Teradata
The Teradata connector lets you perform insert, delete, update, and read operations on Teradata database.
Before you begin
Before using the Teradata connector, do the following tasks:
- In your Google Cloud project:
- Ensure that network connectivity is set up. For information about network patterns, see Network connectivity.
- Grant the roles/connectors.admin IAM role to the user configuring the connector.
- Grant the following IAM roles to the service account that you want to use for the connector:
roles/secretmanager.viewerroles/secretmanager.secretAccessor
A service account is a special type of Google account intended to represent a non-human user that needs to authenticate and be authorized to access data in Google APIs. If you don't have a service account, you must create a service account. The connector and the service account must belong to the same project. For more information, see Creating a service account.
- Enable the following services:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
To understand how to enable services, see Enabling services.
If these services or permissions have not been enabled for your project previously, you are prompted to enable them when configuring the connector.
Teradata configuration
To create a Teradata Vantage Express instance on Google Cloud VM, see Install Teradata on Google Cloud VM. If this VM is publicly exposed, then the external IP of this VM can be used as the host address when you create a connection. If the VM isn't publicly exposed, create Private Service Connectivity and use the network endpoint attachment IP when you create a connection.
Configure the connector
A connection is specific to a data source. It means that if you have many data sources, you must create a separate connection for each data source. To create a connection, do the following:
- In the Cloud console, go to the Integration Connectors > Connections page and then select or create a Google Cloud project.
- Click + Create new to open the Create Connection page.
- In the Location section, choose the location for the connection.
- Region: Select a location from the drop-down list.
For the list of all the supported regions, see Locations.
- Click Next.
- Region: Select a location from the drop-down list.
- In the Connection Details section, complete the following:
- Connector: Select Teradata from the drop down list of available Connectors.
- Connector version: Select the Connector version from the drop down list of available versions.
- In the Connection Name field, enter a name for the Connection instance.
Connection names must meet the following criteria:
- Connection names can use letters, numbers, or hyphens.
- Letters must be lower-case.
- Connection names must begin with a letter and end with a letter or number.
- Connection names cannot exceed 49 characters.
- Optionally, enter a Description for the connection instance.
- Optionally, enable Cloud logging,
and then select a log level. By default, the log level is set to
Error. - Service Account: Select a service account that has the required roles.
- Optionally, configure the Connection node settings:
- Minimum number of nodes: Enter the minimum number of connection nodes.
- Maximum number of nodes: Enter the maximum number of connection nodes.
A node is a unit (or replica) of a connection that processes transactions. More nodes are required to process more transactions for a connection and conversely, fewer nodes are required to process fewer transactions. To understand how the nodes affect your connector pricing, see Pricing for connection nodes. If you don't enter any values, by default the minimum nodes are set to 2 (for better availability) and the maximum nodes are set to 50.
- Database: The database selected as the default database when a Teradata connection is opened.
- Charset: Specifies the session character set for encoding and decoding character data transferred to and from the Teradata Database. The default value is ASCII.
- Optionally, click + Add label to add a label to the Connection in the form of a key/value pair.
- Click Next.
- In the Destinations section, enter details of the remote host (backend system) you want to connect to.
- Destination Type: Select a Destination Type.
- To specify the destination hostname or IP address, select Host address and enter the address in the Host 1 field.
- To establish a private connection, select Endpoint attachment and choose the required attachment from the Endpoint Attachment list.
If you want to establish a public connection to your backend systems with additional security, you can consider configuring static outbound IP addresses for your connections, and then configure your firewall rules to allowlist only the specific static IP addresses.
To enter additional destinations, click +Add destination.
- Click Next.
- Destination Type: Select a Destination Type.
-
In the Authentication section, enter the authentication details.
- Select an Authentication type and enter the relevant details.
The following authentication types are supported by the Teradata connection:
- Username and password
- Click Next.
To understand how to configure these authentication types, see Configure authentication.
