미디어 검색 시작하기
최첨단 미디어 검색 앱을 빠르게 빌드할 수 있습니다. 미디어 검색을 사용하면 잠재고객이 Google 품질의 결과를 통해 콘텐츠를 검색할 수 있습니다.
미디어용 Vertex AI Search에 관한 일반적인 정보는 미디어 검색 및 추천 소개를 참조하세요.이 시작하기 튜토리얼에서는 Movielens 데이터 세트를 사용하여 미디어 콘텐츠 카탈로그를 Vertex AI Search에 업로드하는 방법을 보여줍니다. Movielens 데이터 세트에는 영화(문서) 카탈로그가 포함되어 있습니다.
영화 데이터를 업로드한 후에는 검색 앱을 만들고 미리보기 페이지를 통해 테스트합니다.
미디어 추천 시작하기 튜토리얼을 완료했고 여전히 데이터 스토어(권장 이름 quickstart-media-data-store)가 있다면 다른 데이터 스토어를 만드는 대신 해당 데이터 스토어를 사용할 수 있습니다. 이 경우 미디어 검색을 위한 앱 만들기에서 튜토리얼을 시작해야 합니다.
이 튜토리얼을 완료하는 데 걸리는 예상 시간: 약 1시간
목표
- 미디어 문서를 가져와 미디어 데이터 스토어를 만드는 방법을 알아봅니다.
- 검색 앱을 만들고 구성하고 테스트합니다.
이 튜토리얼을 수행하기 전에 시작하기 전에의 단계를 완료해야 합니다.
Google Cloud 콘솔에서 이 태스크에 대한 단계별 안내를 직접 수행하려면 둘러보기를 클릭합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM으로 이동 - 프로젝트를 선택합니다.
- 액세스 권한 부여를 클릭합니다.
-
새 주 구성원 필드에 사용자 식별자를 입력합니다. 일반적으로 Google 계정의 이메일 주소입니다.
- 역할 선택 목록에서 역할을 선택합니다.
- 역할을 추가로 부여하려면 다른 역할 추가를 클릭하고 각 역할을 추가합니다.
- 저장을 클릭합니다.
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM으로 이동 - 프로젝트를 선택합니다.
- 액세스 권한 부여를 클릭합니다.
-
새 주 구성원 필드에 사용자 식별자를 입력합니다. 일반적으로 Google 계정의 이메일 주소입니다.
- 역할 선택 목록에서 역할을 선택합니다.
- 역할을 추가로 부여하려면 다른 역할 추가를 클릭하고 각 역할을 추가합니다.
- 저장을 클릭합니다.
-
- Google Cloud 콘솔을 엽니다.
- Google Cloud 프로젝트를 선택합니다.
- 대시보드 페이지의 프로젝트 정보 카드에서 프로젝트 ID를 기록해 둡니다. 다음 절차를 수행하려면 프로젝트 ID가 필요합니다.
콘솔의 상단에서 Cloud Shell 활성화 버튼을 클릭합니다.Google Cloud 콘솔 하단의 새 프레임에서 Cloud Shell 세션이 열리고 명령줄 프롬프트가 표시됩니다. Cloud Shell을 실행하는 다른 방법은 Cloud Shell 실행을 참고하세요.

프로젝트 ID를 사용하여 다음을 실행하여 명령줄의 기본 프로젝트를 설정합니다.
gcloud config set project PROJECT_IDBigQuery 데이터 세트를 만듭니다.
