En esta página se explican los conceptos y las funciones clave de Inference Gateway de Google Kubernetes Engine (GKE), una extensión de GKE Gateway que optimiza el servicio de aplicaciones de IA generativa.
En esta página se da por hecho que conoces los siguientes conceptos:
- Orquestación de IA y aprendizaje automático en GKE
- Terminología de la IA generativa
- Conceptos de redes de GKE, incluidos los servicios y la API GKE Gateway
- Balanceo de carga en Google Cloud, especialmente cómo interactúan los balanceadores de carga con GKE
Esta página está dirigida a los siguientes perfiles:
- Ingenieros de aprendizaje automático, administradores y operadores de plataformas, y especialistas en datos e IA que quieran usar las funciones de orquestación de contenedores de Kubernetes para servir cargas de trabajo de IA y aprendizaje automático.
- Arquitectos de Cloud y especialistas en redes que interactúan con las redes de Kubernetes.
Información general
GKE Inference Gateway es una extensión de GKE Gateway que ofrece enrutamiento y balanceo de carga optimizados para servir cargas de trabajo de IA generativa. Simplifica la implementación, la gestión y la observabilidad de las cargas de trabajo de inferencia de IA.
Para elegir la estrategia de balanceo de carga óptima para tus cargas de trabajo de IA o aprendizaje automático, consulta el artículo Elegir una estrategia de balanceo de carga para la inferencia de IA en GKE.
Características y ventajas
GKE Inference Gateway ofrece las siguientes funciones clave para servir de forma eficiente modelos de IA generativa para aplicaciones de IA generativa en GKE:
- Métricas admitidas:
KV cache hits: número de búsquedas correctas en la caché de clave-valor (KV).- Uso de la GPU o la TPU: porcentaje del tiempo que la GPU o la TPU está procesando activamente.
- Longitud de la cola de solicitudes: el número de solicitudes que están pendientes de procesarse.
- Balanceo de carga optimizado para la inferencia: distribuye las solicitudes para optimizar el rendimiento del servicio de modelos de IA. Usa métricas de servidores de modelos, como
KV cache hitsyqueue length of pending requests, para consumir aceleradores (como GPUs y TPUs) de forma más eficiente en cargas de trabajo de IA generativa. De esta forma, se habilita Prefix-Cache Aware Routing, una función clave que envía solicitudes con contexto compartido, identificadas mediante el análisis del cuerpo de la solicitud, a la misma réplica del modelo maximizando los aciertos de caché. Este enfoque reduce drásticamente las computaciones redundantes y mejora el tiempo hasta el primer token, lo que lo hace muy eficaz para la IA conversacional, la generación aumentada por recuperación (RAG) y otras cargas de trabajo de IA generativa basadas en plantillas. - Servicio de modelos ajustados con LoRA dinámico: admite el servicio de modelos ajustados con LoRA dinámico en un acelerador común. De esta forma, se reduce el número de GPUs y TPUs necesarios para servir modelos, ya que se multiplexan varios modelos ajustados con LoRA en un modelo base y un acelerador comunes.
- Autoescalado optimizado para la inferencia: el autoescalador horizontal de pods (HPA) de GKE usa métricas del servidor de modelos para autoescalar, lo que ayuda a asegurar un uso eficiente de los recursos de computación y un rendimiento de inferencia optimizado.
- Enrutamiento basado en el modelo: enruta las solicitudes de inferencia en función de los nombres de los modelos definidos en las
OpenAI APIespecificaciones de tu clúster de GKE. Puedes definir políticas de enrutamiento de Gateway, como la división del tráfico y la creación de réplicas de solicitudes, para gestionar diferentes versiones de modelos y simplificar los lanzamientos de modelos. Por ejemplo, puedes dirigir las solicitudes de un nombre de modelo específico a diferentesInferencePoolobjetos, cada uno de los cuales sirve una versión diferente del modelo. Para obtener más información sobre cómo configurar esta opción, consulta Configurar el enrutamiento basado en el cuerpo. - Seguridad de la IA y filtrado de contenido integrados: GKE Inference Gateway se integra con Google Cloud Model Armor para aplicar comprobaciones de seguridad de la IA y filtrado de contenido a las peticiones y respuestas en la puerta de enlace. Model Armor proporciona registros de solicitudes, respuestas y procesamiento para realizar análisis retrospectivos y optimizaciones. Las interfaces abiertas de GKE Inference Gateway permiten que los proveedores y desarrolladores externos integren servicios personalizados en el proceso de solicitud de inferencia.
