Teradata
您可以使用 Teradata 連接器,對 Teradata 資料庫執行插入、刪除、更新和讀取作業。
事前準備
使用 Teradata 連接器前,請先完成下列工作:
- 在 Google Cloud 專案中:
- 確認已設定網路連線。如要瞭解網路模式,請參閱「網路連線」。
- 將 roles/connectors.admin IAM 角色授予設定連線器的使用者。
- 將下列 IAM 角色授予要用於連接器的服務帳戶:
roles/secretmanager.viewerroles/secretmanager.secretAccessor
服務帳戶是特殊的 Google 帳戶類型,主要用於代表需要驗證且必須取得授權才能存取 Google API 資料的非人類使用者。如果您沒有服務帳戶,請務必建立服務帳戶。連接器和服務帳戶必須屬於同一個專案。詳情請參閱「建立服務帳戶」。
- 啟用下列服務:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
如要瞭解如何啟用服務,請參閱「啟用服務」。
如果專案先前未啟用這些服務或權限,系統會在設定連結器時提示您啟用。
Teradata 設定
如要在 Google Cloud VM 上建立 Teradata Vantage Express 執行個體,請參閱「在 Google Cloud VM 上安裝 Teradata」。如果這個 VM 公開顯示,建立連線時,這個 VM 的外部 IP 即可做為主機位址。如果 VM 未公開,請建立 Private Service Connectivity,並在建立連線時使用網路端點連結 IP。
設定連接器
連線專屬於資料來源。也就是說,如果您有多個資料來源,則必須為每個資料來源建立個別的連線。如要建立連線,請按照下列步驟操作:
- 在 Cloud 控制台中,前往「Integration Connectors」>「Connections」頁面,然後選取或建立 Google Cloud 專案。
- 按一下「+ 建立新連線」,開啟「建立連線」頁面。
- 在「位置」部分中,選擇連線位置。
- 區域:從下拉式清單中選取位置。
如需所有支援的地區清單,請參閱「位置」一文。
- 點選「下一步」。
- 區域:從下拉式清單中選取位置。
- 在「連線詳細資料」部分,完成下列步驟:
- 連接器:從可用連接器的下拉式清單中選取「Teradata」。
- 連接器版本:從可用版本的下拉式清單中選取連接器版本。
- 在「連線名稱」欄位中,輸入連線執行個體的名稱。
連線名稱必須符合下列條件:
- 連線名稱可使用英文字母、數字或連字號。
- 字母必須為小寫。
- 連線名稱開頭須為英文字母,結尾則須為英文字母或數字。
- 連結名稱不得超過 49 個字元。
- 視需要輸入連線執行個體的「Description」(說明)。
- 或者,可啟用 Cloud Logging,然後選取記錄層級。記錄層級預設為
Error。 - 服務帳戶:選取具備必要角色的服務帳戶。
- 視需要設定「連線節點設定」:
- 節點數量下限:輸入連線節點數量下限。
- 節點數量上限:輸入連線節點數量上限。
節點是用來處理交易的連線單位 (或備用資源)。連線處理的交易量越多,就需要越多節點;反之,處理的交易量越少,需要的節點就越少。如要瞭解節點對連線器定價的影響,請參閱「 連線節點定價」。如未輸入任何值,系統預設會將節點下限設為 2 (提高可用性),節點上限則設為 50。
- 資料庫:開啟 Teradata 連線時選取的預設資料庫。
- 字元集:指定工作階段字元集,用於編碼及解碼傳輸至 Teradata 資料庫和從 Teradata 資料庫傳輸的字元資料。預設值為 ASCII。