- Select an Authentication type and enter the relevant details.
- Review: Review your connection and authentication details.
- Click Create.
Configure authentication
Enter the details based on the authentication you want to use.
-
Username and password
- Username: Username for connector
- Password: Secret Manager Secret containing the password associated with the connector.
Connection configuration samples
This section provides the sample values for the various fields that you configure when you create a Teradata connector.
Basic authentication - connection type
| Field name | Details |
|---|---|
| Location | us-central1 |
| Connector | teradata |
| Connector version | 1 |
| Connection Name | teradata-vm-connection |
| Enable Cloud Logging | Yes |
| Service Account | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| Database | TERADATA_TESTDB |
| Charset | ASCII |
| Minimum number of nodes | 2 |
| Maximum number of nodes | 2 |
| Destination Type | Host address |
| host 1 | 203.0.113.255 |
| port 1 | 1025 |
| Username | USERNAME |
| Password | PASSWORD |
| Secret version | 1 |
Entities, operations, and actions
All the Integration Connectors provide a layer of abstraction for the objects of the connected application. You can access an application's objects only through this abstraction. The abstraction is exposed to you as entities, operations, and actions.
- Entity: An entity can be thought of as an object, or a collection of properties, in the
connected application or service. The definition of an entity differs from a connector to a
connector. For example, in a database connector, tables are the entities, in a
file server connector, folders are the entities, and in a messaging system connector,
queues are the entities.
However, it is possible that a connector doesn't support or have any entities, in which case the
Entitieslist will be empty. - Operation: An operation is the activity that you can perform on an entity. You can perform
