이 페이지에서는 GKE 추론 게이트웨이의 추론 인프라 새 버전을 점진적으로 배포하는 증분 출시 작업을 수행하는 방법을 보여줍니다. 이 게이트웨이를 사용하면 추론 인프라를 안전하고 제어된 방식으로 업데이트할 수 있습니다. 서비스 중단을 최소화하면서 노드, 기본 모델, LoRA 어댑터를 업데이트할 수 있습니다. 이 페이지에서는 안정적인 배포를 위해 트래픽 분할 및 롤백에 관한 안내도 제공합니다.
이 페이지는 GKE 추론 게이트웨이의 출시 작업을 수행하려는 GKE ID 및 계정 관리자와 개발자를 대상으로 합니다.
다음 사용 사례가 지원됩니다.
노드 출시 업데이트
노드 업데이트는 추론 워크로드를 새 노드 하드웨어 또는 액셀러레이터 구성으로 안전하게 이전합니다. 이 프로세스는 모델 서비스를 중단하지 않고 제어된 방식으로 실행됩니다. 하드웨어 업그레이드, 드라이버 업데이트 또는 보안 문제 해결 중에 서비스 중단을 최소화하려면 노드 업데이트를 사용하세요.
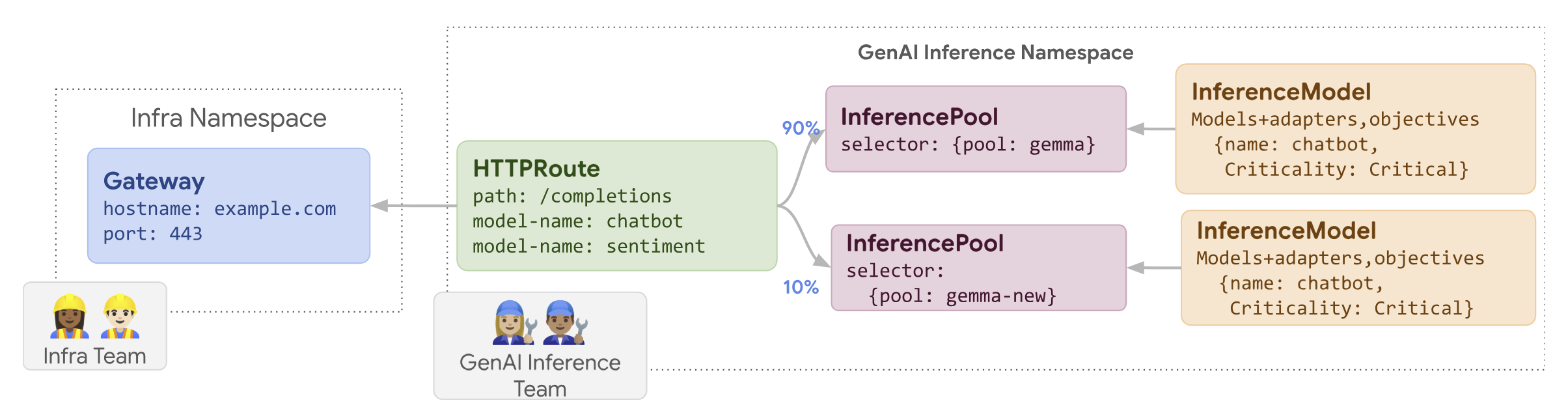
새
InferencePool만들기: 업데이트된 노드 또는 하드웨어 사양으로 구성된InferencePool를 배포합니다.HTTPRoute를 사용하여 트래픽 분할: 기존InferencePool리소스와 새InferencePool리소스 간에 트래픽을 분산하도록HTTPRoute를 구성합니다.backendRefs의weight필드를 사용하여 새 노드로 전달되는 트래픽 비율을 관리합니다.일관된
InferenceObjective유지: 기존InferenceObjective구성을 유지하여 두 노드 구성 모두에서 균일한 모델 동작을 보장합니다.원본 리소스 유지: 필요한 경우 롤백할 수 있도록 출시 중에 원래
InferencePool및 노드를 활성 상태로 유지합니다.
예를 들어 llm-new라는 새 InferencePool를 만들 수 있습니다. 기존 llm
InferencePool과 동일한 모델 구성으로 이 풀을 구성합니다. 클러스터 내의 새 노드 집합에 풀을 배포합니다. HTTPRoute 객체를 사용하여 원래 llm와 새 llm-new InferencePool 간에 트래픽을 분할합니다. 이 기법을 사용하면 모델 노드를 점진적으로 업데이트할 수 있습니다.
다음 다이어그램은 GKE 추론 게이트웨이가 노드 업데이트 출시를 실행하는 방법을 보여줍니다.
노드 업데이트 출시를 수행하려면 다음 단계를 따르세요.
다음 샘플 매니페스트를
routes-to-llm.yaml로 저장합니다.apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10샘플 매니페스트를 클러스터에 적용합니다.
kubectl apply -f routes-to-llm.yaml
원래 llm InferencePool는 대부분의 트래픽을 수신하고 llm-new InferencePool는 나머지를 수신합니다. 노드 업데이트 롤아웃을 완료하려면 llm-new InferencePool의 트래픽 가중치를 점진적으로 늘립니다.
기본 모델 출시
기존 LoRA 어댑터와의 호환성을 유지하면서 새로운 기본 LLM에 기본 모델 업데이트가 단계적으로 출시됩니다. 기본 모델 업데이트 출시를 사용하여 개선된 모델 아키텍처로 업그레이드하거나 모델 관련 문제를 해결할 수 있습니다.
기본 모델 업데이트를 출시하려면 다음 단계를 따르세요.
- 새 인프라 배포: 선택한 새 기본 모델로 구성된 새 노드와 새
InferencePool를 만듭니다. - 트래픽 분배 구성:
HTTPRoute를 사용하여 기존InferencePool(이전 기본 모델 사용)와 새InferencePool(새 기본 모델 사용) 간에 트래픽을 분할합니다.backendRefs weight필드는 각 풀에 할당된 트래픽 비율을 제어합니다. InferenceObjective무결성 유지:InferenceObjective구성을 변경하지 않습니다. 이렇게 하면 시스템이 두 기본 모델 버전 모두에 동일한 LoRA 어댑터를 일관되게 적용합니다.- 롤백 기능 유지: 필요한 경우 롤백을 용이하게 하기 위해 출시 중에 원래 노드와
InferencePool를 유지합니다.
llm-pool-version-2이라는 새 InferencePool을 만듭니다. 이 풀은 새 노드 집합에 기본 모델의 새 버전을 배포합니다. 제공된 예시에 표시된 대로 HTTPRoute을 구성하면 원래 llm-pool과 llm-pool-version-2 간에 트래픽을 점진적으로 분할할 수 있습니다. 이렇게 하면 클러스터에서 기본 모델 업데이트를 제어할 수 있습니다.
베이스 모델 업데이트 출시를 실행하려면 다음 단계를 따르세요.
다음 샘플 매니페스트를
routes-to-llm.yaml로 저장합니다.apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10샘플 매니페스트를 클러스터에 적용합니다.
kubectl apply -f routes-to-llm.yaml
원래 llm-pool InferencePool는 대부분의 트래픽을 수신하고 llm-pool-version-2 InferencePool는 나머지를 수신합니다. llm-pool-version-2 InferencePool의 트래픽 가중치를 점진적으로 늘려 기본 모델 업데이트 출시를 완료합니다.