- (選用) 按一下「+ 新增標籤」,以鍵/值組合的形式為連線新增標籤。
- 點選「下一步」。
- 在「目的地」部分,輸入要連線的遠端主機 (後端系統) 詳細資料。
- 目的地類型:選取目的地類型。
- 如要指定目的地主機名稱或 IP 位址,請選取「主機地址」,然後在「主機 1」欄位中輸入地址。
- 如要建立私人連線,請選取「Endpoint attachment」(端點連結),然後從「Endpoint Attachment」(端點連結) 清單中選擇所需連結。
如要建立與後端系統的公開連線,並加強安全性,建議為連線設定靜態輸出 IP 位址,然後設定防火牆規則,只允許特定靜態 IP 位址。
如要輸入其他目的地,請按一下「+新增目的地」。
- 點選「下一步」。
- 目的地類型:選取目的地類型。
-
在「Authentication」(驗證) 部分,輸入驗證詳細資料。
- 選取「驗證類型」並輸入相關詳細資料。
Teradata 連線支援下列驗證類型:
- 使用者名稱和密碼
- 點選「下一步」。
如要瞭解如何設定這些驗證類型,請參閱「設定驗證」。
- 選取「驗證類型」並輸入相關詳細資料。
- 檢查:檢查連線和驗證詳細資料。
- 點選「建立」。
設定驗證機制
根據要使用的驗證方式輸入詳細資料。
-
使用者名稱和密碼
- 使用者名稱:連接器的使用者名稱
- 密碼:Secret Manager 密鑰,內含與連接器相關聯的密碼。
連線設定範例
本節提供您建立 Teradata 連接器時設定的各個欄位範例值。
基本驗證 - 連線類型
| 欄位名稱 | 詳細資料 |
|---|---|
| 位置 | us-central1 |
| 連接器 | teradata |
| 連接器版本 | 1 |
| 連線名稱 | teradata-vm-connection |
| 啟用 Cloud Logging | 是 |
| 服務帳戶 | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| 資料庫 | TERADATA_TESTDB |
| 字元集 | ASCII |
| 節點數量下限 | 2 |
| 節點數量上限 | 2 |
| 目的地類型 | 主機位址 |
| 主機 1 | 203.0.113.255 |
| 通訊埠 1 | 1025 |
| 使用者名稱 | 使用者名稱 |
| 密碼 | 密碼 |
| 密鑰版本 | 1 |
實體、作業和動作
所有整合連接器都會為所連應用程式的物件提供抽象層。您只能透過這個抽象化程序存取應用程式的物件。抽象化會以實體、作業和動作的形式呈現。
- 實體: 實體可以視為已連結應用程式或服務中的物件,或是屬性集合。實體的定義因連接器而異。舉例來說,在資料庫連接器中,資料表是實體;在檔案伺服器連接器中,資料夾是實體;在訊息系統連接器中,佇列是實體。
不過,連接器可能不支援或沒有任何實體,在這種情況下,
Entities清單會是空白。 - 作業: 作業是指您可以在實體上執行的活動。您可以對實體執行下列任一操作:
從可用清單中選取實體,系統會產生該實體可用的作業清單。如需作業的詳細說明,請參閱 Connectors 工作的實體作業。 不過,如果連接器不支援任何實體作業,系統就不會在
Operations清單中列出這些不支援的作業。 - 動作: 動作是透過連接器介面提供給整合的第一類函式。動作可讓您變更一或多個實體,且因連接器而異。一般來說,動作會有一些輸入參數和輸出參數。不過,連接器可能不支援任何動作,此時
Actions清單會是空白。
動作
這個連結器支援執行下列動作:
- 使用者定義的預存程序和函式。如果後端有任何預存程序和函式,這些項目會列在
