En esta página, se proporciona una descripción general de la replicación entre regiones para Memorystore for Redis Cluster.
Para obtener instrucciones sobre cómo administrar la replicación entre regiones, consulta Trabaja con la replicación entre regiones.
La replicación entre regiones te permite crear clústeres secundarios a partir de un clúster principal para que tu clúster esté disponible para lecturas en diferentes regiones. Los clústeres secundarios también proporcionan redundancia para situaciones de recuperación ante desastres en caso de interrupciones regionales.
Los conceptos clave de esta página incluyen los siguientes:
- Clúster principal. Un clúster de lectura y escritura en una sola región.
- Clústeres secundarios. Un clúster secundario es un clúster de solo lectura que replica desde el clúster principal de forma asíncrona. Para obtener información sobre cómo promover y separar servidores secundarios, consulta las secciones conmutación por error y separación de Cómo trabajar con la replicación entre regiones.
- Nodo replicador. Es un nodo en la partición del clúster principal que se replica en un nodo secundario del clúster secundario. Cualquier nodo principal o de réplica en la partición puede cumplir el rol de replicador.
- Nodos seguidores. Son los nodos del clúster secundario que se replican desde un nodo replicador del clúster principal. Solo los nodos principales del clúster secundario pueden tener el rol de seguidor.
- Recuento de fragmentos y asignación de ranuras. Los clústeres principal y secundario tienen la misma cantidad de fragmentos y asignaciones de ranuras.
Beneficios
Entre los beneficios de la replicación entre regiones en Memorystore for Redis Cluster, se incluyen los siguientes:
- Recuperación ante desastres: En caso de que la región del clúster principal deje de estar disponible, puedes conmutar a un clúster secundario en otra región o separarlo para atender solicitudes de lectura y escritura. Los clústeres secundarios siempre están listos para entregar solicitudes de lectura sin emitir un comando de conmutación o separación.
- Datos distribuidos geográficamente. Distribuir los datos geográficamente los acerca a ti y disminuye la latencia de lectura.
- Balanceo de cargas geográfico para el tráfico de lectura. En caso de conexiones lentas o sobrecargadas en una región, puedes enrutar el tráfico a otra región.
Comportamiento de las funciones
En esta sección, se explica el comportamiento importante de la replicación entre regiones que debes conocer.
- Escalar la capacidad de la instancia Cuando ajustas la capacidad de la instancia del clúster principal, los clústeres secundarios se ajustan automáticamente para que coincidan con el principal.
- Ajuste del recuento de réplicas. Puedes escalar el recuento de réplicas para los clústeres principales y secundarios de forma independiente según las necesidades de tu carga de trabajo. Las actualizaciones del recuento de réplicas son solo locales y no se propagan a otros clústeres dentro de la colección de clústeres de la replicación entre regiones.
- Conmutación durante una posible interrupción. Puedes realizar un cambio para promover un clúster secundario, incluso si el clúster principal no está disponible debido a una interrupción. En esta situación, el clúster principal no disponible finalmente se convierte en un clúster secundario cuando se resuelve la interrupción.
- Creación en línea del clúster secundario. Cuando agregas un clúster secundario a uno principal, el clúster principal permanece en línea. La instancia principal procesa las solicitudes mientras se crea la secundaria y replica los datos.
- Clústeres secundarios. Puedes tener hasta dos secundarias. Pueden estar ubicados en todas las regiones disponibles. Si lo deseas, pueden estar ubicados en regiones diferentes entre sí. Un clúster existente no se puede convertir en un clúster secundario. Solo se pueden agregar clústeres nuevos como clústeres secundarios a un clúster existente.
- Configuración sincronizada: La mayoría de los parámetros de configuración se sincronizan automáticamente entre los clústeres principal y secundario. Para obtener más información sobre estos parámetros de configuración, consulta Configuración del clúster.
- Precios. A los clientes que usen la replicación entre regiones se les cobrará por los clústeres secundarios aprovisionados para la replicación entre regiones. Para cada nodo y réplica implementados en el clúster secundario, a los clientes se les cobrará como en cualquier otro clúster principal. Además, los clientes incurren en cargos de redes por la transferencia de datos entre clústeres en diferentes regiones.
- Actualización de mantenimiento. Para garantizar la compatibilidad con la replicación entre regiones, es posible que tu clúster principal se someta a una actualización de mantenimiento durante la creación del clúster secundario si aún no ejecuta la versión de software requerida. Este proceso de actualización puede introducir cierta latencia adicional cuando crees tu clúster secundario. Para obtener más información sobre el mantenimiento, consulta Acerca del mantenimiento.