- Servicio específico de modelos:
Priorityte permite especificar el servicioPriorityde modelos de IA. Prioriza las solicitudes sensibles a la latencia sobre las tareas de inferencia por lotes tolerantes a la latencia. Por ejemplo, puedes dar prioridad a las solicitudes de aplicaciones sensibles a la latencia y descartar las tareas menos sensibles al tiempo cuando los recursos sean limitados. - Observabilidad de la inferencia: proporciona métricas de observabilidad para las solicitudes de inferencia, como la frecuencia de solicitudes, la latencia, los errores y la saturación. Monitoriza el rendimiento y el comportamiento de tus servicios de inferencia a través de Cloud Monitoring y Cloud Logging, y aprovecha los paneles precompilados especializados para obtener información detallada. Para obtener más información, consulta Ver el panel de control de GKE Inference Gateway.
- Gestión avanzada de APIs con Apigee: se integra con Apigee para mejorar tu pasarela de inferencia con funciones como la seguridad de las APIs, la limitación de la frecuencia y las cuotas. Para obtener instrucciones detalladas, consulta Configurar Apigee para la autenticación y la gestión de APIs.
- Extensibilidad: se basa en una extensión de inferencia de API de Kubernetes Gateway de código abierto y extensible que admite un algoritmo de selector de endpoints gestionado por el usuario.
Entender los conceptos clave
GKE Inference Gateway mejora el GKE
Gateway que usa objetos GatewayClass. GKE Inference Gateway introduce las siguientes definiciones de recursos personalizados (CRDs) de la API Gateway, que se han alineado con la extensión de la API Gateway de Kubernetes de software libre para la inferencia:
- Objeto
InferencePool: representa un grupo de pods (contenedores) que comparten la misma configuración de computación, el mismo tipo de acelerador, el mismo modelo de lenguaje base y el mismo servidor de modelo. De esta forma, se agrupan y gestionan de forma lógica los recursos de publicación de tu modelo de IA. Un solo objetoInferencePoolpuede abarcar varios pods en diferentes nodos de GKE y proporciona escalabilidad y alta disponibilidad. - Objeto
InferenceObjective: especifica el nombre del modelo de servicio deInferencePoolsegún la especificaciónOpenAI API. El objetoInferenceObjectivetambién especifica las propiedades de servicio del modelo, como elPrioritydel modelo de IA. GKE Inference Gateway da prioridad a las cargas de trabajo con un valor de prioridad más alto. Esto te permite multiplexar cargas de trabajo de IA sensibles a la latencia y tolerantes a la latencia en un clúster de GKE. También puedes configurar elInferenceObjectiveobjeto para que sirva modelos ajustados con LoRA.
