このページでは、GKE Inference Gateway のデプロイをカスタマイズする方法について説明します。
このページは、GKE インフラストラクチャの管理を担当するネットワーク スペシャリストと、AI ワークロードを管理するプラットフォーム管理者を対象としています。
推論ワークロードを管理して最適化するには、GKE Inference Gateway の高度な機能を構成します。
次の高度な機能について理解し、構成してください。
- Model Armor の統合を使用するには、AI セキュリティと安全性チェックを構成します。
- API セキュリティ、レート制限、分析などの機能で GKE Inference Gateway を強化するには、認証と API 管理用に Apigee を構成します。
- リクエスト本文のモデル名に基づいてリクエストをルーティングするには、本文ベースのルーティングを構成します。
- GKE Inference Gateway とモデルサーバーの指標とダッシュボードを表示し、HTTP アクセス ロギングを有効にするには、オブザーバビリティを構成します。
- GKE Inference Gateway のデプロイを自動的にスケーリングするには、自動スケーリングを構成します。
AI セキュリティと安全性チェックを構成する
GKE Inference Gateway は Model Armor と統合されており、大規模言語モデル(LLM)を使用するアプリケーションのプロンプトとレスポンスを安全性チェックします。この統合により、アプリケーション レベルの安全対策を補完する、インフラストラクチャ レベルの安全性強化レイヤが追加されます。これにより、すべての LLM トラフィックにポリシーを一元的に適用できます。
次の図は、GKE クラスタの GKE Inference Gateway と Model Armor の統合を示したものです。
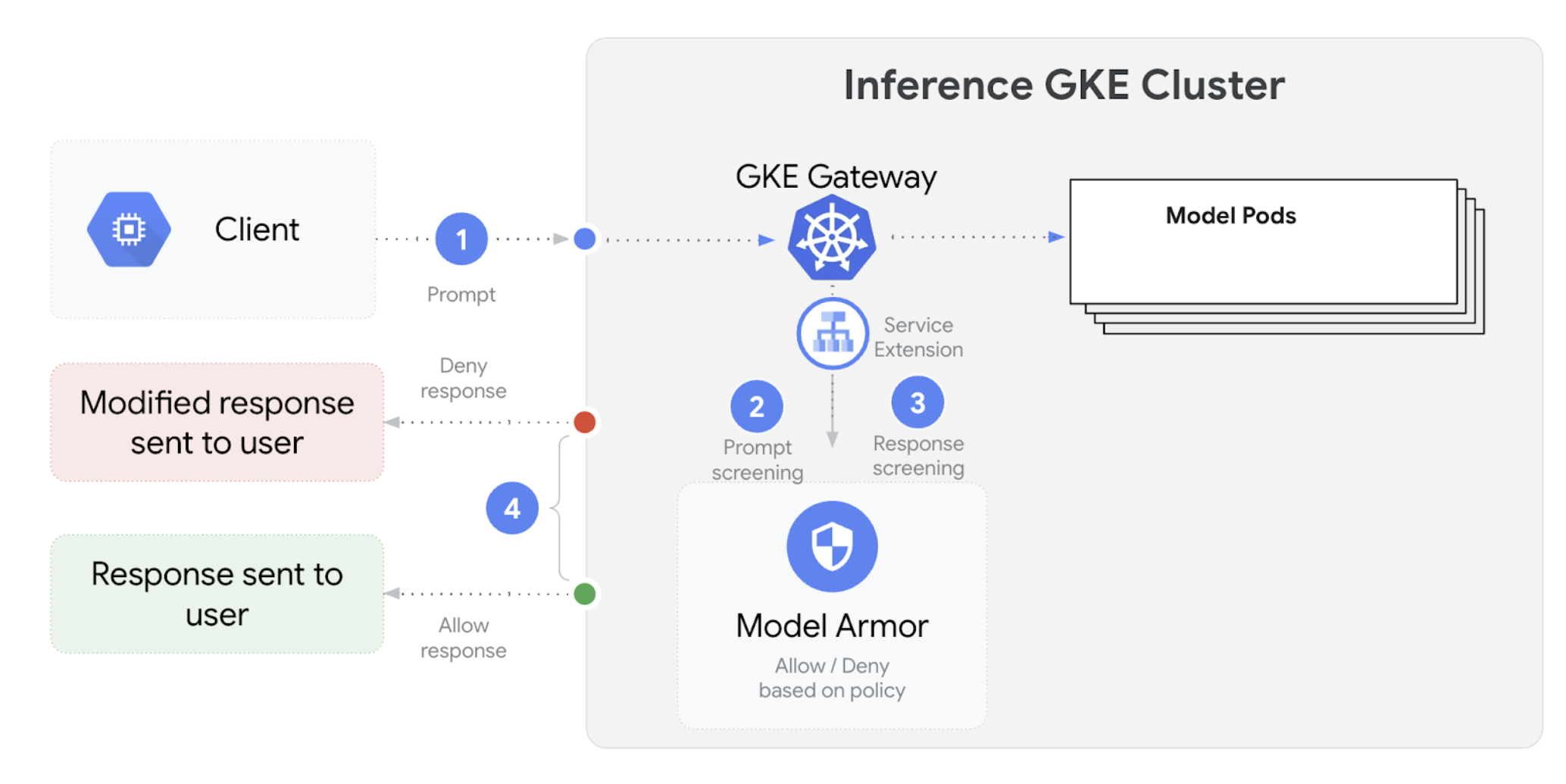
AI 安全性チェックを構成する手順は次のとおりです。
前提条件
- Google Cloud プロジェクトで Model Armor サービスを有効にします。
Model Armor コンソール、Google Cloud CLI、または API を使用して Model Armor テンプレートを作成します。次のコマンドは、オペレーションをロギングし、有害なコンテンツをフィルタする
llmという名前のテンプレートを作成します。# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
IAM 権限を付与
Service Extensions サービス アカウントには、必要なリソースにアクセスするための権限が必要です。次のコマンドを実行して、必要なロールを付与します。
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.userGCPTrafficExtensionを構成するModel Armor ポリシーを Gateway に適用するには、正しいメタデータ形式で
GCPTrafficExtensionリソースを作成します。次のサンプル マニフェストを
gcp-traffic-extension.yamlとして保存します。kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'次のように置き換えます。
GATEWAY_NAME: Gatewayの名前MODEL_ARMOR_TEMPLATE_NAME: Model Armor テンプレートの名前。
gcp-traffic-extension.yamlファイルには次の設定が含まれます。targetRefs: この拡張機能が適用される Gateway を指定します。extensionChains: トラフィックに適用する一連の拡張機能を定義します。matchCondition: 拡張機能が適用される条件を定義します。extensions: 適用する拡張機能を定義します。supportedEvents: 拡張機能が呼び出されるイベントを指定します。timeout: 拡張機能のタイムアウトを指定します。googleAPIServiceName: 拡張機能のサービス名を指定します。metadata:extensionPolicyやプロンプトまたはレスポンスのサニタイズ設定など、拡張機能のメタデータを指定します。
マニフェストをクラスタに適用します。
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
AI 安全性チェックを構成して Gateway と統合すると、Model Armor は定義されたルールに基づいてプロンプトとレスポンスを自動的にフィルタします。
認証と API 管理用に Apigee を構成する