bq mk movielensmovies.csv를 새moviesBigQuery 테이블에 로드합니다.bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresratings.csv를 새ratingsBigQuery 테이블에 로드합니다.bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp영화 테이블을
Document스키마로 변환하는 뷰를 만듭니다.bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_view이제 새 뷰에는 Discovery Engine API에 필요한 스키마가 포함됩니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 펼치고 데이터 세트를 클릭한 다음
movielens데이터 세트를 선택하고movies_view를 클릭하여 이 뷰의 스키마 페이지를 엽니다.또는 탐색기 창에서 기존 탐색기 탭을 선택하고 프로젝트 이름을 펼치고
movielens데이터 세트를 펼친 다음movies_view를 클릭하여 이 뷰의 스키마 페이지를 엽니다.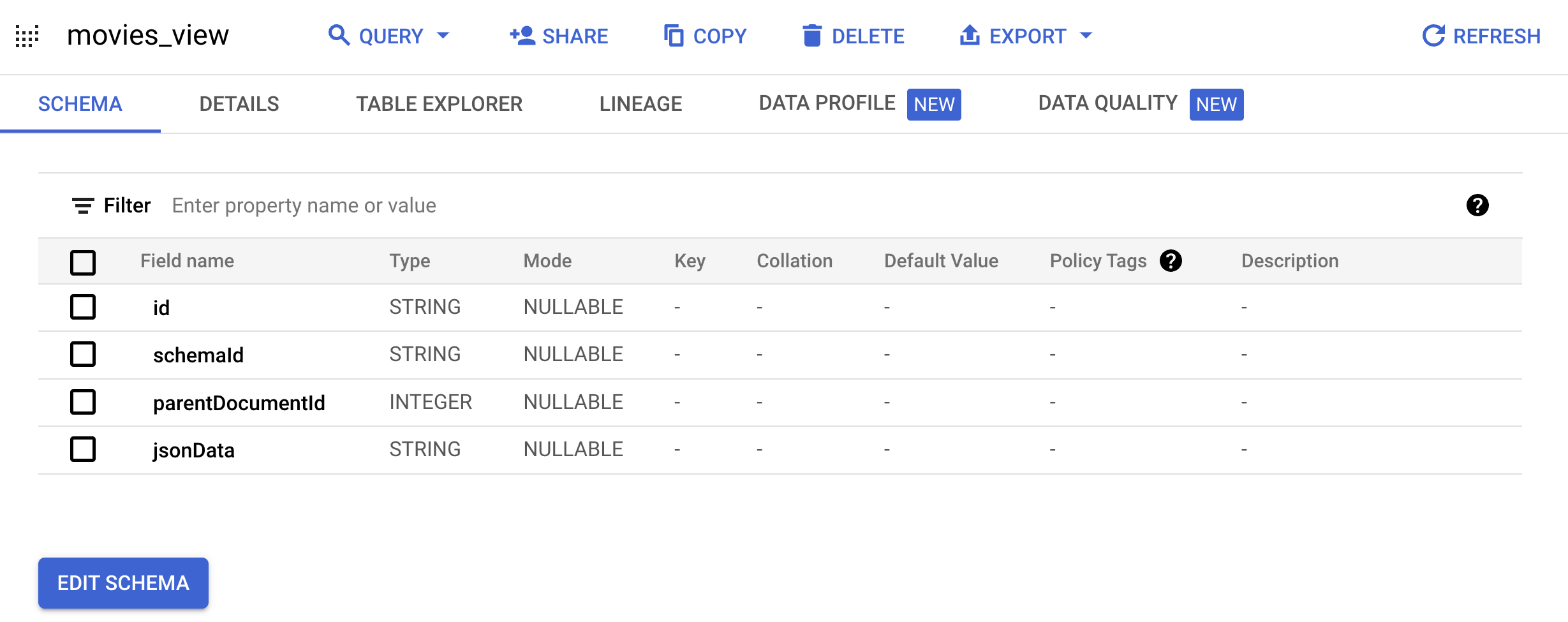
테이블 탐색기 탭으로 이동합니다.
