本頁說明如何使用 Service、Ingress 或 Gateway 資源,解決 Google Kubernetes Engine (GKE) 叢集中的負載平衡相關問題。
找不到 BackendConfig
如果 Service 註解已指定 Service 通訊埠的 BackendConfig,卻找不到實際的 BackendConfig 資源,就會發生這個錯誤。
如要評估 Kubernetes 事件,請執行下列指令:
kubectl get event
以下輸出範例表示系統找不到 BackendConfig:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
如要解決這個問題,請確認您未在錯誤的命名空間中建立 BackendConfig 資源,或是在服務註解中拼錯參照名稱。
找不到輸入安全性政策
建立 Ingress 物件之後,如果安全性政策沒有正確地與 LoadBalancer Service 建立關聯,請評估 Kubernetes 事件,確認是否有設定錯誤。如果 BackendConfig 指定不存在的安全政策,系統會定期發出警告事件。
如要評估 Kubernetes 事件,請執行下列指令:
kubectl get event
以下輸出範例表示系統找不到安全性政策:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
如要解決這個問題,請在 BackendConfig 中指定正確的安全性政策名稱。
在 GKE 中調度工作負載時,使用 NEG 解決 500 系列錯誤
症狀:
使用 GKE 佈建的 NEG 進行負載平衡時,工作負載縮減期間,服務可能會發生 502 或 503 錯誤。如果現有連線關閉前 Pod 就終止,就會發生 502 錯誤;如果流量導向已刪除的 Pod,就會發生 503 錯誤。
如果您使用採用 NEG 的 GKE 代管負載平衡產品 (包括 Gateway、Ingress 和獨立 NEG),這個問題可能會影響叢集。如果經常調整工作負載規模,叢集受影響的風險會比較高。
診斷:
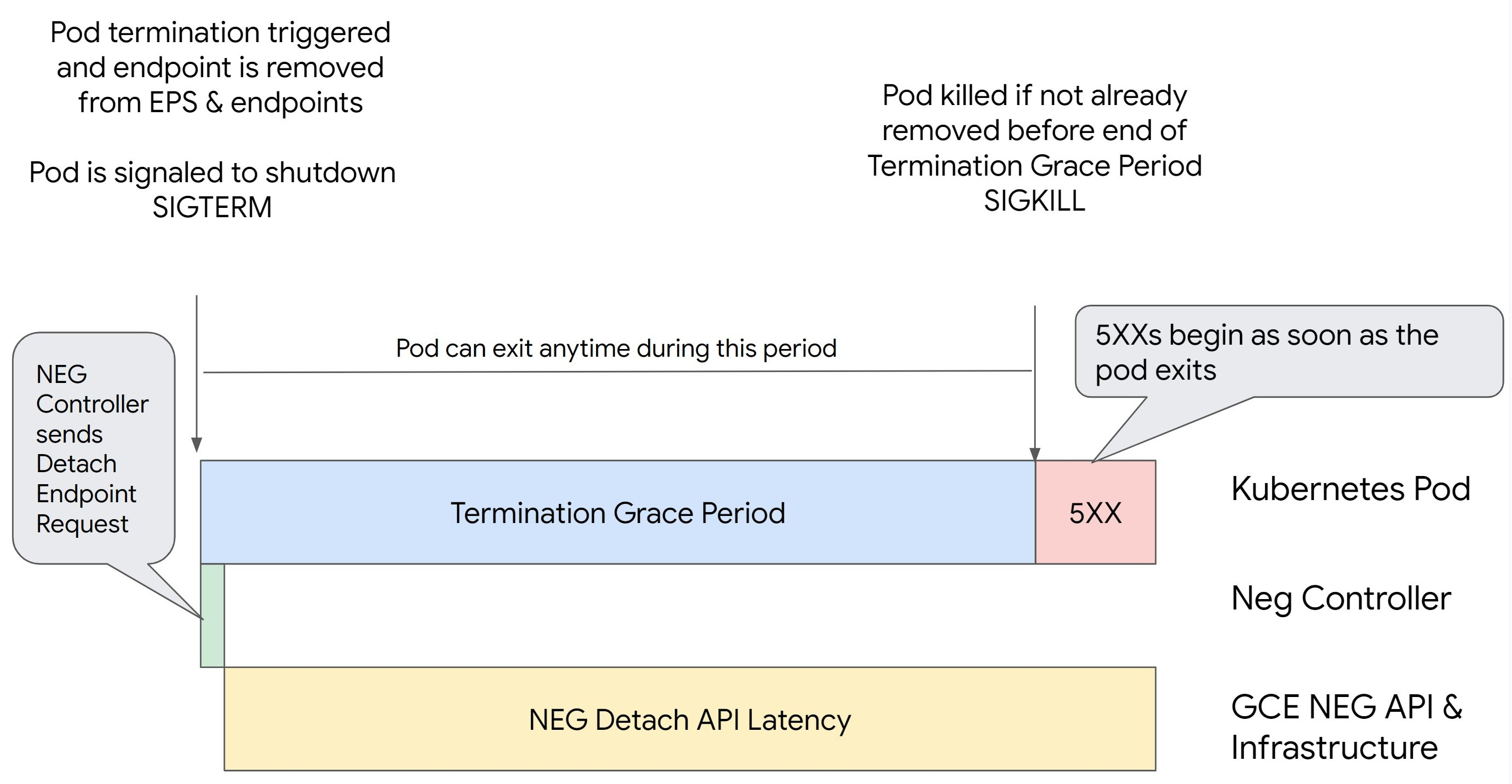
如果未先排除端點並從 NEG 中移除,就直接移除 Kubernetes 中的 Pod,會導致 500 系列錯誤。為避免 Pod 終止期間發生問題,您必須考量作業順序。下列圖片顯示 BackendService Drain Timeout 未設定,以及 BackendService Drain Timeout 設為 BackendConfig 時的場景。
情境 1:BackendService Drain Timeout 未設定。
下圖顯示 BackendService Drain Timeout 未設定的情形。
情境 2:已設定 BackendService Drain Timeout。
下圖顯示設定 BackendService Drain Timeout 的情境。

500 系列錯誤的確切發生時間取決於下列因素:
NEG API 分離延遲時間:NEG API 分離延遲時間代表在 Google Cloud中完成分離作業所花費的目前時間。這會受到 Kubernetes 以外的各種因素影響,包括負載平衡器類型和特定區域。
排空延遲:排空延遲是指負載平衡器開始將流量從系統的特定部分導出的時間。啟動排空程序後,負載平衡器會停止將新要求傳送至端點,但觸發排空程序仍有延遲 (排空延遲),如果 Pod 不再存在,可能會導致暫時性的 503 錯誤。
健康狀態檢查設定:更敏感的健康狀態檢查門檻可縮短 503 錯誤的持續時間,因為即使分離作業尚未完成,這類門檻也能向負載平衡器發出信號,要求停止將要求傳送至端點。
終止寬限期:終止寬限期會決定 Pod 結束作業的時間上限。不過,Pod 可以在終止寬限期結束前結束。如果 Pod 執行時間超過這個期限,系統會在期限結束時強制結束 Pod。這是 Pod 的設定,需要在工作負載定義中設定。
