库可能会关闭,以防止数据损坏。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Compute Engine 事件类型
本部分介绍了可在信息中心内显示的 Compute Engine 事件类型。
虚拟机终止
此事件类型有助于您识别虚拟机 (VM) 终止情况,包括手动触发的重置和停止、客户机操作系统终止、维护终止和主机错误。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
如需了解详情,请参阅停止和启动虚拟机以及排查虚拟机关停和重启问题。
虚拟机实例启动失败
此事件会跟踪 Compute Engine 虚拟机实例启动失败问题。此事件会显示由于资源短缺、IP 空间用尽、超出配额或安全强化型虚拟机完整性错误导致的启动失败问题。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
虚拟机实例客户机操作系统错误
此事件会跟踪串行控制台日志中记录的特定 Compute Engine 虚拟机实例客户机操作系统错误。跟踪的错误包括:磁盘已满、文件系统装载失败以及会导致激活 Linux 紧急模式的启动失败。
如需显示这些事件,您必须通过在虚拟机或项目元数据中设置 serial-port-logging-enable=true,来启用将串行端口输出记录到 Cloud Logging 的功能。如需了解详情,请参阅启用和停用串行端口输出日志记录功能。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
托管式实例组更新
此事件类型有助于您确定托管式实例组 (MIG) 的更新情况。例如,添加或移除了虚拟机,或者更新了大小限制。如需了解详情,请参阅在 MIG 中自动应用虚拟机配置更新。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
如需了解详情,请参阅使用托管式实例和排查托管式实例组问题。
托管式实例组自动扩缩器
此事件跟踪 MIG 的自动扩缩器做出的扩缩决策。这些决策可能包括 MIG 推荐大小的变更或自动扩缩器本身状态的变更。如需了解详情,请参阅自动扩缩实例组。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Personalized Service Health 事件类型
本部分介绍了可在信息中心内显示的 Personalized Service Health 类型。
Google Cloud 突发事件
在进行问题排查时,您可能需要区分由您拥有的服务导致的故障和由您使用的Google Cloud 服务导致的故障。在信息中心内启用 Personalized Service Health 注解后,您可以查看 Google Cloud 服务的中断情况或 Service Health 事件。如需查看与 Service Health 集成的服务列表,请参阅支持的 Google 产品。
与其他事件类型不同, Google Cloud 突发事件不是通过分析日志条目来识别的。如果您想在发生这些事件时收到通知,请创建提醒政策。您可以使用 Service Health 信息中心页面上的选项选择预配置的提醒政策。如需了解详情,请参阅快速入门:设置提醒。
Monitoring 识别 Google Cloud 突发事件的方法是向 Service Health API 发出请求,然后过滤响应,以便仅显示与您所查看的数据相关的突发事件。请求具有以下配置:
Relevance枚举设置为RELATED、IMPACTED或PARTIALLY_RELATED。此限制可确保您的信息中心仅显示Google Cloud 项目所使用的 Google Cloud 服务的事件。DetailedState枚举未设置为FALSE_POSITIVE。
Service Health 注解在显示时带有开始时间和持续时间。系统会通过更改图表的背景颜色来显示持续时间。 Google Cloud 突发事件的提示会显示以下信息:
- Google Cloud 服务。
- 突发事件是未结还是已解决。
- 事件发生的日期和开始时间。
- 显示受影响的产品和位置数量的条状标签。如需列出受影响的产品或位置,请将指针置于相应条状标签上。
- 查看按钮,选择该按钮后会打开相应事件的详情页面。
如需了解如何向 Service Health API 发出请求,请参阅使用 Service Health 检查中断情况。
如需了解问题排查信息,请参阅排查 Service Health 中的常见问题。
拨测事件类型
本部分介绍了可在信息中心内显示的拨测事件类型。
拨测失败
此事件类型有助于您识别来自已配置区域的拨测失败。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
如需了解问题排查信息,请参阅排查合成监控工具和拨测问题。
Agent for SAP 事件类型
本部分介绍了可在信息中心内显示的 Agent for SAP 事件类型。
SAP 可用性
此事件类型有助于您识别与 Agent for SAP 可用性相关的事件。当 SAP HANA、SAP NetWeaver 或 Pacemaker 集群的可用性发生变化时,系统会触发这些事件。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
此事件类型有助于您识别与 Agent for SAP Backint 相关的事件。任何 Backint 备份或恢复操作都会写入一个事件,详细说明成功或失败情况以及传输统计信息。日志备份和恢复操作仅在失败时显示,而数据备份和恢复操作在成功和失败时均会显示。
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
SAP 操作
此事件类型有助于您识别与 Agent for SAP 操作相关的事件。当 SAP HANA 复制状态发生变化时,系统会触发这些事件。
如果您想为此类事件创建基于日志的提醒政策,请使用以下查询:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
后续步骤
如需了解如何在信息中心内显示事件,请参阅在信息中心内显示事件。