Configure connector task對話方塊的Actions欄中。 - 自訂 SQL 查詢。如要執行自訂 SQL 查詢,連接器提供「執行自訂查詢」動作。
如要建立自訂查詢,請按照下列步驟操作:
- 請按照詳細說明 新增連接器工作。
- 設定連接器工作時,請在要執行的動作類型中選取「動作」。
- 在「動作」清單中,選取「執行自訂查詢」,然後按一下「完成」。
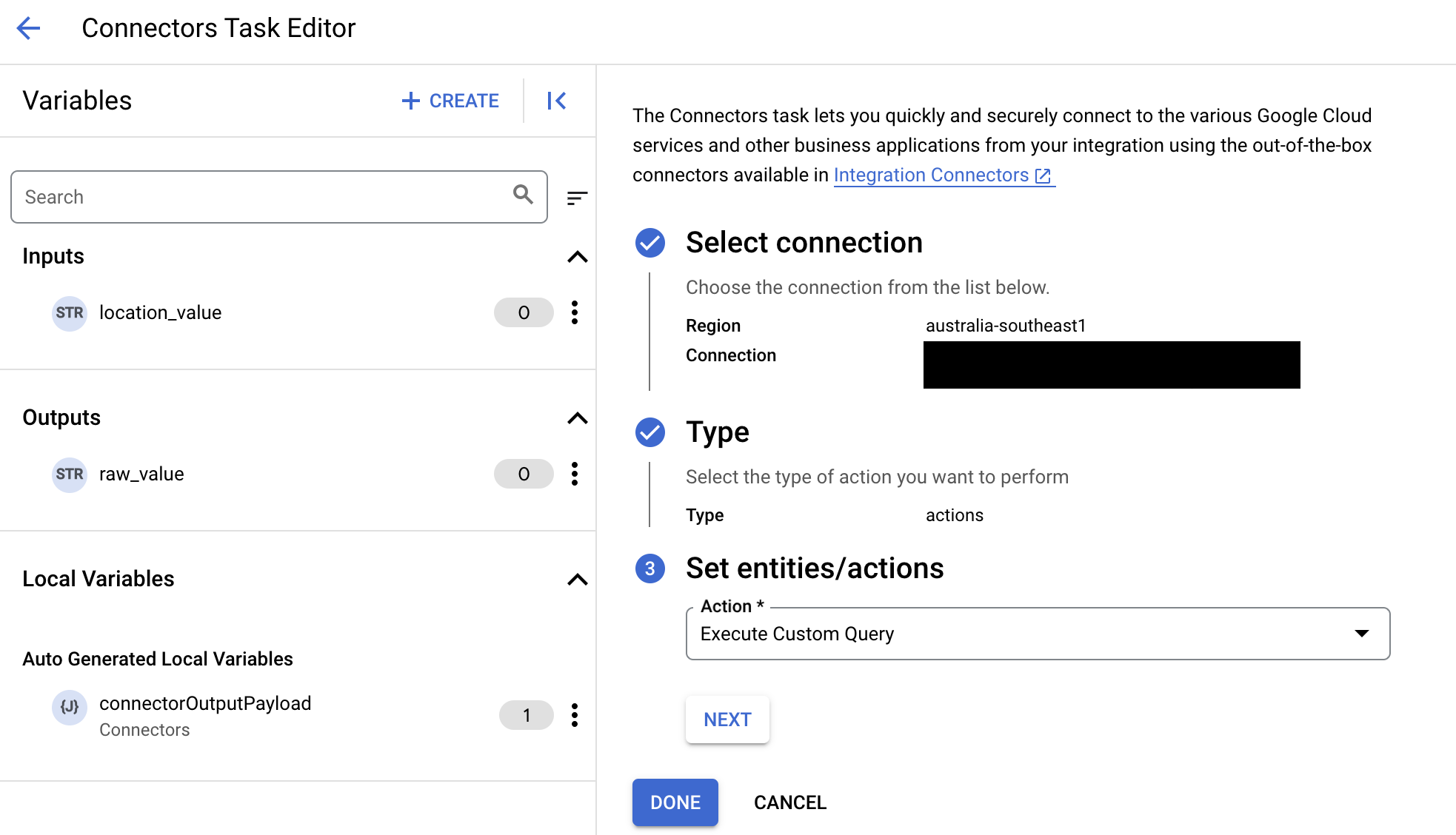
- 展開「Task input」(工作輸入) 區段,然後執行下列操作:
- 在「Timeout after」(逾時時間) 欄位中,輸入查詢執行前的等待秒數。
預設值:
180秒。 - 在「資料列數量上限」欄位中,輸入要從資料庫傳回的資料列數量上限。
預設值為
25。 - 如要更新自訂查詢,請按一下「編輯自訂指令碼」。「指令碼編輯器」對話方塊隨即開啟。
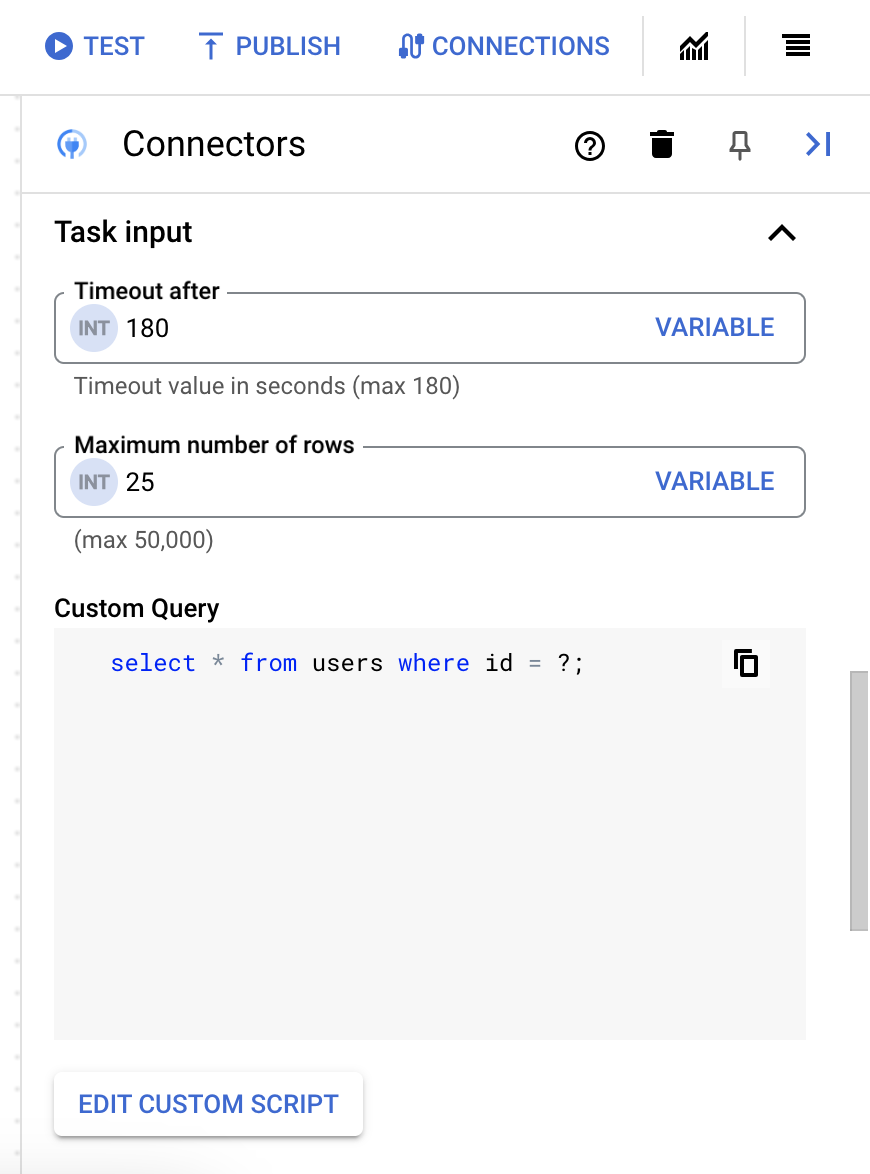
- 在「指令碼編輯器」對話方塊中輸入 SQL 查詢,然後按一下「儲存」。
您可以在 SQL 陳述式中使用問號 (?) 代表單一參數,該參數必須在查詢參數清單中指定。舉例來說,下列 SQL 查詢會從
Employees資料表選取與LastName資料欄指定值相符的所有資料列:SELECT * FROM Employees where LastName=?
- 如果您在 SQL 查詢中使用問號,請為每個問號點按「+ 新增參數名稱」,加入參數。執行整合時,這些參數會依序取代 SQL 查詢中的問號 (?)。舉例來說,如果您新增了三個問號 (?),就必須依序新增三個參數。
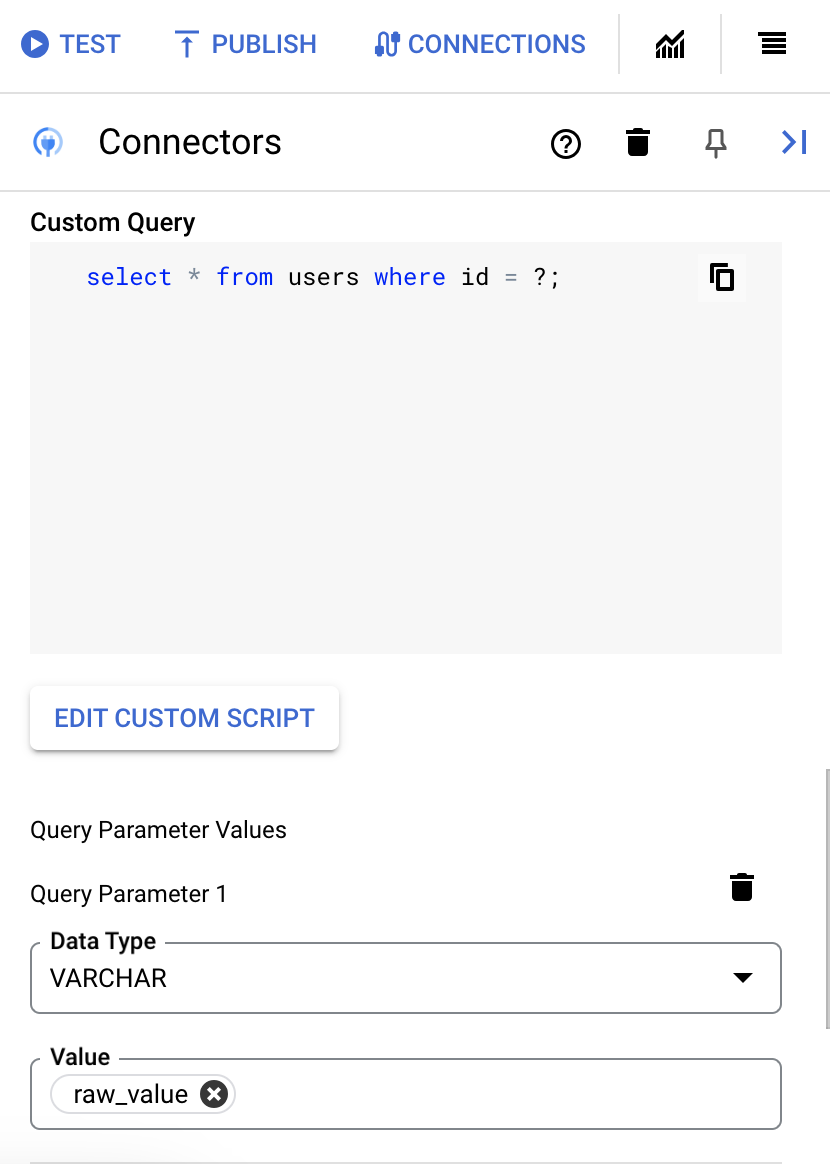
如要新增查詢參數,請按照下列步驟操作:
- 在「類型」清單中,選取參數的資料類型。
- 在「值」欄位中輸入參數值。
- 如要新增多個參數,請按一下「+ 新增查詢參數」。
「執行自訂查詢」動作不支援陣列變數。
- 在「Timeout after」(逾時時間) 欄位中,輸入查詢執行前的等待秒數。
系統限制
每個節點的 Teradata 連接器每秒最多可處理 70 筆交易,並節流任何超出此限制的交易。根據預設,Integration Connectors 會為連線分配 2 個節點 (提高可用性)。
如要瞭解 Integration Connectors 適用的限制,請參閱「限制」一文。
支援的資料類型
這個連接器支援的資料類型如下:
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- 時間
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
動作
Oracle DB 連接器可讓您以 Oracle 資料庫支援的格式,執行預存程序、函式和自訂 SQL 查詢。如要執行自訂 SQL 查詢,連接器提供 ExecuteCustomQuery 動作。
ExecuteCustomQuery 動作
這項動作可讓您執行自訂 SQL 查詢。
ExecuteCustomQuery 動作的輸入參數
| 參數名稱 | 資料類型 | 必填 | 說明 |
|---|---|---|---|
| 查詢 | 字串 | 是 | 要執行的查詢。 |
| queryParameters | JSON 陣列,格式如下:[{"value": "VALUE", "dataType": "DATA_TYPE"}]
|
否 | 查詢參數。 |
| maxRows | 數字 | 否 | 要傳回的列數上限。 |
| 逾時 | 數字 | 否 | 等待查詢執行的秒數。 |
ExecuteCustomQuery 動作的輸出參數