潛在解決方法:
如要避免發生 5XX 錯誤,請套用下列設定。逾時值僅供參考,您可能需要根據特定應用程式調整。下一節將引導您完成自訂程序。
下圖顯示如何使用 preStop 勾點讓 Pod 維持運作:

如要避免發生 500 系列錯誤,請執行下列步驟:
將服務的
BackendService Drain Timeout設為 1 分鐘。如果是 Ingress 使用者,請參閱在 BackendConfig 上設定逾時。
如果是閘道使用者,請參閱在 GCPBackendPolicy 上設定逾時。
如果使用獨立 NEG 時直接管理 BackendService,請參閱直接在後端服務上設定逾時。
擴充 Pod 上的
terminationGracePeriod。將 Pod 上的
terminationGracePeriodSeconds設為 3.5 分鐘。搭配建議設定使用時,這項功能可讓 Pod 在端點從 NEG 移除後,有 30 到 45 秒的緩衝時間可安全關閉。如果需要更多時間完成正常關機程序,可以延長寬限期,或按照「自訂逾時」一節的指示操作。下列 Pod 資訊清單指定連線排除逾時為 210 秒 (3.5 分鐘):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...將
preStop勾點套用至所有容器。套用
preStophook,確保 Pod 在負載平衡器排除 Pod 端點,以及從 NEG 移除端點時,仍可存活 120 秒。spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
自訂逾時
為確保 Pod 持續運作並避免發生 500 系列錯誤,Pod 必須保持運作,直到端點從 NEG 移除為止。具體來說,如要避免 502 和 503 錯誤,請考慮導入逾時和 preStop 勾點的組合。
如要在關機程序期間延長 Pod 的運作時間,請在 Pod 中新增 preStop 勾點。在系統發出 Pod 結束訊號前執行 preStop hook,因此 preStop hook 可用於讓 Pod 保持運作,直到對應的端點從 NEG 中移除為止。
如要延長 Pod 在關機程序期間保持活動狀態的時間,請在 Pod 設定中插入 preStop hook,如下所示:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
您可以設定逾時和相關設定,在工作負載縮減期間管理 Pod 的正常關機程序。您可以根據特定用途調整逾時時間。建議您先設定較長的逾時時間,再視需要縮短。您可以透過下列方式,設定逾時相關參數和 preStop 勾點,自訂逾時時間:
後端服務排空逾時
Backend Service Drain Timeout 參數預設為未設定,因此不會產生任何作用。如果您設定 Backend Service Drain Timeout 參數並啟用,負載平衡器會停止將新要求轉送至端點,並等待逾時,然後終止現有連線。
您可以透過 Ingress 使用 BackendConfig、透過 Gateway 使用 GCPBackendPolicy,或在獨立 NEG 的 BackendService 上手動設定 Backend Service Drain Timeout 參數。逾時時間應比處理要求所需的時間長 1.5 到 2 倍。這樣一來,即使在啟動排空程序前收到要求,也會在逾時前完成。將 Backend Service Drain Timeout 參數設為大於 0 的值,有助於減輕 503 錯誤,因為系統不會將新要求傳送至排定要移除的端點。如要讓這個逾時時間生效,您必須搭配使用 preStop Hook,確保 Pod 在排空期間保持啟用狀態。如果沒有這項組合,現有未完成的要求會收到 502 錯誤。
preStop 鉤住觀眾的時間
preStop hook 必須延遲 Pod 關閉,讓排除延遲和後端服務排除作業逾時都能完成,確保在 Pod 關閉前,連線能正常排除,且端點已從 NEG 移除。
