En esta página se explica cómo realizar operaciones de lanzamiento incremental para desplegar gradualmente nuevas versiones de tu infraestructura de inferencia en GKE Inference Gateway. Esta pasarela te permite realizar actualizaciones seguras y controladas de tu infraestructura de inferencia. Puedes actualizar nodos, modelos base y adaptadores LoRA con una interrupción mínima del servicio. Esta página también ofrece directrices sobre la división del tráfico y las reversiones para garantizar que las implementaciones sean fiables.
Esta página está dirigida a administradores de identidades y cuentas de GKE, así como a desarrolladores que quieran llevar a cabo operaciones de lanzamiento de GKE Inference Gateway.
Se admiten los siguientes casos prácticos:
- Implementación de la actualización de nodos (de computación y aceleradores)
- Lanzamiento de la actualización del modelo base
Actualizar un lanzamiento de nodos
Las actualizaciones de nodos migran de forma segura las cargas de trabajo de inferencia a nuevo hardware de nodos o configuraciones de aceleradores. Este proceso se lleva a cabo de forma controlada sin interrumpir el servicio del modelo. Usa las actualizaciones de nodos para minimizar las interrupciones del servicio durante las actualizaciones de hardware, las actualizaciones de controladores o la resolución de problemas de seguridad.
Crea un
InferencePool: implementa unInferencePoolconfigurado con las especificaciones de hardware o nodo actualizadas.Dividir el tráfico mediante un
HTTPRoute: configura unHTTPRoutepara distribuir el tráfico entre los recursosInferencePoolactuales y los nuevos. Usa el campoweightdebackendRefspara gestionar el porcentaje de tráfico dirigido a los nuevos nodos.Mantener una
InferenceObjectivecoherente: conserva la configuración deInferenceObjectivepara asegurar un comportamiento uniforme del modelo en ambas configuraciones de nodos.Conservar los recursos originales: mantén activos los
InferencePooly los nodos originales durante la implementación para poder revertir los cambios si es necesario.
Por ejemplo, puedes crear un nuevo InferencePool llamado llm-new. Configura este grupo con la misma configuración de modelo que tu llm
InferencePool. Despliega el grupo en un nuevo conjunto de nodos de tu clúster. Usa un objeto HTTPRoute para dividir el tráfico entre el llm original y el llm-new InferencePool nuevo. Esta técnica te permite actualizar de forma incremental los nodos de tu modelo.
En el siguiente diagrama se muestra cómo lleva a cabo GKE Inference Gateway una implementación de actualización de nodos.
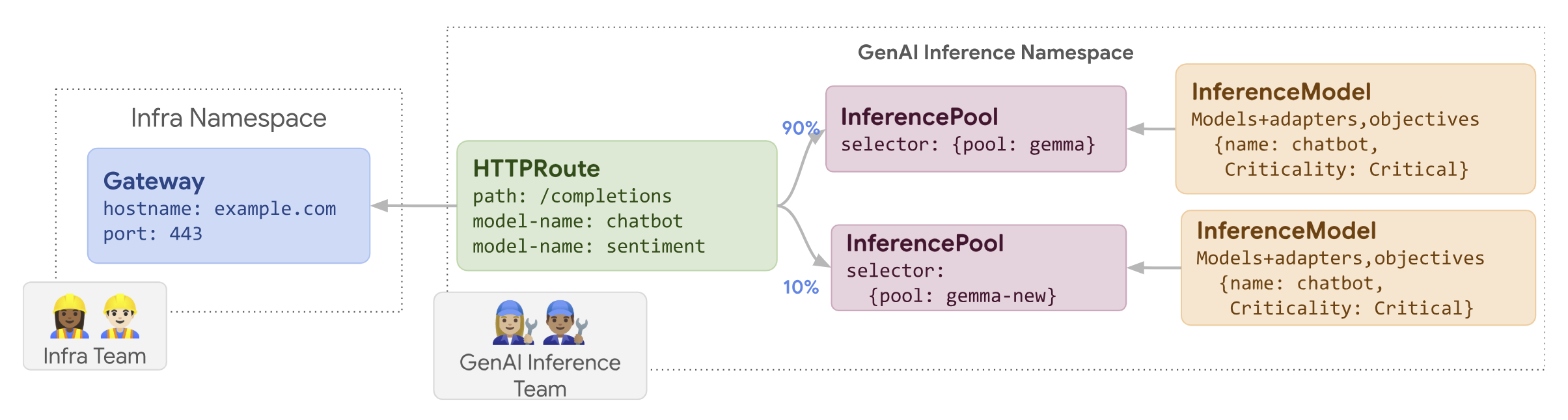
Para llevar a cabo una implementación de actualización de nodos, sigue estos pasos:
Guarda el siguiente archivo de manifiesto de ejemplo como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Aplica el manifiesto de ejemplo a tu clúster:
kubectl apply -f routes-to-llm.yaml
La llm original InferencePool recibe la mayor parte del tráfico, mientras que la llm-new InferencePool recibe el resto. Aumenta el peso del tráfico gradualmente
del llm-new InferencePool para completar la implementación de la actualización del nodo.
Lanzar un modelo base
Las actualizaciones del modelo base se lanzan por fases a un nuevo LLM base, manteniendo la compatibilidad con los adaptadores LoRA actuales. Puedes usar las implementaciones de actualizaciones de modelos base para cambiar a arquitecturas de modelos mejoradas o para solucionar problemas específicos de los modelos.
Para lanzar una actualización de un modelo base, sigue estos pasos:
- Implementar nueva infraestructura: crea nodos y un nuevo
InferencePoolconfigurado con el nuevo modelo base que has elegido. - Configurar la distribución del tráfico: usa un
HTTPRoutepara dividir el tráfico entre elInferencePool(que usa el modelo base antiguo) y el nuevoInferencePool(que usa el modelo base nuevo). El campobackendRefs weightcontrola el porcentaje de tráfico asignado a cada grupo. - Mantener la integridad de
InferenceObjective: no cambie la configuración deInferenceObjective. De esta forma, el sistema aplica los mismos adaptadores LoRA de forma coherente en ambas versiones del modelo base. - Conservar la capacidad de revertir: conserva los nodos y
InferencePooloriginales durante el lanzamiento para facilitar la reversión si es necesario.
Crea un nuevo InferencePool llamado llm-pool-version-2. Este grupo despliega una nueva versión del modelo base en un nuevo conjunto de nodos. Si configura un HTTPRoute, como se muestra en el ejemplo, puede dividir el tráfico de forma incremental entre el llm-pool original y el llm-pool-version-2. De esta forma, puedes controlar las actualizaciones del modelo base en tu clúster.
Para lanzar una actualización del modelo base, sigue estos pasos:
Guarda el siguiente archivo de manifiesto de ejemplo como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Aplica el manifiesto de ejemplo a tu clúster:
kubectl apply -f routes-to-llm.yaml
La llm-pool original InferencePool recibe la mayor parte del tráfico, mientras que la llm-pool-version-2 InferencePool recibe el resto. Aumenta el peso del tráfico de forma gradual para llm-pool-version-2 InferencePool para completar el lanzamiento de la actualización del modelo base.