執行成功後,這項動作會傳回狀態 200 (OK),以及含有查詢結果的回應內容。
如要瞭解如何設定 ExecuteCustomQuery 動作,請參閱範例。
如要瞭解如何使用 ExecuteCustomQuery 動作,請參閱動作範例。
動作範例
本節說明如何在這個連接器中執行部分動作。
範例 - 執行 group by 查詢
- 在「
Configure connector task」對話方塊中,按一下Actions。 - 選取
ExecuteCustomQuery動作,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "query": "select E.EMPLOYEE_ID,E.EMPLOYEE_NAME,E.CITY from EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID where E.EMPLOYEE_NAME = 'John' Group by E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME" }
這個範例會從 EMPLOYEES 和 EMPLOYEE_DEPARTMENT 資料表選取員工記錄。如果動作成功,連接器工作的 connectorOutputPayload 回應參數會包含查詢結果集。
範例 - 執行參數化查詢
- 在「
Configure connector task」對話方塊中,按一下Actions。 - 選取
ExecuteCustomQuery動作,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "query": "select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID from customqueries C,Employees E where C.ID=E.Employee_id and C.NAME=?", "queryParameters": [{ "value": "John", "dataType": "VARCHAR" }], "timeout":10, "maxRows":3 }
這個範例會選取員工姓名為 John 的員工記錄。
請注意,員工姓名是使用 queryParameters 參數進行參數化。
如果動作成功,連接器工作 connectorOutputPayload 回應參數的值會類似以下內容:
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
範例 - 使用序號值插入記錄
- 在「
Configure connector task」對話方塊中,按一下Actions。 - 選取
ExecuteCustomQuery動作,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "query": "INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')" }
這個範例會使用現有的 author_table_id_seq 序列物件,在 AUTHOR 資料表中插入記錄。如果動作成功,連接器工作 connectorOutputPayload 回應參數的值會類似以下內容:
[{ }]
範例 - 使用匯總函式執行查詢
- 在「
Configure connector task」對話方塊中,按一下Actions。 - 選取
ExecuteCustomQuery動作,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "query": "SELECT SUM(SALARY) as Total FROM EMPLOYEES" }