為獲得最佳成效,請確保 preStop hook 執行時間大於或等於 Backend Service Drain Timeout 和耗電延遲的總和。
使用下列公式計算理想的preStop掛鉤執行時間:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
更改下列內容:
BACKEND_SERVICE_DRAIN_TIMEOUT:您為Backend Service Drain Timeout設定的時間。DRAIN_LATENCY:預估排空延遲時間。建議您以一分鐘做為估算值。
如果 500 錯誤持續發生,請估算總發生時間,並將該時間加倍後,加到預估的排空延遲時間。這可確保 Pod 有足夠時間正常排空,然後再從服務中移除。如果這個值對特定用途而言太長,可以調整。
或者,您也可以查看 Pod 的刪除時間戳記,以及 Cloud 稽核記錄中端點從 NEG 移除的時間戳記,藉此估算時間。
終止寬限期參數
您必須設定 terminationGracePeriod 參數,確保 preStop hook 有足夠時間完成,且 Pod 能順利關閉。
如未明確設定,預設 terminationGracePeriod 為 30 秒。
您可以使用下列公式計算最佳 terminationGracePeriod:
terminationGracePeriod >= preStop hook time + Pod shutdown time
如要在 Pod 的設定中定義 terminationGracePeriod,請按照下列步驟操作:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
建立內部 Ingress 資源時找不到 NEG
在 GKE 中建立內部 Ingress 時,可能會發生下列錯誤:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
發生這項錯誤的原因是,內部應用程式負載平衡器的 Ingress 需要使用網路端點群組 (NEG) 做為後端。
在共用虛擬私有雲環境或啟用網路政策的叢集中,請將 cloud.google.com/neg: '{"ingress": true}' 註解新增至服務資訊清單。
504 Gateway Timeout:上游要求逾時
從 GKE 的內部 Ingress 存取 Service 時,可能會發生下列錯誤:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
發生這項錯誤的原因是,傳送至內部應用程式負載平衡器的流量,會由 Proxy 專用子網路範圍內的 envoy Proxy 進行 Proxy 處理。
如要允許來自僅限 Proxy 子網路範圍的流量,請在服務的 targetPort 上建立防火牆規則。
錯誤 400:欄位「resource.target」的值無效
從 GKE 的內部 Ingress 存取 Service 時,可能會發生下列錯誤:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
如要解決這個問題,請建立僅限 Proxy 的子網路。
同步處理期間發生錯誤:執行負載平衡器同步處理常式時發生錯誤:負載平衡器不存在
升級 GKE 控制平面或修改 Ingress 物件時,可能會發生下列其中一個錯誤:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
或:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
如要解決這些問題,請按照下列步驟操作:
- 在 Ingress 資訊清單的