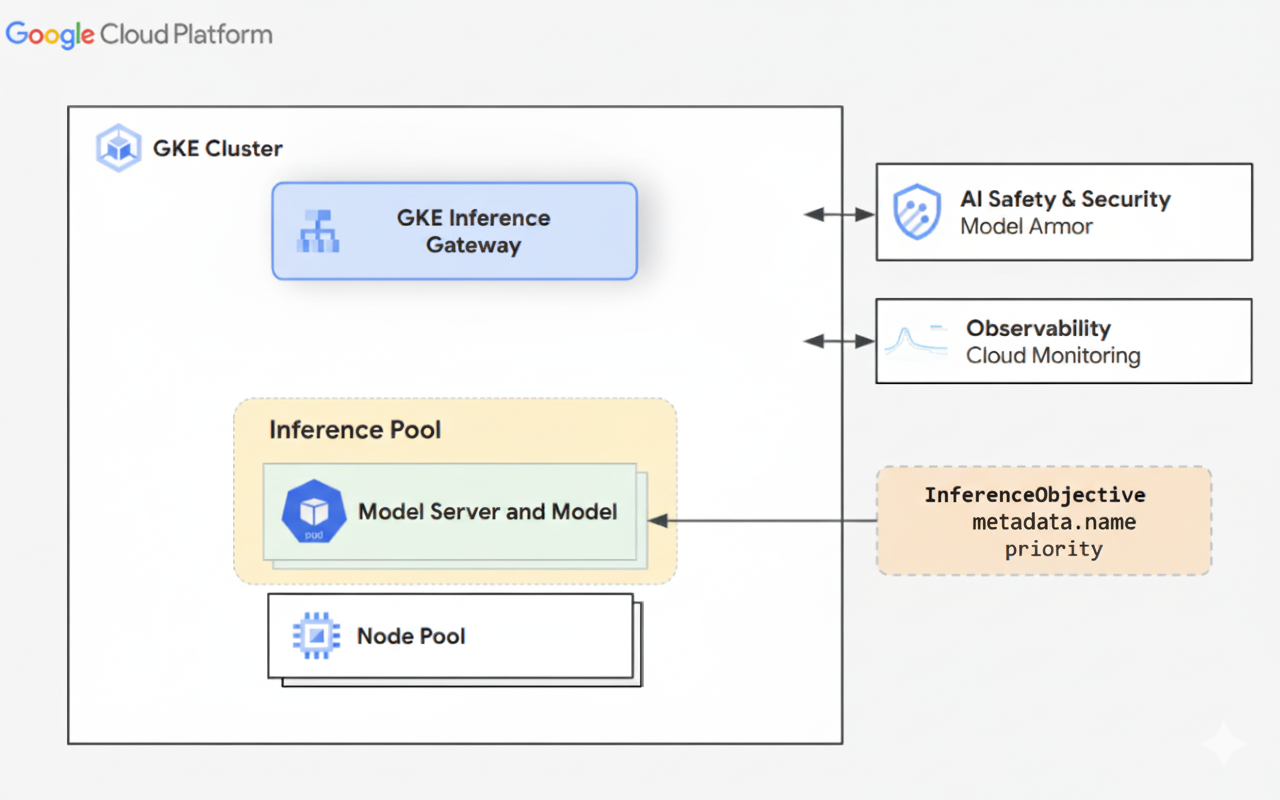
En el siguiente diagrama se muestra GKE Inference Gateway y su integración con la seguridad de la IA, la observabilidad y el servicio de modelos en un clúster de GKE.
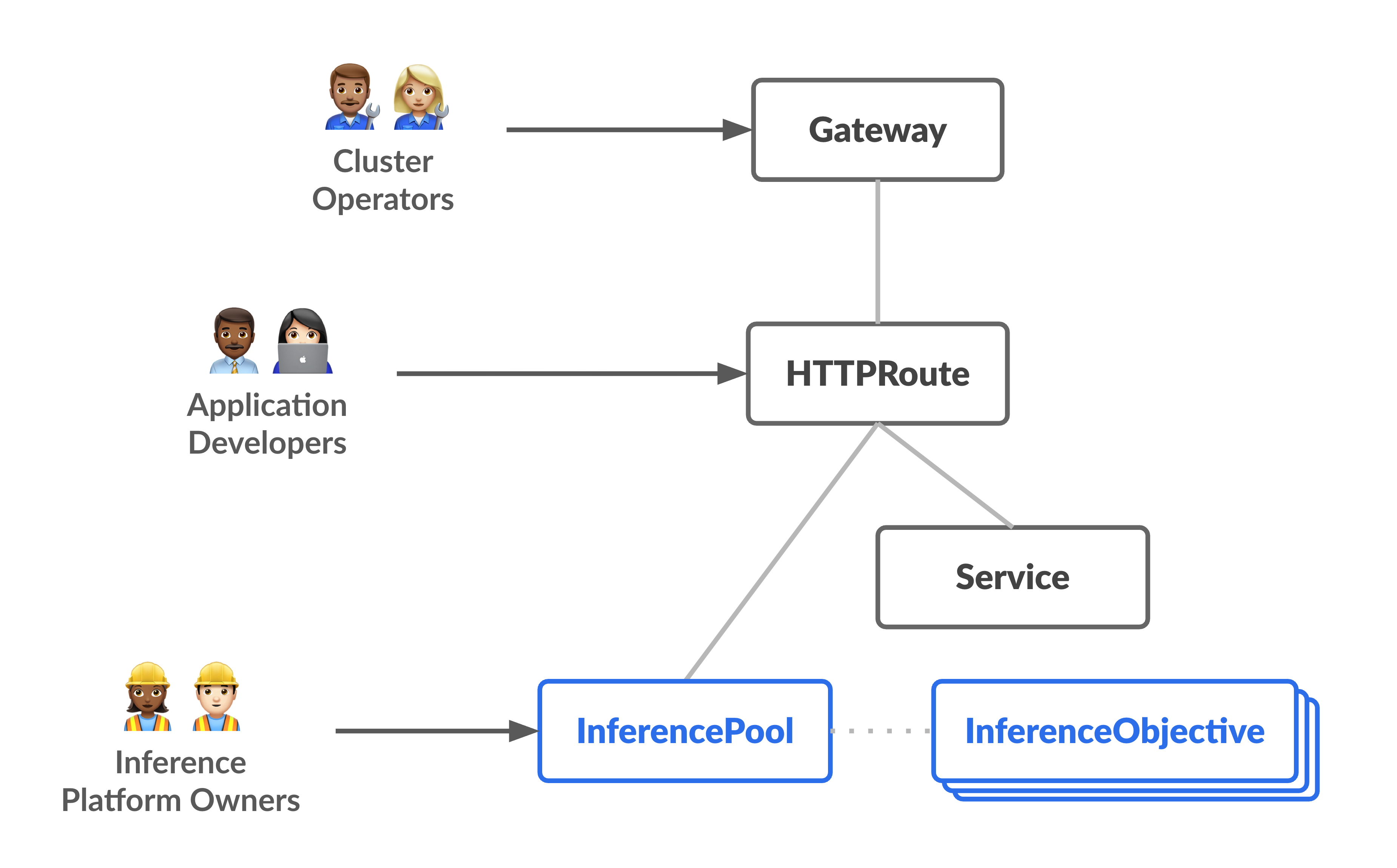
En el siguiente diagrama se muestra el modelo de recursos, que se centra en dos perfiles centrados en la inferencia y en los recursos que gestionan.
Cómo funciona GKE Inference Gateway
GKE Inference Gateway usa extensiones de la API Gateway y lógica de enrutamiento específica del modelo para gestionar las solicitudes de los clientes a un modelo de IA. En los siguientes pasos se describe el flujo de solicitudes.
Cómo funciona el flujo de solicitudes
GKE Inference Gateway enruta las solicitudes de los clientes desde la solicitud inicial a una instancia del modelo. En esta sección se describe cómo gestiona Inference Gateway de GKE las solicitudes. Este flujo de solicitudes es común para todos los clientes.
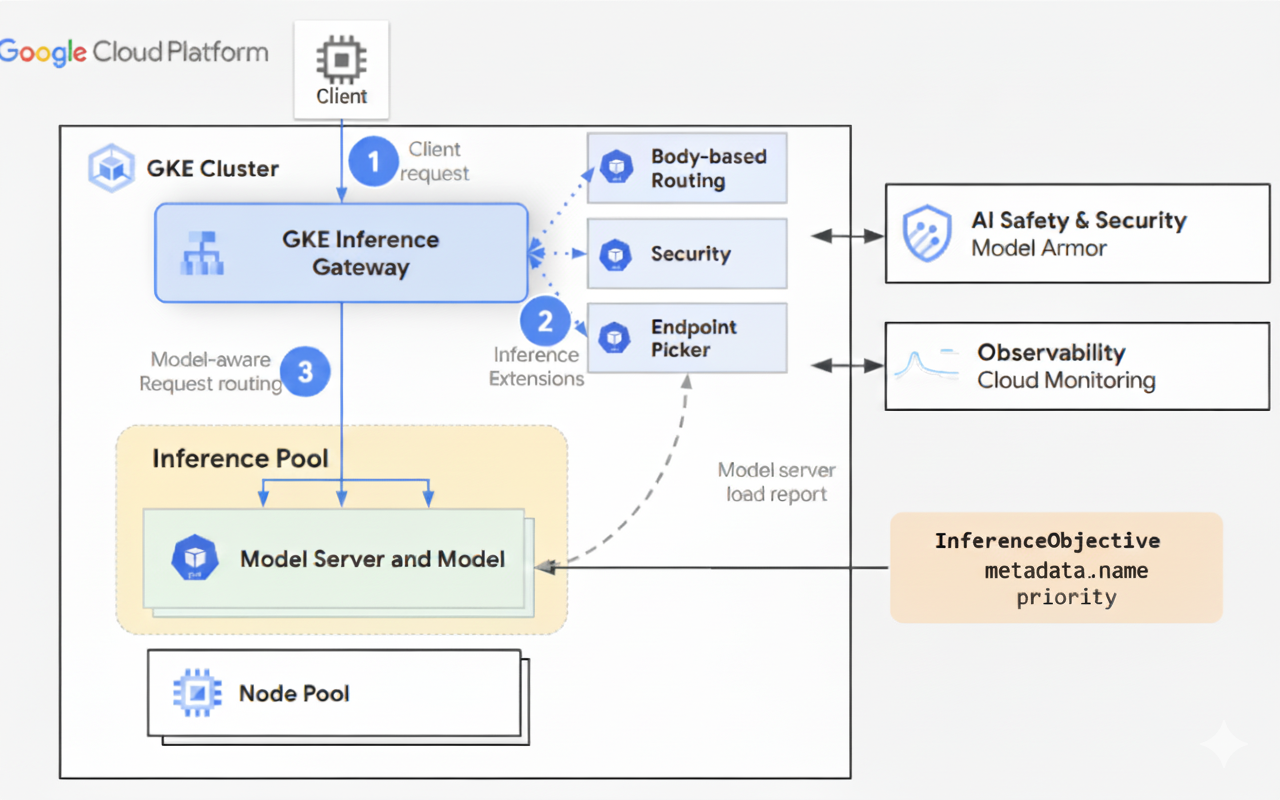