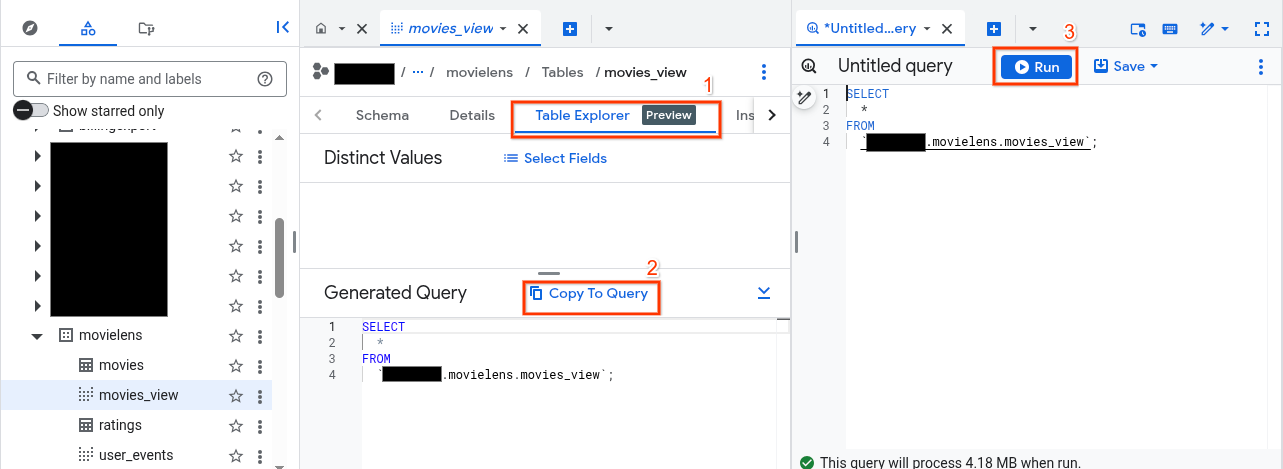
생성된 쿼리 창에서 쿼리에 복사 버튼을 클릭합니다. 쿼리 편집기가 열립니다.
실행을 클릭하여 생성한 뷰에서 영화 데이터를 확인합니다.
다음 Cloud Shell 명령어를 실행하여 영화 평점에서 가상의 사용자 이벤트를 만듭니다.
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsGoogle Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
선택사항: Google이 모델 입력과 대답을 선택적으로 샘플링할 수 있도록 허용을 클릭합니다.
계속 및 API 활성화를 클릭합니다.
Google Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
앱 만들기 를 클릭합니다.앱 만들기 페이지의 미디어 카탈로그 검색에서 만들기를 클릭합니다.
앱 이름 필드에 앱 이름(예:
quickstart-media-search)을 입력합니다. 엔진 이름 아래에 앱 ID가 표시됩니다.계속을 클릭합니다.
미디어 추천 시작하기 튜토리얼을 완료했고 여전히 데이터 스토어(권장 이름
quickstart-media-data-store)가 있다면 데이터 스토어를 선택하고 만들기를 클릭하여 미리보기 검색으로 건너뛰세요.Movielens 데이터 세트가 포함된 데이터 스토어가 없는 경우 새 데이터 스토어를 만들고 선택합니다.
데이터 스토어 페이지에서 데이터 스토어 만들기를 클릭합니다.
데이터 스토어의 표시 이름(예:
quickstart-media-data-store)을 입력한 후 만들기를 클릭합니다.방금 만든 데이터 스토어를 선택한 후 만들기를 클릭하여 앱을 만듭니다. 데이터 소스 선택 페이지로 리디렉션됩니다.
데이터 소스 선택 페이지로 자동 리디렉션되지 않으면 다음 단계를 따르세요.
- 문서 탭을 엽니다.
- 데이터 가져오기를 클릭합니다.
데이터 소스 선택 페이지에서 BigQuery를 선택합니다.
만든
moviesBigQuery 뷰의 이름을 입력하고 가져오기를 클릭합니다.PROJECT_ID.movielens.movies_view모든 문서를 가져올 때까지 기다립니다. 15분 정도 걸립니다. 완료되면 86,537개의 문서가 있습니다.
활동 탭에서 가져오기 작업 상태를 확인할 수 있습니다. 가져오기가 완료되면 가져오기 작업 상태가 완료로 변경됩니다.
이벤트 탭을 엽니다.
이벤트 가져오기를 클릭합니다.
BigQuery를 선택합니다.
만든
user_eventsBigQuery 뷰의 이름을 입력하고 가져오기를 클릭합니다.PROJECT_ID.movielens.user_events이벤트를 가져오기 전에 다음 단계로 진행할 수 있지만 검색 결과에 아직 전체 데이터 세트가 포함되지는 않습니다.
활동 탭에서 작업 상태를 확인할 수 있습니다. 수백만 개의 행을 가져오므로 이 프로세스를 완료하는 데 1시간 정도 걸립니다.
