Auf dieser Seite wird beschrieben, wie Sie für das GKE Inference Gateway Vorgänge für die inkrementelle Bereitstellung ausführen, mit denen neue Versionen Ihrer Inferenzinfrastruktur nach und nach bereitgestellt werden. Über dieses Gateway können Sie sichere und kontrollierte Updates für Ihre Inferenzinfrastruktur durchführen. Sie können Knoten, Basismodelle und LoRA-Adapter mit minimalen Dienstunterbrechungen aktualisieren. Auf dieser Seite finden Sie auch Anleitungen zum Aufteilen von Traffic und zum Ausführen von Rollbacks, um zuverlässige Bereitstellungen zu gewährleisten.
Diese Seite richtet sich an GKE-Identitäts- und Kontoadministratoren sowie Entwickler, die Rollout-Vorgänge für GKE Inference Gateway ausführen möchten.
Die folgenden Anwendungsfälle werden unterstützt:
Knoten-Rollout aktualisieren
Bei Knotenupdates werden Inferenzarbeitslasten sicher auf neue Knotenhardware oder Beschleunigerkonfigurationen migriert. Dieser Vorgang erfolgt kontrolliert, ohne den Model-Dienst zu unterbrechen. Mit Knotenupdates können Sie Dienstunterbrechungen bei Hardware-Upgrades, Treiberupdates oder der Behebung von Sicherheitsproblemen minimieren.
Neues
InferencePoolerstellen: Stellen Sie einInferencePoolmit den aktualisierten Knoten- oder Hardwarespezifikationen bereit.Traffic mit einem
HTTPRouteaufteilen: Konfigurieren Sie einHTTPRoute, um den Traffic zwischen den vorhandenen und neuenInferencePool-Ressourcen aufzuteilen. Verwenden Sie das FeldweightinbackendRefs, um den Prozentsatz des Traffics zu verwalten, der an die neuen Knoten weitergeleitet wird.Konsistente
InferenceObjectivebeibehalten: Behalten Sie die vorhandeneInferenceObjective-Konfiguration bei, um ein einheitliches Modellverhalten in beiden Knotenkonfigurationen zu gewährleisten.Originalressourcen beibehalten: Behalten Sie die ursprünglichen
InferencePoolund Knoten während der Einführung bei, um bei Bedarf Rollbacks zu ermöglichen.
Sie können beispielsweise eine neue InferencePool mit dem Namen llm-new erstellen. Konfigurieren Sie diesen Pool mit derselben Modellkonfiguration wie Ihre vorhandene llm
InferencePool. Stellen Sie den Pool auf einer neuen Gruppe von Knoten in Ihrem Cluster bereit. Verwenden Sie ein HTTPRoute-Objekt, um den Traffic zwischen dem ursprünglichen llm und dem neuen llm-new InferencePool aufzuteilen. Mit dieser Technik können Sie Ihre Modellknoten inkrementell aktualisieren.
Das folgende Diagramm zeigt, wie GKE Inference Gateway ein Node-Update-Roll-out durchführt.