- El cliente envía una solicitud, con el formato descrito en la especificación de la API de OpenAI, al modelo que se ejecuta en GKE.
- GKE Inference Gateway procesa la solicitud mediante las siguientes extensiones de inferencia:
- Extensión de enrutamiento basado en el cuerpo: extrae el identificador del modelo del cuerpo de la solicitud del cliente y lo envía a GKE Inference Gateway.
A continuación, GKE Inference Gateway usa este identificador para enrutar la solicitud según las reglas definidas en el objeto
HTTPRoutede la API Gateway. El enrutamiento del cuerpo de la solicitud es similar al enrutamiento basado en la ruta de la URL. La diferencia es que el enrutamiento del cuerpo de la solicitud usa datos del cuerpo de la solicitud. - Extensión de seguridad: usa Model Armor o soluciones de terceros compatibles para aplicar políticas de seguridad específicas del modelo, como el filtrado de contenido, la detección de amenazas, la higienización y el registro. La extensión de seguridad aplica estas políticas a las rutas de procesamiento de solicitudes y respuestas.
- Extensión de selector de endpoints: monitoriza las métricas clave de los servidores de modelos
en
InferencePool. Monitoriza la utilización de la caché de pares clave-valor, la longitud de la cola de solicitudes pendientes, los índices de la caché de prefijos y los adaptadores LoRA activos en cada servidor de modelos. A continuación, dirige la solicitud a la réplica del modelo óptimo en función de estas métricas para minimizar la latencia y maximizar el rendimiento de la inferencia de IA.
- Extensión de enrutamiento basado en el cuerpo: extrae el identificador del modelo del cuerpo de la solicitud del cliente y lo envía a GKE Inference Gateway.
A continuación, GKE Inference Gateway usa este identificador para enrutar la solicitud según las reglas definidas en el objeto
- GKE Inference Gateway enruta la solicitud a la réplica del modelo devuelta por la extensión del selector de endpoints.
En el siguiente diagrama se ilustra el flujo de solicitudes de un cliente a una instancia de modelo a través de GKE Inference Gateway.