這個範例會計算 EMPLOYEES 資料表中的薪資總值。如果動作成功,連接器工作 connectorOutputPayload 回應參數的值會類似以下內容:
[{ "TOTAL": 13000.0 }]
範例 - 建立新資料表
- 在「
Configure connector task」對話方塊中,按一下Actions。 - 選取
ExecuteCustomQuery動作,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "query": "CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))" }
這個範例會建立 TEST1 資料表。如果動作成功,連接器工作 connectorOutputPayload 回應參數的值會類似以下內容:
[{ }]
實體作業範例
範例 - 列出所有員工
這個範例會列出 Employee 實體中的所有員工。
- 在「
Configure connector task」對話方塊中,按一下Entities。 - 從
Entity清單中選取Employee。 - 選取「
List」作業,然後按一下「完成」。 - (選用) 在「連結器」工作中的「工作輸入」部分,您可以指定篩選子句,篩選結果集。
範例 - 取得員工詳細資料
這個範例會從 Employee 實體取得具有指定 ID 的員工詳細資料。
- 在「
Configure connector task」對話方塊中,按一下Entities。 - 從
Entity清單中選取Employee。 - 選取「
Get」作業,然後按一下「完成」。 - 在「連線器」工作的「工作輸入」部分,按一下「EntityId」,然後在「預設值」欄位中輸入
45。其中
45是Employee實體的主鍵值。
範例 - 建立員工記錄
這個範例會在 Employee 實體中新增員工記錄。
- 在「
Configure connector task」對話方塊中,按一下Entities。 - 從
Entity清單中選取Employee。 - 選取「
Create」作業,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
如果整合成功,連接器工作的
connectorOutputPayload欄位會顯示類似下列的值:{ "ROWID": "AAAoU0AABAAAc3hAAF" }
範例 - 更新員工記錄
這個範例會更新 Employee 實體中 ID 為 69 的員工記錄。
- 在「
Configure connector task」對話方塊中,按一下Entities。 - 從
Entity清單中選取Employee。 - 選取「
Update」作業,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下
connectorInputPayload,然後在Default Value欄位中輸入類似下列的值:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- 按一下「entityId」,然後在「Default Value」欄位中輸入
69。或者,您也可以將 filterClause 設為
69,而非指定 entityId。如果整合成功,連接器工作的
connectorOutputPayload欄位會包含類似下列內容的值:{ }
範例 - 刪除員工記錄
這個範例會刪除 Employee 實體中具有指定 ID 的員工記錄。