탐색 메뉴에서
구성 을 클릭합니다.여기에서 검색 상자에 '반지의 제왕'과 같은 영화 이름을 입력합니다.
검색 결과가 입력한 영화 제목과 관련이 있습니다.
이 페이지에서 검색 위젯이 검색 결과 정보를 표시하는 방식을 맞춤설정할 수 있습니다. 자세히 알아보려면 검색 위젯의 결과 구성을 참조하세요.
미디어 검색 앱의 경우 다음을 할 수 있습니다.
변경 후 저장 및 게시를 클릭하여 위젯을 업데이트합니다.
탐색 메뉴에서 통합을 클릭합니다.
위젯 탭이 선택되었는지 확인합니다.
위젯 승인 유형으로 JWT 또는 OAuth 기반을 선택합니다.
도메인 필드에 위젯을 배치할 웹페이지의 도메인 이름을 입력합니다. 예를 들어 위젯을 웹페이지
example.com/ai.html에 복사하려면example.com을 도메인으로 입력합니다.추가를 클릭한 후 저장을 클릭합니다.
웹 애플리케이션에 다음 코드 복사 섹션에 제공된 코드 스니펫을 복사합니다.
코드베이스에서 승인 토큰을 생성합니다.
위젯에 승인 토큰을 전달하려면 다음 코드를 웹 애플리케이션에 복사 섹션의 '승인 토큰 설정' 코드 스니펫을 사용하고
<JWT or OAuth token provided by you backend>텍스트를 승인 토큰으로 바꾸세요.검색 앱을 웹 앱에 통합하는 데 도움이 필요하면 검색 결과 가져오기의 코드 샘플을 참조하세요.
- 불필요한 Google Cloud 요금이 청구되지 않도록 하려면Google Cloud console 을 사용하여 필요하지 않은 프로젝트를 삭제하세요.
- Vertex AI Search 학습용으로 만든 새 프로젝트가 더 이상 필요 없는 경우 프로젝트를 삭제하세요.
- 기존 Google Cloud 프로젝트를 사용한 경우 계정에 요금이 청구되지 않도록 만든 리소스를 삭제합니다. 자세한 내용은 앱 삭제, 데이터 스토어에서 데이터 영구 삭제, 데이터 스토어 삭제를 참조하세요.
- Vertex AI Search 사용 중지의 단계를 수행합니다.
BigQuery 데이터 세트를 만든 경우 Cloud Shell에서 삭제합니다.
bq rm --recursive --dataset movielens
데이터 세트 준비
참고: 미디어 추천 시작하기 튜토리얼을 완료했고 여전히 데이터 스토어(권장 이름:quickstart-media-data-store)가 있다면 미디어 검색을 위한 앱 만들기로 건너뛰세요.
Cloud Shell을 사용하여 Movielens 데이터 세트를 가져오고 미디어용 Vertex AI Search 데이터 세트를 재구성합니다.
Cloud Shell 열기
데이터 세트 가져오기
공개 Cloud Storage 버킷에서 Movielens 데이터 세트를 제공하므로 더 쉽게 가져올 수 있습니다.
BigQuery 뷰 만들기
이 단계에서는 Movielens 데이터 세트를 재구성하여 미디어 데이터 스토어의 예상 형식을 따르도록 합니다.
이 가이드에서는 지난 90일 동안의 긍정적인 평점(>= 4)에서 가짜 view-item 사용자 이벤트를 만듭니다.
Vertex AI Search 활성화
미디어 검색을 위한 앱 만들기
이 섹션의 절차는 미디어 검색 앱을 만들고 배포하는 방법을 안내합니다.
데이터 가져오기
그 다음 이전에 형식이 지정된 영화 및 사용자 이벤트 데이터를 가져옵니다.
문서 가져오기
사용자 이벤트 가져오기
검색 미리보기 및 구성
검색 위젯 배포
삭제
이 페이지에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 수행합니다.
미디어 추천 시작하기 튜토리얼에서 미디어 추천을 위해 만든 데이터 스토어를 재사용할 수 있습니다. 이 삭제 절차를 수행하기 전에 해당 튜토리얼을 시도해 보세요.