any of the following operations on an entity:
Selecting an entity from the available list, generates a list of operations available for the entity. For a detailed description of the operations, see the Connectors task's entity operations. However, if a connector doesn't support any of the entity operations, such unsupported operations aren't listed in the
Operationslist. - Action: An action is a first class function that is made available to the integration
through the connector interface. An action lets you make changes to an entity or entities, and
vary from connector to connector. Normally, an action will have some input parameters, and an output
parameter. However, it is possible
that a connector doesn't support any action, in which case the
Actionslist will be empty.
Actions
This connector supports execution of the following actions:
- User-defined stored procedures and functions. If you have any stored procedures and functions in your backend, those are listed
in the
Actionscolumn of theConfigure connector taskdialog. - Custom SQL queries. To execute custom SQL queries, the connector provides the Execute custom query action.
To create a custom query, follow these steps:
- Follow the detailed instructions to add a connectors task.
- When you configure the connector task, in the type of action you want to perform, select Actions.
- In the Action list, select Execute custom query, and then click Done.
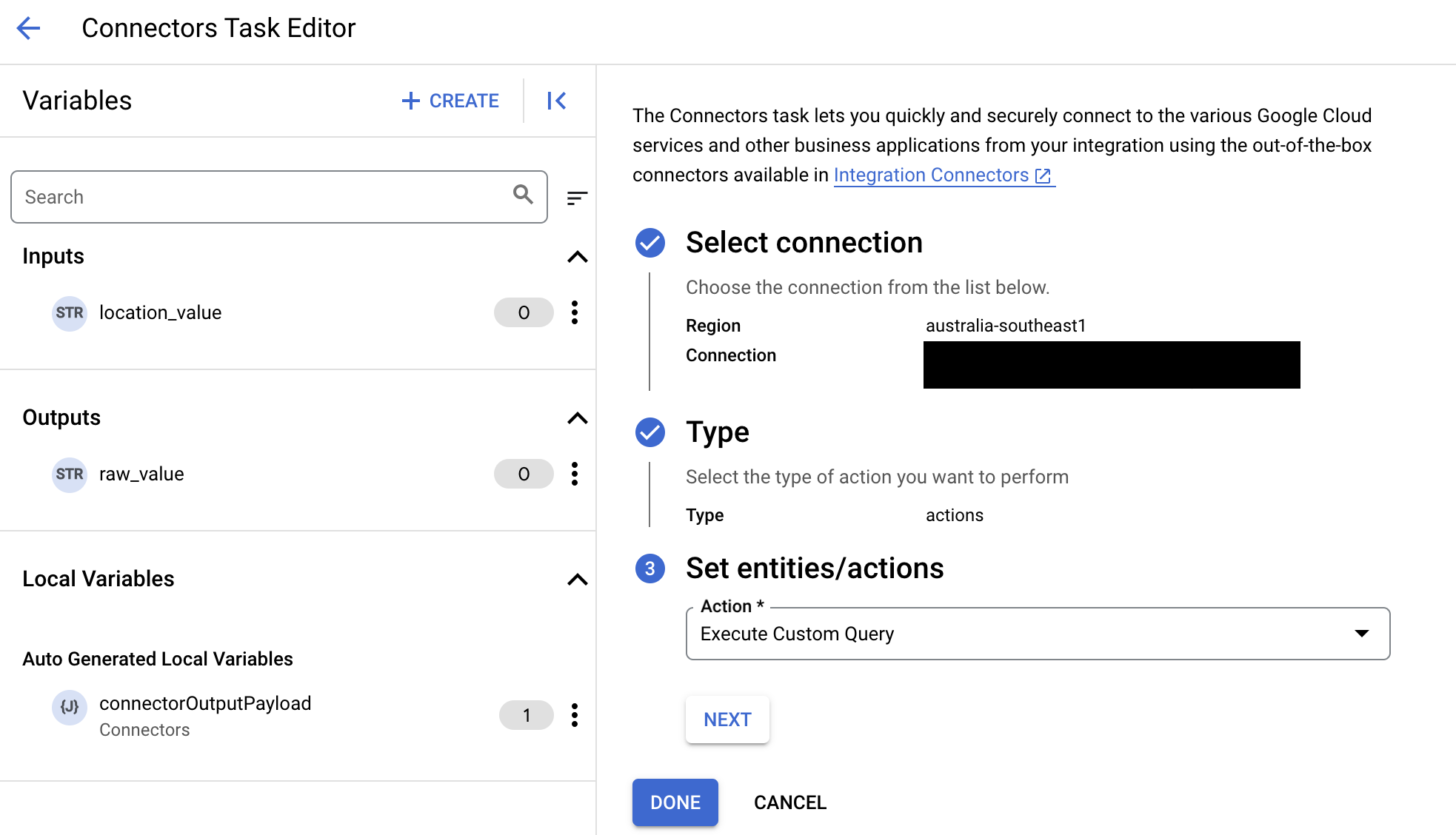
- Expand the Task input section, and then do the following:
- In the Timeout after field, enter the number of seconds to wait till the query executes.
Default value:
180seconds. - In the Maximum number of rows field, enter the maximum number of rows to be returned from the database.
Default value:
25. - To update the custom query, click Edit Custom Script. The Script editor dialog opens.