- 在「
Configure connector task」對話方塊中,按一下Entities。 - 從
Entity清單中選取Employee。 - 選取「
Delete」作業,然後按一下「完成」。 - 在「Connectors」(連結器) 任務的「Task Input」(任務輸入內容) 區段中,按一下「entityId」,然後在「Default Value」(預設值) 欄位中輸入
35。
使用 Terraform 建立連線
您可以使用 Terraform 資源建立新連線。
如要瞭解如何套用或移除 Terraform 設定,請參閱「基本 Terraform 指令」。
如要查看用於建立連線的 Terraform 範本範例,請參閱範本範例。
使用 Terraform 建立這項連線時,您必須在 Terraform 設定檔中設定下列變數:
| 參數名稱 | 資料類型 | 必填 | 說明 |
|---|---|---|---|
| client_charset | STRING | 是 | 指定用於編碼及解碼傳輸至 Teradata 資料庫和從該資料庫傳輸的字元資料的 Java 字元集。 |
| 資料庫 | STRING | 是 | 開啟 Teradata 連線時選取的預設資料庫。 |
| 帳戶 | STRING | 否 | 指定帳戶字串,以覆寫為 Teradata 資料庫使用者定義的預設帳戶字串。 |
| 字元集 | STRING | 是 | 指定用於編碼及解碼傳輸至 Teradata 資料庫和從 Teradata 資料庫傳輸的字元資料的連線字元集。預設值為 ASCII。 |
| column_name | INTEGER | 是 | 控管 ResultSetMetaData getColumnName 和 getColumnLabel 方法的行為。 |
| connect_failure_ttl | STRING | 否 | 這個選項可讓 CData ADO.NET Provider for Teradata 記住每個 IP 位址/通訊埠組合上次連線失敗的時間。此外,在後續登入期間,CData ADO.NET Provider for Teradata 會略過該 IP 位址/連接埠的連線嘗試,略過時間長度由連線失敗存留時間 (CONNECTFAILURETTL) 值指定。 |
| connect_function | STRING | 否 | 指定 Teradata 資料庫是否應為這個工作階段分配登入序號 (LSN),或將這個工作階段與現有 LSN 建立關聯。 |
| cop | STRING | 否 | 指定是否要執行 COP 探索。 |
| cop_last | STRING | 否 | 指定 COP Discovery 如何判斷最後一個 COP 主機名稱。 |
| ddstats | ENUM | 否 | 指定 DDSTATS 的值。支援的值為 ON 和 OFF |
| disable_auto_commit_in_batch | BOOLEAN | 是 | 指定執行批次作業時是否要停用自動提交。 |
| encrypt_data | ENUM | 否 | 指定 EncryptData 值,ON 或 OFF。支援的值為:ON、OFF |
| error_query_count | STRING | 否 | 指定 JDBC FastLoad 作業後,JDBC FastLoad 嘗試查詢 FastLoad 錯誤表 1 的次數上限。 |
| error_query_interval | STRING | 否 | 指定 JDBC FastLoad 在 JDBC FastLoad 作業後,嘗試查詢 FastLoad 錯誤表 1 之間的等待毫秒數。 |