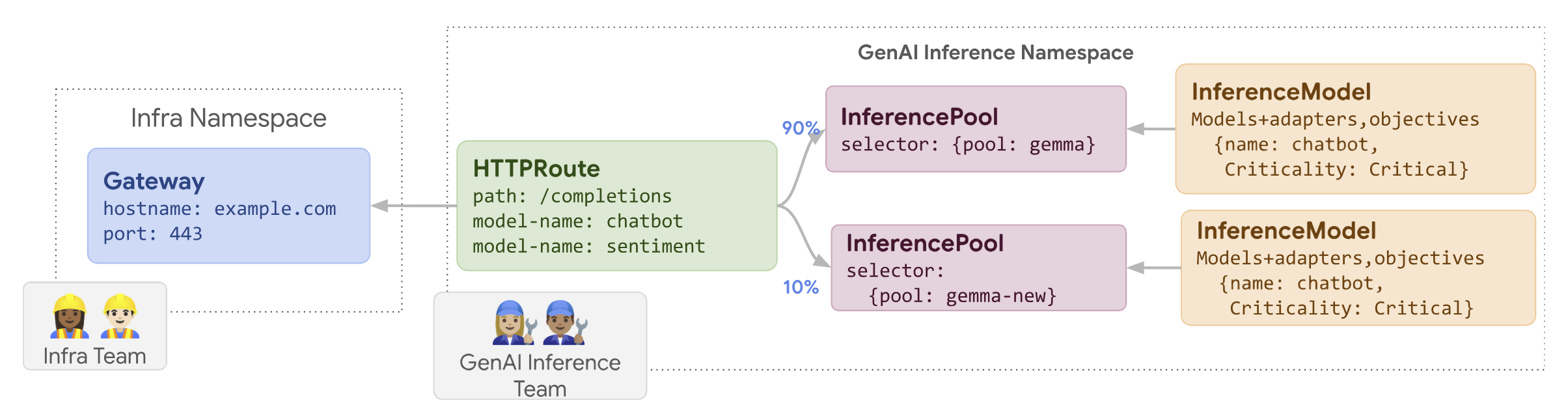
So führen Sie ein Knotenupdate durch:
Speichern Sie das folgende Beispielmanifest als
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Wenden Sie das Beispielmanifest auf Ihren Cluster an:
kubectl apply -f routes-to-llm.yaml
Die ursprüngliche llm InferencePool erhält den Großteil des Traffics, die llm-new InferencePool den Rest. Erhöhen Sie das Traffic-Gewicht für llm-new InferencePool nach und nach, um die Einführung des Knotenupdates abzuschließen.
Basismodell einführen
Updates des Basismodells werden in Phasen auf ein neues Basis-LLM übertragen, wobei die Kompatibilität mit vorhandenen LoRA-Adaptern erhalten bleibt. Sie können die Einführung von Updates für das Basismodell nutzen, um auf verbesserte Modellarchitekturen umzustellen oder modellspezifische Probleme zu beheben.
So führen Sie ein Update eines Basismodells aus:
- Neue Infrastruktur bereitstellen: Erstellen Sie neue Knoten und einen neuen
InferencePool, der mit dem neuen ausgewählten Basismodell konfiguriert ist. - Traffic-Verteilung konfigurieren: Verwenden Sie ein
HTTPRoute, um den Traffic zwischen dem vorhandenenInferencePool(mit dem alten Basismodell) und dem neuenInferencePool(mit dem neuen Basismodell) aufzuteilen. Mit dem FeldbackendRefs weightwird der Prozentsatz des Traffics gesteuert, der jedem Pool zugewiesen wird. - Integrität von
InferenceObjectivebeibehalten: DieInferenceObjective-Konfiguration bleibt unverändert. So wird sichergestellt, dass das System dieselben LoRA-Adapter konsistent für beide Basismodellversionen anwendet. - Rollback-Funktion beibehalten: Behalten Sie die ursprünglichen Knoten und
InferencePoolwährend der Einführung bei, um bei Bedarf ein Rollback zu ermöglichen.
Sie erstellen ein neues InferencePool mit dem Namen llm-pool-version-2. In diesem Pool wird eine neue Version des Basismodells auf einer neuen Gruppe von Knoten bereitgestellt. Wenn Sie eine HTTPRoute konfigurieren, wie im Beispiel gezeigt, können Sie den Traffic schrittweise zwischen dem ursprünglichen llm-pool und llm-pool-version-2 aufteilen. So können Sie Updates des Basismodells in Ihrem Cluster steuern.
So führen Sie die Einführung eines Updates für das Basismodell durch:
Speichern Sie das folgende Beispielmanifest als
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Wenden Sie das Beispielmanifest auf Ihren Cluster an:
kubectl apply -f routes-to-llm.yaml
Die ursprüngliche llm-pool InferencePool erhält den Großteil des Traffics, die llm-pool-version-2 InferencePool den Rest. Erhöhen Sie das Trafficgewicht für llm-pool-version-2 InferencePool schrittweise, um die Einführung des Updates des Basismodells abzuschließen.