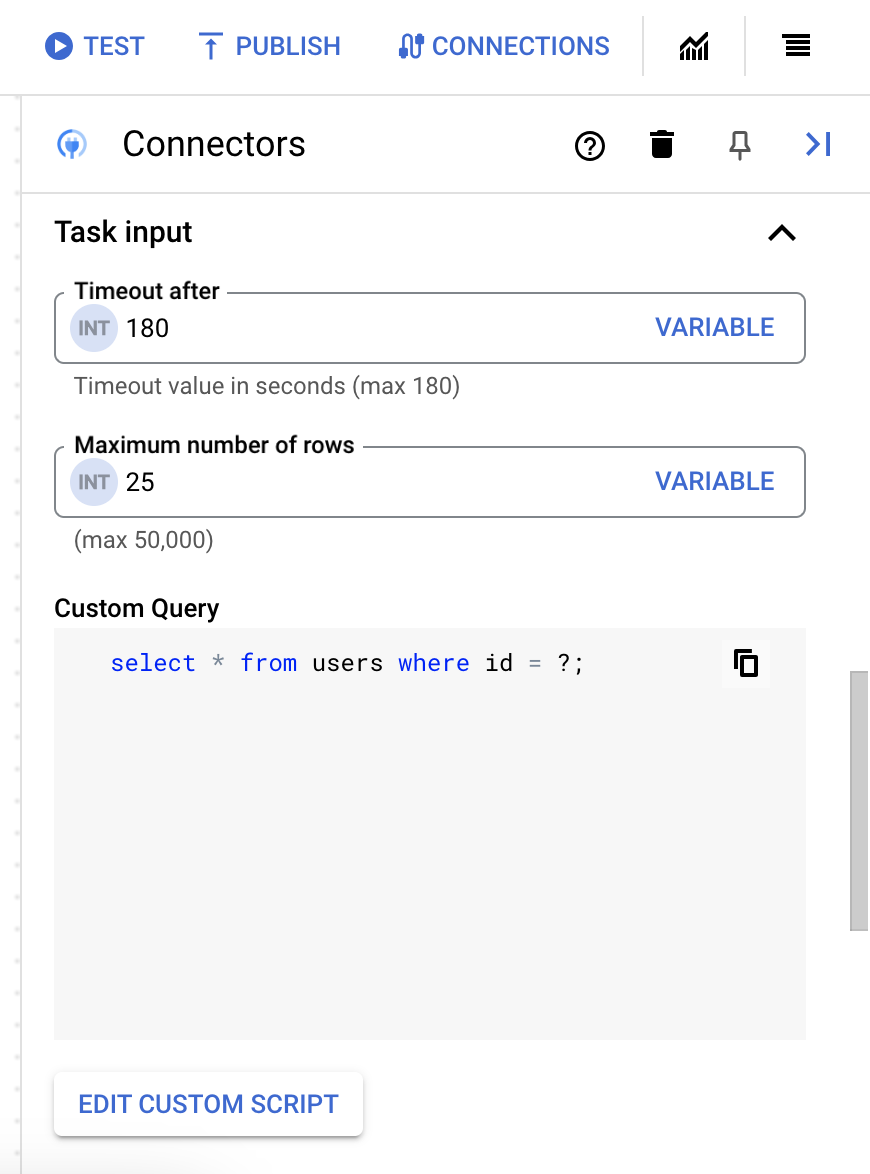
- In the Script editor dialog, enter the SQL query and click Save.
You can use a question mark (?) in a SQL statement to represent a single parameter that must be specified in the query parameters list. For example, the following SQL query selects all rows from the
Employeestable that matches the values specified for theLastNamecolumn:SELECT * FROM Employees where LastName=?
- If you've used question marks in your SQL query, you must add the parameter by clicking + Add Parameter Name for each question mark. While executing the integration, these parameters replace the question marks (?) in the SQL query sequentially. For example, if you have added three question marks (?), then you must add three parameters in order of sequence.