| error_table1_suffix | STRING | 否 | 指定 JDBC FastLoad 和 JDBC FastLoad CSV 建立的 FastLoad 錯誤資料表 1 名稱的後置字元。 |
| error_table2_suffix | STRING | 否 | 指定 JDBC FastLoad 和 JDBC FastLoad CSV 建立的 FastLoad 錯誤資料表 2 名稱的後置字串。 |
| error_table_database | STRING | 否 | 指定 JDBC FastLoad 和 JDBC FastLoad CSV 建立的 FastLoad 錯誤資料表資料庫名稱。 |
| field_sep | STRING | 否 | 指定要與 JDBC FastLoad CSV 搭配使用的欄位分隔符。預設分隔符號為「,」(半形逗號)。 |
| finalize_auto_close | STRING | 否 | 指定 FinalizeAutoClose 的值,ON 或 OFF。 |
| geturl_credentials | STRING | 否 | 指定 GeturlCredentials 的值,ON 或 OFF。 |
| 管理 | STRING | 否 | 指定 GOVERN、ON 或 OFF 的值。 |
| literal_underscore | STRING | 否 | 在 DatabaseMetaData 呼叫中,自動逸出 LIKE 述詞模式,例如 schemPattern 和 tableNamePattern。 |
| lob_support | STRING | 否 | 指定 LobSupport 的值 (ON 或 OFF)。 |
| lob_temp_table | STRING | 否 | 指定資料表的名稱,其中包含下列資料欄:id integer、bval blob、cval clob。 |
| log | STRING | 否 | 指定連線的記錄層級 (詳細程度)。記錄功能一律會啟用。記錄層級會依簡略到詳細的順序排列。 |
| log_data | STRING | 否 | 指定登入機制所需的額外資料,例如安全權杖、識別名稱或網域/領域名稱。 |
| log_mech | STRING | 否 | 指定登入機制,決定連線的驗證和加密功能。 |
| logon_sequence_number | STRING | 否 | 指定要與這個工作階段建立關聯的現有登入序號 (LSN)。 |
| max_message_body | STRING | 否 | 指定回應訊息的大小上限 (以位元組為單位)。 |
| maybe_null | STRING | 否 | 控制 ResultSetMetaData.isNullable 方法的行為。 |
| new_password | STRING | 否 | 應用程式可透過這個連線參數自動變更過期密碼。 |
| 分區 | STRING | 否 | 指定連線的 Teradata 資料庫分割區。 |
| prep_support | STRING | 否 | 指定建立 PreparedStatement 或 CallableStatement 時,Teradata 資料庫是否執行準備作業。 |
| reconnect_count | STRING | 否 | 啟用 Teradata 工作階段重新連線。指定 Teradata JDBC 驅動程式嘗試重新連線至工作階段的次數上限。 |
| reconnect_interval | STRING | 否 | 啟用 Teradata 工作階段重新連線。指定 Teradata JDBC 驅動程式在嘗試重新連線至工作階段時,每次嘗試之間等待的秒數。 |