tls區段中新增hosts欄位,然後刪除 Ingress。請稍候五分鐘,等待 GKE 刪除未使用的 Ingress 資源。然後重新建立 Ingress。詳情請參閱「Ingress 物件的主機欄位」。 - 還原您對 Ingress 所做的變更。然後使用註解或 Kubernetes Secret 新增憑證。
外部 Ingress 產生 HTTP 502 錯誤
請按照下列指南,排解外部 Ingress 資源的 HTTP 502 錯誤:
- 為與 Ingress 參照的每個 GKE 服務相關聯的後端服務啟用記錄。
- 使用狀態詳細資料找出 HTTP 502 回應的原因。如果狀態詳細資料指出 HTTP 502 回應來自後端,則需要對提供服務的 Pod 進行疑難排解,而非負載平衡器。
非代管執行個體群組
如果外部 Ingress 使用非代管執行個體群組後端,您可能會遇到外部 Ingress 資源的 HTTP 502 錯誤。如果符合下列「所有」條件,就會發生這個問題:
- 叢集在所有節點集區中擁有大量節點。
- Ingress 參照的一或多個服務的服務 Pod 僅位於少數節點上。
- Ingress 參照的服務會使用
externalTrafficPolicy: Local。
如要判斷外部 Ingress 是否使用非代管執行個體群組後端,請執行下列操作:
前往 Google Cloud 控制台的「Ingress」頁面。
按一下外部 Ingress 的名稱。
按一下「負載平衡器」的名稱。系統會顯示「負載平衡詳細資料」頁面。
查看「後端服務」一節中的表格,判斷外部 Ingress 是否使用 NEG 或執行個體群組。
如要解決這個問題,請採取下列任一做法:
- 使用 VPC 原生叢集。
- 針對外部 Ingress 參照的每個服務,使用
externalTrafficPolicy: Cluster。這個解決方案會導致您遺失封包來源中的原始用戶端 IP 位址。 - 使用
node.kubernetes.io/exclude-from-external-load-balancers=true註解。將註解新增至節點或節點集區,這些節點或節點集區不會為叢集中任何外部 Ingress 或LoadBalancerService 參照的任何 Service 執行任何服務 Pod。
使用負載平衡器記錄檔排解問題
您可以透過內部直通式網路負載平衡器記錄和外部直通式網路負載平衡器記錄,排解負載平衡器問題,並將負載平衡器的流量與 GKE 資源建立關聯。
系統會依連線匯總記錄,並以近乎即時的速度匯出。系統會為參與 LoadBalancer 服務資料路徑的每個 GKE 節點產生記錄,包括輸入和輸出流量。記錄項目包含 GKE 資源的其他欄位,例如:
- 叢集名稱
- 叢集位置
- 服務名稱
- 服務命名空間
- Pod 名稱
- Pod 命名空間
定價
使用記錄不會產生額外費用。視記錄的擷取方式而定,這項服務以 Cloud Logging、BigQuery 或 Pub/Sub 的標準價格計費。啟用記錄不會影響負載平衡器的效能。
使用診斷工具排解問題
check-gke-ingress 診斷工具會檢查 Ingress 資源,找出常見的設定錯誤。您可以使用 check-gke-ingress 工具執行下列操作:
- 在叢集上執行
gcpdiag指令列工具。檢查規則gke/ERR/2023_004部分會顯示 Ingress 結果。 - 按照check-gke-ingress中的操作說明,單獨使用
check-gke-ingress工具,或將其做為 kubectl 外掛程式。
後續步驟
如果無法在說明文件中找到問題的解決方法,請參閱「取得支援」一文,尋求進一步的協助, 包括下列主題的建議:
- 與 Cloud 客戶服務聯絡,建立支援案件。
- 在 StackOverflow 上提問,並使用
google-kubernetes-engine標記搜尋類似問題,向社群尋求支援。你也可以加入#kubernetes-engineSlack 頻道,取得更多社群支援。 - 使用公開版 Issue Tracker 開啟錯誤或功能要求。