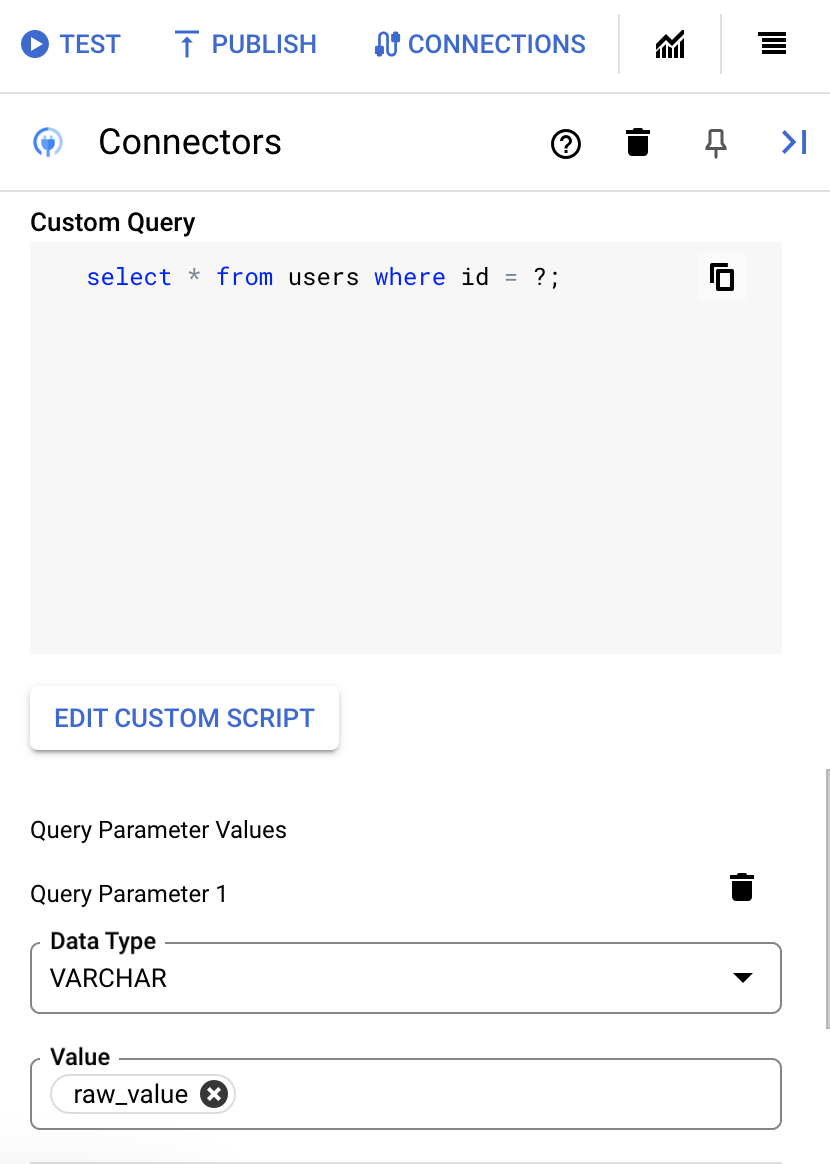
To add query parameters, do the following:
- From the Type list, select the data type of the parameter.
- In the Value field, enter the value of the parameter.
- To add multiple parameters, click + Add Query Parameter.
The Execute custom query action does not support array variables.
- In the Timeout after field, enter the number of seconds to wait till the query executes.
System limitations
The Teradata connector can process a maximum of 70 transactions per second, per node, and throttles any transactions beyond this limit. By default, Integration Connectors allocates 2 nodes (for better availability) for a connection.
For information on the limits applicable to Integration Connectors, see Limits.
Supported data types
The following are the supported data types for this connector:
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Actions
The Oracle DB connector lets you execute your stored procedures, functions, and custom SQL
queries in the format supported by your Oracle database. To execute
custom SQL queries, the connector provides the ExecuteCustomQuery
action.
ExecuteCustomQuery action
This action let your execute custom SQL queries.
Input parameters of the ExecuteCustomQuery action
| Parameter Name | Data Type | Required | Description |
|---|---|---|---|
| query | String | Yes | Query to execute. |
| queryParameters | JSON array in the following format:[{"value": "VALUE", "dataType": "DATA_TYPE"}]
|
No | Query parameters. |
| maxRows | Number | No | Maximum number of rows to be returned. |
| timeout | Number | No | Number of seconds to wait till the query executes. |
Output parameters of the ExecuteCustomQuery action
On successful execution, this action returns the status 200 (OK) with a response body that has the query results.
For example on how to configure the ExecuteCustomQuery action,
see Examples.
To understand how to use
ExecuteCustomQuery action,
see Action examples.
Action examples
This section describes how to perform some of the actions in this connector.