Cómo trabajar con la replicación entre regiones
Trabajar con la replicación entre regiones de Memorystore for Redis Cluster implica las siguientes tareas:
- Crea un clúster secundario. Creas un clúster secundario que se replica de forma continua desde tu clúster principal.
- Cómo ver un clúster secundario Puedes ver información sobre un clúster secundario, incluido el nombre del clúster principal y el otro clúster secundario del grupo de replicación.
Desconecta los clústeres secundarios. La desconexión de clústeres secundarios es una operación en la que desacoplas los clústeres secundarios de su clúster principal. Esto los convierte en clústeres independientes completamente funcionales que permiten operaciones de lectura y escritura. Después de una operación de desconexión, los clústeres secundarios ya no replican los datos del clúster principal con el que estaban asociados anteriormente. Tanto el clúster principal original como los clústeres recién desconectados (antes secundarios) funcionan como clústeres independientes sin relación entre sí.
Existen dos situaciones principales para separar clústeres secundarios:
- Migración regional. Realiza una migración planificada de los recursos de Memorystore for Redis Cluster desde su región principal a otra región.
- Recuperación ante desastres: Activar rápidamente los recursos de Memorystore for Redis Cluster en una región secundaria en caso de que los recursos de la región principal dejen de estar disponibles Si los clústeres secundarios no se sincronizaron por completo con el clúster principal, es posible que se pierdan algunos datos.
Cambia tus clústeres. Un cambio te permite invertir los roles de tu clúster principal y secundario. Puedes realizar un cambio para probar la configuración de recuperación ante desastres, durante una situación real de recuperación ante desastres o para migrar tu carga de trabajo. Cuando completas el cambio, se invierte la dirección de la replicación y el clúster secundario anterior puede aceptar operaciones de lectura y escritura, mientras que el clúster principal anterior cambia a solo lectura.
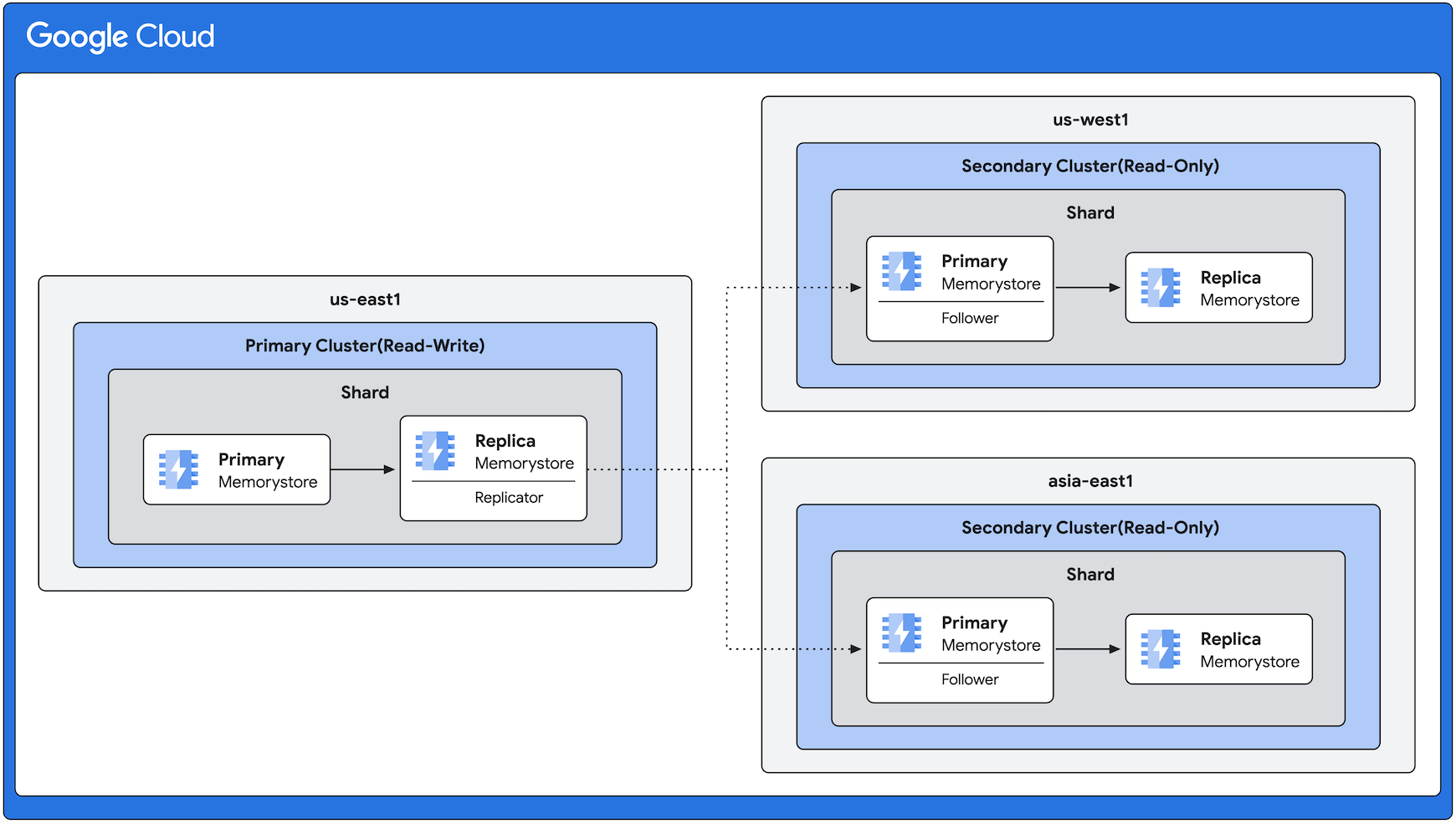
Ejemplo de arquitectura de replicación entre regiones
En el siguiente diagrama, se muestra un clúster principal en la región us-east1 con clústeres secundarios en us-west1 y asia-east1. La dirección de la replicación siempre es de us-east1 a las demás regiones. Ten en cuenta que, si bien el siguiente diagrama muestra la misma cantidad de réplicas en todas las regiones, la función de replicación entre regiones te brinda la flexibilidad de tener cantidades variables de réplicas según tus requisitos.
Configuración del clúster
En esta sección, se explica qué parámetros de configuración se requieren, copian o anulan para los clústeres principales y secundarios que usan la replicación entre regiones. También se explica qué parámetros de configuración se establecen en el servidor principal y cuáles se establecen de forma local.
Parámetros obligatorios para crear un clúster secundario