GKE Inference Gateway は Apigee と統合され、推論ワークロードの認証、認可、API 管理を提供します。Apigee を使用するメリットについては、Apigee を使用する主なメリットをご覧ください。
GKE Inference Gateway を Apigee と統合して、API セキュリティ、レート制限、割り当て、分析、収益化などの機能で GKE Inference Gateway を強化できます。
前提条件
始める前に、次の準備をしてください。
- バージョン 1.34.* 以降を実行している GKE クラスタ。
- GKE Inference Gateway がデプロイされた GKE クラスタ。
- GKE クラスタと同じリージョンに作成された Apigee インスタンス。
- Apigee APIM Operator とその CRD が GKE クラスタにインストールされている。手順については、Apigee APIM Operator をインストールするをご覧ください。
- GKE クラスタに接続するように構成された
kubectl。 Google Cloud CLIがインストールされ、認証されていること。
ApigeeBackendService を作成します。
まず、ApigeeBackendService リソースを作成します。GKE Inference Gateway は、これを使用して Apigee Extension Processor を作成します。
次のマニフェストを
my-apigee-backend-service.yamlとして保存します。apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"次のように置き換えます。
APIGEE_ENVIRONMENT_NAME: Apigee 環境の名前。注:generateEnv=TRUEフラグを使用してapigee-apim-operatorをインストールした場合は、このフィールドを設定する必要はありません。ない場合は、環境を作成するの手順に沿って Apigee 環境を作成します。LOCATION: Apigee インスタンスのロケーション。CLUSTER_NETWORK: GKE クラスタのネットワーク。CLUSTER_SUBNETWORK: GKE クラスタのサブネットワーク。
マニフェストをクラスタに適用します。
kubectl apply -f my-apigee-backend-service.yamlステータスが
CREATEDになっていることを確認します。kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
GKE Inference Gateway を構成する
Apigee Extension Processor をロードバランサ トラフィック拡張機能として有効にするように GKE Inference Gateway を構成します。
次のマニフェストを
my-apigee-traffic-extension.yamlとして保存します。kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443GATEWAY_NAMEは実際のプロジェクト名に置き換えます。マニフェストをクラスタに適用します。
kubectl apply -f my-apigee-traffic-extension.yamlGCPTrafficExtensionステータスがProgrammedになるまで待ちます。kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
API キーを使用して認証済みリクエストを送信する
GKE Inference Gateway の IP アドレスを確認するには、Gateway のステータスを調べます。
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')GATEWAY_NAMEは実際のプロジェクト名に置き換えます。認証なしでリクエストをテストします。このリクエストは拒否されるはずです。
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'次のようなレスポンスが表示され、Apigee 拡張機能が動作していることが示されます。
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Apigee UI にアクセスして API キーを作成します。手順については、API キーを作成するをご覧ください。
HTTP リクエスト ヘッダーで API キーを送信します。
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'API_KEYを API キーに置き換えます。
Apigee ポリシーの構成の詳細については、Apigee APIM Operator for Kubernetes で API 管理ポリシーを使用するをご覧ください。