Example - Execute a group by query
- In the
Configure connector taskdialog, clickActions. - Select the
ExecuteCustomQueryaction, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "query": "select E.EMPLOYEE_ID,E.EMPLOYEE_NAME,E.CITY from EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID where E.EMPLOYEE_NAME = 'John' Group by E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME" }
This example selects the employee records from the EMPLOYEES
and the EMPLOYEE_DEPARTMENT tables. If the action is successful, your
connector task's connectorOutputPayload response
parameter will have the query result set.
Example - Execute a parameterized query
- In the
Configure connector taskdialog, clickActions. - Select the
ExecuteCustomQueryaction, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "query": "select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID from customqueries C,Employees E where C.ID=E.Employee_id and C.NAME=?", "queryParameters": [{ "value": "John", "dataType": "VARCHAR" }], "timeout":10, "maxRows":3 }
This example selects employee records where the name of the employee is John.
Notice that the name of the employee is parameterized by using the queryParameters parameter.
If the action is successful, your
connector task's connectorOutputPayload response
parameter will have a value similar to the following:
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
Example - Insert a record by using a sequence value
- In the
Configure connector taskdialog, clickActions. - Select the
ExecuteCustomQueryaction, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "query": "INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')" }
This example inserts a record in the AUTHOR table, by using
an existing author_table_id_seq sequence object. If the action is successful, your
connector task's connectorOutputPayload response
parameter will have a value similar to the following:
[{ }]
Example - Execute a query with an aggregate function
- In the
Configure connector taskdialog, clickActions. - Select the
ExecuteCustomQueryaction, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "query": "SELECT SUM(SALARY) as Total FROM EMPLOYEES" }
This example calculates the aggregate value of salaries in
the EMPLOYEES table. If the action is successful, your
connector task's connectorOutputPayload response
parameter will have a value similar to the following:
[{ "TOTAL": 13000.0 }]
Example - Create a new table
- In the
Configure connector taskdialog, clickActions. - Select the
ExecuteCustomQueryaction, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "query": "CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))" }
This example creates the TEST1 table. If the action is successful, your
connector task's connectorOutputPayload response
parameter will have a value similar to the following:
[{ }]
Entity operation examples
Example - List all the employees
This example lists all the employees in the Employee entity.
- In the
Configure connector taskdialog, clickEntities. - Select
Employeefrom theEntitylist. - Select the
Listoperation, and then click Done. - Optionally, in Task Input section of the Connectors task, you can filter your result set by specifying a filter clause.
Example - Get employee details
This example gets the details of the employee with the specified ID, from the Employee entity.
- In the
Configure connector taskdialog, clickEntities. - Select
Employeefrom theEntitylist. - Select the
Getoperation, and then click Done. - In the Task Input section of the Connectors task, click EntityId and
then enter
45in the Default Value field.Here,
45is the primary key value of theEmployeeentity.
Example - Create a employee record
This example adds a new employee record in the Employee entity.
- In the
Configure connector taskdialog, clickEntities. - Select
Employeefrom theEntitylist. - Select the
Createoperation, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
If the integration is successful, your connector task's
connectorOutputPayloadfield will have a value similar to the following:{ "ROWID": "AAAoU0AABAAAc3hAAF" }
Example - Update an employee record
This example updates the employee record whose ID is 69 in the Employee entity.
- In the
Configure connector taskdialog, clickEntities. - Select
Employeefrom theEntitylist. - Select the
Updateoperation, and then click Done. - In the Task Input section of the Connectors task, click
connectorInputPayloadand then enter a value similar to the following in theDefault Valuefield:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- Click entityId, and then enter
69in the Default Value field.Alternately, instead of specifying the entityId, you can also set the filterClause to
69.If the integration is successful, your connector task's
connectorOutputPayloadfield will have a value similar to the following:{ }
Example - Delete an employee record
This example deletes the employee record with the specified ID in the Employee entity.