Cómo funciona la distribución del tráfico
GKE Inference Gateway distribuye de forma dinámica las solicitudes de inferencia a los servidores de modelos del objeto InferencePool. Esto ayuda a optimizar el uso de los recursos y a mantener el rendimiento en condiciones de carga variables.
GKE Inference Gateway usa los dos mecanismos siguientes para gestionar la distribución del tráfico:
Selección de endpoints: selecciona de forma dinámica el servidor de modelos más adecuado para gestionar una solicitud de inferencia. Monitoriza la carga y la disponibilidad del servidor y, a continuación, toma las decisiones de enrutamiento óptimas calculando un
scorepara cada servidor. Para ello, combina varias heurísticas de optimización:- Enrutamiento con reconocimiento de caché de prefijos: GKE Inference Gateway monitoriza los índices de caché de prefijos disponibles en cada servidor de modelos y asigna una puntuación más alta a los servidores con una coincidencia de caché de prefijos más larga.
- Enrutamiento con reconocimiento de carga: GKE Inference Gateway monitoriza la carga del servidor (utilización de la caché de valores clave y profundidad de la cola pendiente) y asigna una puntuación más alta a los servidores con menor carga.
- Rutas con LoRA: cuando se habilita el servicio dinámico de LoRA, GKE Inference Gateway monitoriza los adaptadores LoRA activos por servidor y asigna una puntuación más alta a un servidor con el adaptador LoRA solicitado activo o espacio adicional para cargar dinámicamente el adaptador LoRA solicitado. Se elige el servidor con la puntuación total más alta de todos los anteriores.
Poner en cola y descartar: gestiona el flujo de solicitudes y evita la sobrecarga de tráfico. GKE Inference Gateway almacena las solicitudes entrantes en una cola y les asigna prioridad en función de la prioridad definida.
GKE Inference Gateway usa un sistema numérico Priority, también conocido como
Criticality, para gestionar el flujo de solicitudes y evitar la sobrecarga. Este Priority es un campo de número entero opcional que define el usuario para cada InferenceObjective. Un valor más alto significa que la solicitud es más importante. Cuando el sistema está bajo presión, las solicitudes con un Priority inferior a 0 se consideran de menor prioridad y se descartan primero, lo que devuelve un error 429 para proteger las cargas de trabajo más críticas. De forma predeterminada, el Priority es 0. Las solicitudes solo se rechazan por prioridad si su Priority se define explícitamente con un valor inferior a 0. Este sistema te permite priorizar el tráfico de inferencia online sensible a la latencia por encima de las tareas por lotes que no son tan sensibles al tiempo.
GKE Inference Gateway admite la inferencia de streaming para aplicaciones como chatbots y traducción en directo, que requieren actualizaciones continuas o casi en tiempo real. La inferencia de streaming ofrece respuestas en fragmentos o segmentos incrementales, en lugar de una única salida completa. Si se produce un error durante una respuesta de streaming, el flujo se termina y el cliente recibe un mensaje de error. GKE Inference Gateway no vuelve a intentar enviar respuestas de streaming.
Ver ejemplos de aplicaciones
En esta sección se proporcionan ejemplos de cómo usar GKE Inference Gateway para abordar varios casos prácticos de aplicaciones de IA generativa.
Ejemplo 1: Servir varios modelos de IA generativa en un clúster de GKE
Una empresa quiere implementar varios modelos de lenguaje extensos (LLMs) para dar servicio a diferentes cargas de trabajo. Por ejemplo, puede que quieran implementar un modelo Gemma3 para una interfaz de chatbot y un modelo Deepseek para una aplicación de recomendaciones. La empresa debe asegurarse de que el rendimiento de publicación de estos LLMs sea óptimo.
Con GKE Inference Gateway, puedes implementar estos LLMs en tu clúster de GKE con la configuración de acelerador que elijas en un InferencePool. A continuación, puedes enrutar las solicitudes en función del nombre del modelo (como chatbot y recommender) y de la propiedad Priority.
En el siguiente diagrama se muestra cómo GKE Inference Gateway enruta las solicitudes a diferentes modelos en función del nombre del modelo y de Priority.