- Proyecto de Google Cloud. Este es el proyecto en el que se encuentra tu clúster principal y en el que se creará el clúster secundario.
- Región. Esta es la región en la que deseas colocar tu clúster secundario.
- Configuración de Private Service Connect. Esta es la configuración de redes de tu clúster.
- Clúster principal. Cuando creas un clúster secundario, debes indicar un clúster principal para él. Cualquier clúster que no sea secundario se puede usar como clúster principal. Si no tienes un clúster principal, primero debes crearlo.
Parámetros de configuración copiados de la instancia principal durante la creación de la instancia
Durante la creación del clúster secundario, este copia los siguientes parámetros de configuración del clúster principal:
- Recuento de fragmentos
- Modo de autenticación de IAM
- Modo de encriptación en tránsito
- Configuraciones del motor de Redis
- Versión del motor de Redis
- Tipo de nodo
- Modo de persistencia
Se permite la anulación durante la creación de instancias
Los siguientes parámetros de configuración permiten anular el valor predeterminado durante la creación de la instancia.
- Configuración de distribución de zonas
- Recuento de réplicas
- Períodos de mantenimiento
- Protección contra la eliminación
- Copias de seguridad automáticas
Actualiza la configuración del clúster
Cuando actualizas la configuración del clúster, algunos parámetros solo se pueden cambiar en el clúster principal y los cambios se sincronizan automáticamente con los clústeres secundarios con el tiempo. Otros parámetros de configuración se pueden cambiar de forma independiente en los clústeres primarios y secundarios, y estos se aplican solo de forma local, no se sincronizan con los otros clústeres.
Establecer en la tarjeta principal
Se deben cambiar los siguientes parámetros de configuración en la instancia principal, y la actualización se sincroniza con la instancia secundaria:
Establecida localmente
Configura estos parámetros de forma local:
- Protección contra la eliminación
- Recuento de réplicas
- Períodos de mantenimiento
- Endpoints del clúster
- Copias de seguridad automáticas
Prácticas recomendadas para el cambio
Cuando realices un cambio, te recomendamos que sigas las instrucciones de esta sección para que tu aplicación pueda hacer un seguimiento de las escrituras y enviarlas al clúster correspondiente.
- Evita que tu aplicación escriba en el clúster principal.
Determina el clúster secundario que se promoverá (si hay varios clústeres secundarios para elegir). Estos son algunos factores que podrían ayudarte a determinar qué canal secundario promocionar:
La proximidad de tu aplicación al clúster Esto podría afectar la latencia de escritura.
Es el clúster que está más al día en términos de datos.
Es el clúster más cercano en términos de configuración a los clústeres principales.
Espera a que se complete la operación de conmutación.
Actualiza la aplicación para que envíe las escrituras al clúster recién promovido que elegiste en el paso 2.