- In the
Configure connector taskdialog, clickEntities. - Select
Employeefrom theEntitylist. - Select the
Deleteoperation, and then click Done. - In the Task Input section of the Connectors task, click entityId and
then enter
35in the Default Value field.
Create connections using Terraform
You can use the Terraform resource to create a new connection.
To learn how to apply or remove a Terraform configuration, see Basic Terraform commands.
To view a sample terraform template for connection creation, see sample template.
When creating this connection by using Terraform, you must set the following variables in your Terraform configuration file:
| Parameter name | Data type | Required | Description |
|---|---|---|---|
| client_charset | STRING | True | Specifies the Java character set for encoding and decoding character data transferred to and from the Teradata Database. |
| database | STRING | True | The database selected as the default database when a Teradata connection is opened. |
| account | STRING | False | Specifies an account string to override the default account string defined for the Teradata Database user. |
| charset | STRING | True | Specifies the session character set for encoding and decoding character data transferred to and from the Teradata Database. The default value is ASCII. |
| column_name | INTEGER | True | Controls the behavior of the ResultSetMetaData getColumnName and getColumnLabel methods. |
| connect_failure_ttl | STRING | False | This option enables the CData ADO.NET Provider for Teradata remember the time of the last connection failure for each IP address/port combination. Also, the CData ADO.NET Provider for Teradata skips connection attempts to that IP address/port during subsequent logins for the number of seconds specified by the Connect Failure time-to-live (CONNECTFAILURETTL) value. |
| connect_function | STRING | False | Specifies whether the Teradata Database should allocate a Logon Sequence Number (LSN) for this session or associate this session with an existing LSN. |
| cop | STRING | False | Specifies whether COP Discovery is performed. |
| cop_last | STRING | False | Specifies how COP Discovery determines the last COP hostname. |
| ddstats | ENUM | False | Specify the value for DDSTATS. Supported values are: ON, OFF |
| disable_auto_commit_in_batch | BOOLEAN | True | Specifies whether or not disable the autocommit when executing the batch operation. |
| encrypt_data | ENUM | False | Specify the EncryptData value, ON or OFF. Supported values are: ON, OFF |
| error_query_count | STRING | False | Specifies the maximum number of times that JDBC FastLoad will attempt to query FastLoad Error Table 1 after a JDBC FastLoad operation. |
| error_query_interval | STRING | False | Specifies the number of milliseconds that JDBC FastLoad will wait in between attempts to query FastLoad Error Table 1 after a JDBC FastLoad operation. |
| error_table1_suffix | STRING | False | Specifies the suffix for the name of FastLoad Error Table 1 created by JDBC FastLoad and JDBC FastLoad CSV. |
| error_table2_suffix | STRING | False | Specifies the suffix for the name of FastLoad Error Table 2 created by JDBC FastLoad and JDBC FastLoad CSV. |
| error_table_database | STRING | False | Specifies the database name for the FastLoad error tables created by JDBC FastLoad and JDBC FastLoad CSV. |
| field_sep | STRING | False | Specifies a field separator for use with JDBC FastLoad CSV only. The default separator is ',' (comma). |
| finalize_auto_close | STRING | False | Specify the value for FinalizeAutoClose, ON or OFF. |
| geturl_credentials | STRING | False | Specify the value for GeturlCredentials, ON or OFF. |
| govern | STRING | False | Specify the value for GOVERN, ON or OFF. |
| literal_underscore | STRING | False | Automatically escape LIKE-predicate patterns in DatabaseMetaData calls, such as schemPattern and tableNamePattern. |
| lob_support | STRING | False | Specify the value for LobSupport, ON or OFF. |
| lob_temp_table | STRING | False | Specifies the name of a table with the following columns: id integer, bval blob, cval clob. |
| log | STRING | False | Specifies the logging level (verbosity) for a connection. Logging is always enabled. The logging levels are listed in order from terse to verbose. |
| log_data | STRING | False | Specifies additional data needed by a logon mechanism, such as a secure token, Distinguished Name, or a domain/realm name. |