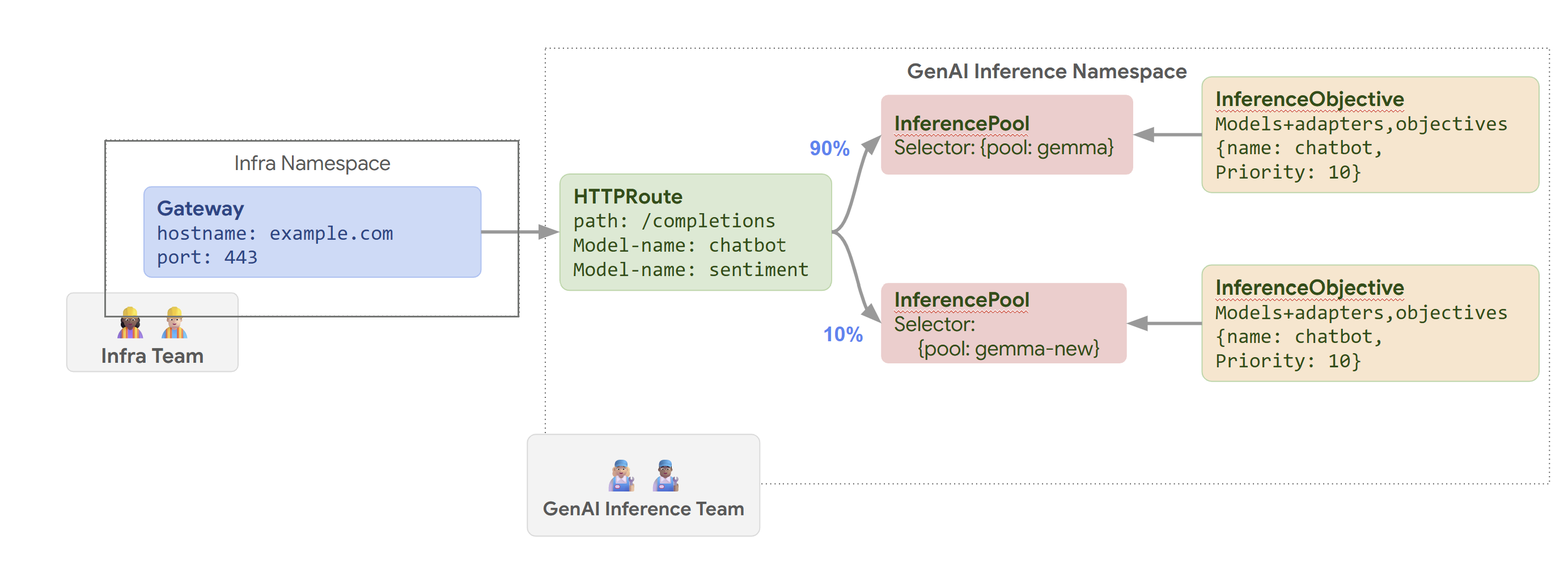
En este diagrama se muestra cómo gestiona GKE Inference Gateway una solicitud a un servicio de IA generativa en example.com/completions. La solicitud
llega primero a un Gateway en el espacio de nombres Infra. Este Gateway reenvía la solicitud a un HTTPRoute en el espacio de nombres GenAI Inference, que está configurado para gestionar las solicitudes de modelos de chatbot y de análisis de sentimientos. En el caso del modelo de chatbot, HTTPRoute divide el tráfico: el 90% se dirige a un InferencePool que ejecuta la versión actual del modelo (seleccionada por {pool: gemma}) y el 10% se dirige a un grupo con una versión más reciente ({pool: gemma-new}), normalmente para pruebas canary.
Ambos grupos están vinculados a un InferenceObjective que asigna un Priority de 10 a las solicitudes del modelo de chatbot, lo que garantiza que estas solicitudes se traten con alta prioridad.