オブザーバビリティを構成する
GKE Inference Gateway は、推論ワークロードの健全性、パフォーマンス、動作に関する分析情報を提供します。これは、問題を特定して解決し、リソース使用率を最適化し、アプリケーションの信頼性を保証する上で役立ちます。
Google Cloud では、GKE Inference Gateway の推論オブザーバビリティを提供する次の Cloud Monitoring ダッシュボードをご覧いただけます。
- GKE Inference Gateway ダッシュボード: LLM 処理に関するゴールデン指標(
InferencePoolに対するリクエストとトークンのスループット、レイテンシ、エラー、キャッシュ使用率など)を確認できます。使用可能な GKE Inference Gateway の指標の一覧については、公開されている指標をご覧ください。 - AI/ML オブザーバビリティ ダッシュボード: インフラストラクチャの使用状況、DCGM 指標、vLLM モデルのパフォーマンス指標のダッシュボードを提供します。
- モデルサーバー ダッシュボード: モデルサーバーのゴールデン シグナルのダッシュボードです。このダッシュボードでは、
KVCache UtilizationやQueue lengthなどのモデルサーバーの負荷とパフォーマンスをモニタリングできます。 - ロードバランサ ダッシュボード: ロードバランサの指標(1 秒あたりのリクエスト数、エンド ツー エンドのリクエスト処理レイテンシ、リクエスト / レスポンスのステータス コードなど)をレポートします。これらの指標は、エンド ツー エンドのリクエスト処理のパフォーマンスを把握し、エラーを特定するのに役立ちます。
- Data Center GPU Manager(DCGM)指標: NVIDIA GPU のパフォーマンスや使用率など、DCGM 指標を確認できます。DCGM 指標は、Cloud Monitoring で構成できます。詳細については、DCGM 指標を収集して表示するをご覧ください。
GKE Inference Gateway ダッシュボードを表示する
GKE Inference Gateway ダッシュボードを表示する手順は次のとおりです。
Google Cloud コンソールで、[モニタリング] ページに移動します。
ナビゲーション パネルで [ダッシュボード] を選択します。
[統合] セクションで [GMP] を選択します。
[Cloud Monitoring ダッシュボード テンプレート] ページで、[ゲートウェイ] を検索します。
GKE Inference Gateway ダッシュボードを表示します。
または、モニタリング ダッシュボードの手順に沿って操作することもできます。
AI/ML モデルのオブザーバビリティ ダッシュボードを表示する
デプロイされたモデルとモデルのオブザーバビリティ指標のダッシュボードを表示する手順は次のとおりです。
Google Cloud コンソールで、[デプロイされるモデル] ページに移動します。
特定のデプロイの詳細(指標、ログ、ダッシュボードなど)を表示するには、リスト内のモデル名をクリックします。
モデルの詳細ページで、[オブザーバビリティ] タブをクリックして、次のダッシュボードを表示します。プロンプトが表示されたら、[有効にする] をクリックしてダッシュボードを有効にします。
- [インフラストラクチャの使用量] ダッシュボードには、使用率の指標が表示されます。
- [DCGM] ダッシュボードには、DCGM 指標が表示されます。
- vLLM を使用している場合は、[モデルのパフォーマンス] ダッシュボードが使用可能になり、vLLM モデルのパフォーマンスの指標が表示されます。
モデルサーバーのオブザーバビリティ ダッシュボードを構成する
各モデルサーバーからゴールデン シグナルを収集し、GKE Inference Gateway のパフォーマンスに影響を与えている要因を把握するには、モデルサーバーの自動モニタリングを構成します。これには、次のようなモデルサーバーが含まれます。
統合ダッシュボードを表示するには、まずモデルサーバーから指標を収集していることを確認します。以下の手順に沿って操作を行います。
Google Cloud コンソールで、[モニタリング] ページに移動します。
ナビゲーション パネルで [ダッシュボード] を選択します。
[統合] で [GMP] を選択します。該当する統合ダッシュボードが表示されます。

図: 統合ダッシュボード
詳細については、アプリケーションのモニタリングをカスタマイズするをご覧ください。
Cloud Monitoring アラートを構成する
GKE Inference Gateway の Cloud Monitoring アラートを構成する手順は次のとおりです。