| redrive | STRING | 否 | 啟用 Teradata 工作階段重新連線,並自動重新驅動因資料庫重新啟動而中斷的 SQL 要求。 |
| run_startup | STRING | 否 | 指定 RunStartup 的值,ON 或 OFF。 |
| 工作階段 | STRING | 否 | 指定要建立的 FastLoad 或 FastExport 連線數量,其中 1 <= FastLoad 或 FastExport 連線數量 <= AMP 數量。 |
| sip_support | STRING | 否 | 控制 Teradata 資料庫和 Teradata JDBC 驅動程式是否使用 StatementInfo Parcel (SIP) 傳達中繼資料。 |
| slob_receive_threshold | STRING | 否 | 控制從 Teradata 資料庫接收的 LOB 值大小。應用程式從 Blob/Clob 物件明確讀取資料前,會先從 Teradata 資料庫預先擷取小型 LOB 值。 |
| slob_transmit_threshold | STRING | 否 | 控管如何將小型 LOB 值傳輸至 Teradata 資料庫。 |
| sp_spl | STRING | 否 | 指定建立或取代 Teradata 預存程序的行為。 |
| strict_encode | STRING | 否 | 指定將字元資料編碼並傳輸至 Teradata 資料庫的行為。 |
| tmode | STRING | 否 | 指定連線的交易模式。 |
| tnano | STRING | 否 | 指定繫結至 PreparedStatement 或 CallableStatement,並以 TIME 或 TIME WITH TIME ZONE 值傳輸至 Teradata 資料庫的所有 java.sql.Time 值的秒數精確度。 |
| tsnano | STRING | 否 | 指定繫結至 PreparedStatement 或 CallableStatement,並以 TIMESTAMP 或 TIMESTAMP WITH TIME ZONE 值傳輸至 Teradata 資料庫的所有 java.sql.Timestamp 值的秒數精確度。 |
| tcp | STRING | 否 | 指定一或多個 TCP 通訊端設定,並以加號 () 分隔。 |
| trusted_sql | STRING | 否 | 指定 TrustedSql 的值。 |
| 類型 | STRING | 否 | 指定要搭配 Teradata 資料庫使用的通訊協定類型,以執行 SQL 陳述式。 |
| upper_case_identifiers | BOOLEAN | 否 | 這項屬性會以大寫形式回報所有 ID。這是 Oracle 資料庫的預設值,因此可與 Oracle Database Gateway 等 Oracle 工具更妥善地整合。 |
| use_xviews | STRING | 否 | 指定應查詢哪些資料字典檢視區塊,才能從 DatabaseMetaData 方法傳回結果集。 |
在整合中建立 Teradata 連線
建立連線後,Apigee Integration 和 Application Integration 都會提供該連線。您可以在整合中透過「連接器」工作使用連線。
- 如要瞭解如何在 Apigee Integration 中建立及使用「連線器」工作,請參閱「連線器工作」。
- 如要瞭解如何在 Application Integration 中建立及使用「連線器」工作,請參閱「連線器工作」。