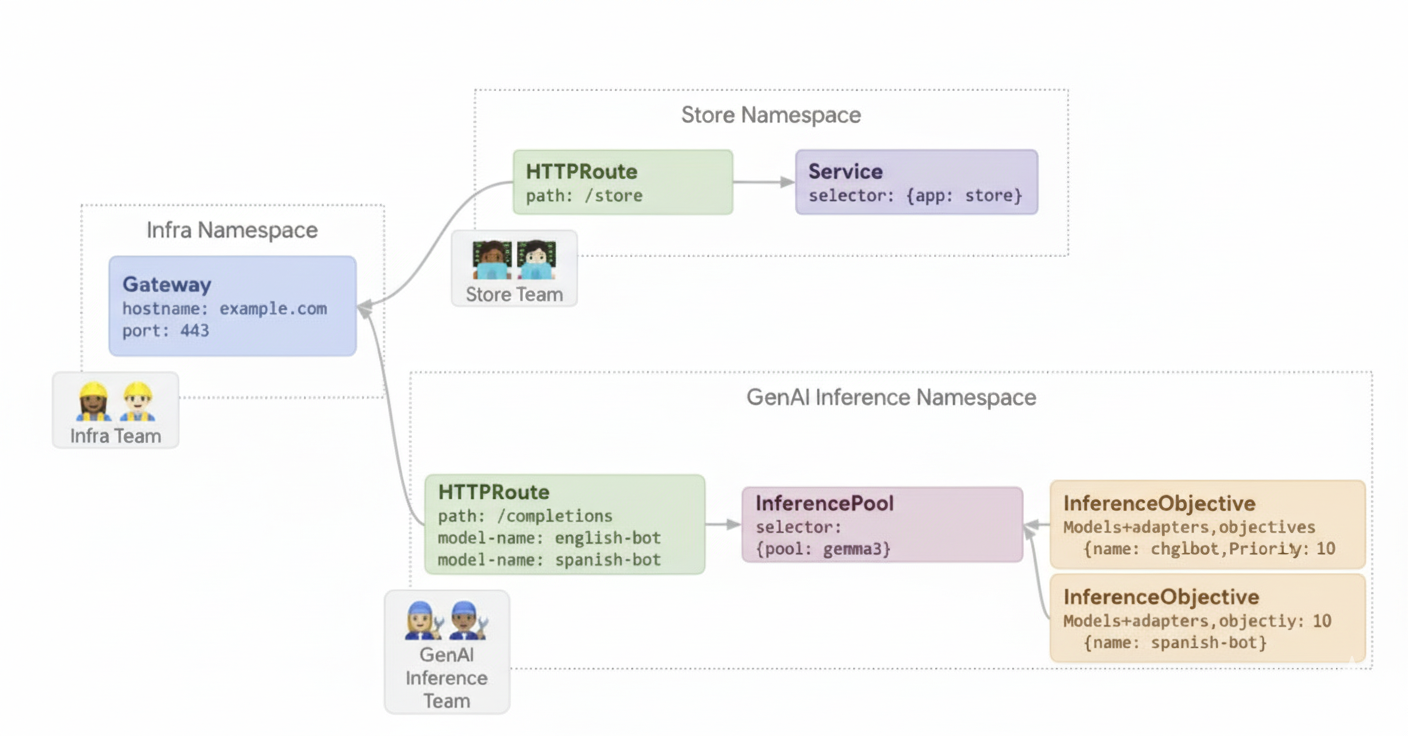
Ejemplo 2: Servir adaptadores LoRA en un acelerador compartido
Una empresa quiere ofrecer LLMs para analizar documentos y se centra en audiencias de varios idiomas, como inglés y español. Han optimizado modelos para cada idioma, pero necesitan usar de forma eficiente su capacidad de GPU y TPU. Puedes usar GKE Inference Gateway para desplegar adaptadores LoRA dinámicos ajustados para cada idioma (por ejemplo, english-bot y spanish-bot) en un modelo base común (por ejemplo, llm-base) y un acelerador. De esta forma, puedes reducir el número de aceleradores necesarios empaquetando densamente varios modelos en un acelerador común.
En el siguiente diagrama se muestra cómo sirve GKE Inference Gateway varios adaptadores LoRA en un acelerador compartido.
Siguientes pasos
- Desplegar GKE Inference Gateway
- Personalizar la configuración de GKE Inference Gateway
- Servir un LLM con GKE Inference Gateway