次のサンプル マニフェストを
alerts.yamlとして保存し、必要に応じてしきい値を変更します。groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'アラート ポリシーを作成するには、次のコマンドを実行します。
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yaml[アラート] ページに新しいアラート ポリシーが表示されます。
アラートを変更する
使用可能な最新の指標の完全なリストは、kubernetes-sigs/gateway-api-inference-extension GitHub リポジトリで確認できます。また、他の指標を使用して、新しいアラートをマニフェストに追加することもできます。
サンプル アラートを変更するには、次の例を参考にしてください。
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
このアラートは、5 分間のリクエスト時間の 99 パーセンタイルが 10 秒を超えると作動します。要件に合わせてしきい値を調整するために、アラートの expr セクションを変更できます。
GKE Inference Gateway のロギングを構成する
GKE Inference Gateway のロギングを構成して、リクエストとレスポンスの詳細情報を確認しましょう。これは、トラブルシューティング、監査、パフォーマンス分析に役立ちます。HTTP アクセス ログには、ヘッダー、ステータス コード、タイムスタンプなど、すべてのリクエストとレスポンスが記録されます。このレベルの詳細は、問題の特定、エラーの検出、推論ワークロードの動作の把握に役立ちます。
GKE Inference Gateway のロギングを構成するには、各 InferencePool オブジェクトの HTTP アクセス ロギングを有効にします。
次のサンプル マニフェストを
logging-backend-policy.yamlとして保存します。apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAME次のように置き換えます。
NAMESPACE_NAME:InferencePoolがデプロイされる名前空間の名前。INFERENCE_POOL_NAME:InferencePoolの名前。
マニフェストをクラスタに適用します。
kubectl apply -f logging-backend-policy.yaml
このマニフェストを適用すると、GKE Inference Gateway は指定された InferencePool の HTTP アクセスログを有効にします。これらのログは Cloud Logging で確認できます。ログでは、各リクエストとレスポンスの詳細情報、例えば、リクエスト URL、ヘッダー、レスポンス ステータス コード、レイテンシなどを確認できます。
ログベースの指標を作成してエラーの詳細を表示する
ログベースの指標を使用して、ロード バランシング ログを分析し、エラーの詳細を抽出できます。gke-l7-global-external-managed や gke-l7-regional-internal-managed などの各 GKE Gateway クラスは、異なるロードバランサによってバックアップされます。詳細については、GatewayClass の機能をご覧ください。
ロードバランサごとに異なるモニタリング対象リソースがあります。ログベースの指標を作成するときは、このリソースを使用する必要があります。各ロードバランサのモニタリング対象リソースの詳細については、以下をご覧ください。
- リージョン外部ロードバランサの場合: 外部 HTTP(S) ロードバランサのログベースの指標
- 内部ロードバランサの場合: 内部 HTTP(S) ロードバランサのログベースの指標
エラーの詳細を表示するログベースの指標を作成するには、次の操作を行います。
LogMetric定義を含むerror_detail_metric.jsonという名前の JSON ファイルを作成します。この構成により、ロードバランサのログからproxyStatusフィールドを抽出する指標が作成されます。{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }MONITORED_RESOURCEは、ロードバランサのモニタリング対象リソースに置き換えます。Cloud Shell を開くか、gcloud CLI がインストールされているローカル ターミナルを開きます。
指標を作成するには、
--config-from-fileフラグを指定してgcloud logging metrics createコマンドを実行します。gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