| log_mech | STRING | False | Specifies the Logon Mechanism, which determines the connection's authentication and encryption capabilities. |
| logon_sequence_number | STRING | False | Specifies an existing Logon Sequence Number (LSN) to associate this session with. |
| max_message_body | STRING | False | Specifies the maximum Response Message size in bytes. |
| maybe_null | STRING | False | Controls the behavior of the ResultSetMetaData.isNullable method. |
| new_password | STRING | False | This connection parameter enables an application to change an expired password automatically. |
| partition | STRING | False | Specifies the Teradata Database partition for the Connection. |
| prep_support | STRING | False | Specifies whether the Teradata Database performs a prepare operation when a PreparedStatement or CallableStatement is created. |
| reconnect_count | STRING | False | Enables Teradata Session Reconnect. Specifies the maximum number of times that the Teradata JDBC Driver will attempt to reconnect the session. |
| reconnect_interval | STRING | False | Enables Teradata Session Reconnect. Specifies the number of seconds that the Teradata JDBC Driver will wait in between attempts to reconnect the session. |
| redrive | STRING | False | Enables Teradata Session Reconnect, and also enables automatic redriving of SQL requests interrupted by database restart. |
| run_startup | STRING | False | Specify the value for RunStartup, ON or OFF. |
| sessions | STRING | False | Specifies the number of FastLoad or FastExport connections to be created, where 1 <= number of FastLoad or FastExport connections <= number of AMPs. |
| sip_support | STRING | False | Controls whether the Teradata Database and Teradata JDBC Driver use StatementInfo Parcel (SIP) to convey metadata. |
| slob_receive_threshold | STRING | False | Controls how small LOB values are received from the Teradata Database. Small LOB values are pre-fetched from the Teradata Database before the application explicitly reads data from Blob/Clob objects. |
| slob_transmit_threshold | STRING | False | Controls how small LOB values are transmitted to the Teradata Database. |
| sp_spl | STRING | False | Specifies behavior for creating or replacing Teradata stored procedures. |
| strict_encode | STRING | False | Specifies behavior for encoding character data to transmit to the Teradata Database. |
| tmode | STRING | False | Specifies the transaction mode for the connection. |
| tnano | STRING | False | Specifies the fractional seconds precision for all java.sql.Time values bound to a PreparedStatement or CallableStatement and transmitted to the Teradata Database as TIME or TIME WITH TIME ZONE values. |
| tsnano | STRING | False | Specifies the fractional seconds precision for all java.sql.Timestamp values bound to a PreparedStatement or CallableStatement and transmitted to the Teradata Database as TIMESTAMP or TIMESTAMP WITH TIME ZONE values. |
| tcp | STRING | False | Specifies one or more TCP socket settings, separated by plus signs (). |
| trusted_sql | STRING | False | Specify the value for TrustedSql. |
| type | STRING | False | Specifies the type of protocol to be used with the Teradata Database for SQL statements. |
| upper_case_identifiers | BOOLEAN | False | This property reports all identifiers in uppercase. This is the default for Oracle databases and thus allows better integration with Oracle tools such as the Oracle Database Gateway. |
| use_xviews | STRING | False | Specifies which Data Dictionary views should be queried to return result sets from DatabaseMetaData methods. |
Use the Teradata connection in an integration
After you create the connection, it becomes available in both Apigee Integration and Application Integration. You can use the connection in an integration through the Connectors task.
- To understand how to create and use the Connectors task in Apigee Integration, see Connectors task.
- To understand how to create and use the Connectors task in Application Integration, see Connectors task.
Get help from the Google Cloud community
You can post your questions and discuss this connector in the Google Cloud community at Cloud Forums.What's next
- Understand how to suspend and resume a connection.
- Understand how to monitor connector usage.
- Understand how to view connector logs.