指標を作成したら、Cloud Monitoring で使用して、ロードバランサから報告されたエラーの分布を表示できます。詳細については、ログベースの指標を作成するをご覧ください。
ログベースの指標からアラートを作成する方法については、カウンタ指標にアラート ポリシーを作成するをご覧ください。
自動スケーリングを構成する
自動スケーリングは、ワークロードの変化に応じてリソース割り当てを調整し、また需要に応じて Pod を動的に追加または削除してパフォーマンスとリソース効率を維持します。GKE Inference Gateway の場合、これは各 InferencePool の Pod の水平自動スケーリングを伴います。GKE Horizontal Pod Autoscaler(HPA)は、KVCache Utilization などのモデルサーバー 指標に基づいて Pod を自動スケーリングします。これにより、推論サービスはリソース使用量を効率的に管理しながら、さまざまなワークロードとクエリ量を処理できます。
GKE Inference Gateway によって生成された指標に基づいて自動スケーリングされるように InferencePool インスタンスを構成するには、次の操作を行います。
クラスタに
PodMonitoringオブジェクトをデプロイして、GKE Inference Gateway によって生成された指標を収集します。詳細については、オブザーバビリティを構成するをご覧ください。Custom Metrics Stackdriver Adapterをデプロイして、HPA に指標へのアクセス権を付与します。
次のサンプル マニフェストを
adapter_new_resource_model.yamlとして保存します。apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemマニフェストをクラスタに適用します。
kubectl apply -f adapter_new_resource_model.yaml
プロジェクトから指標を読み取る権限をアダプターに付与するには、次のコマンドを実行します。
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterPROJECT_IDは、実際の Google Cloud PROJECT_ID に置き換えます。InferencePoolごとに、次のような HPA を 1 つデプロイします。apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUE次のように置き換えます。
INFERENCE_POOL_NAME:InferencePoolの名前。INFERENCE_POOL_NAMESPACE:InferencePoolの名前空間。CLUSTER_NAME: クラスタの名前。MIN_REPLICAS:InferencePoolの最小可用性(ベースライン容量)。使用率が HPA ターゲットしきい値を下回っている場合、HPA はこのレプリカ数を維持します。高可用性ワークロードでは、Pod の中断中に可用性を維持するために、この値を1より大きい値に設定する必要があります。MAX_REPLICAS:InferencePoolでホストされているワークロードに割り当てる必要があるアクセラレータの数を制限する値。HPA は、この値を超えてレプリカ数を増やしません。トラフィックのピーク時にレプリカ数をモニタリングし、MAX_REPLICASフィールドの値に十分なヘッドルームがあることを確認しておくことで、ワークロードをスケールアップして選択したワークロードのパフォーマンス特性を維持できるようにしておきましょう。TARGET_VALUE: モデルサーバーごとに選択されたターゲットKV-Cache Utilizationを表す値。これは 0 ~ 100 の数値で、モデルサーバー、モデル、アクセラレータ、受信トラフィックの特性に大きく依存します。このターゲット値は、負荷テストを実施してスループットとレイテンシのグラフをプロットすることで、実験的に決定できます。グラフから選択したスループットとレイテンシの組み合わせを選択し、対応するKV-Cache Utilization値を HPA ターゲットとして使用します。選択した価格-パフォーマンス関係を達成するには、この値を微調整して注意深くモニタリングする必要があります。GKE Inference Quickstart を使用すると、この値を自動的に決定できます。
次のステップ
- GKE Inference Gateway について学習する。
- GKE Inference Gateway をデプロイします。
- GKE Inference Gateway のロールアウト オペレーションを管理する。
- GKE Inference Gateway を使用してサービングする。