Puoi utilizzare Enterprise Document OCR come parte di Document AI per rilevare ed estrarre testo e informazioni sul layout da vari documenti. Grazie alle funzionalità configurabili, puoi personalizzare il sistema per soddisfare requisiti specifici di elaborazione dei documenti.
Panoramica
Puoi utilizzare Enterprise Document OCR per attività come l'inserimento di dati basato su algoritmi o machine learning e per migliorare e verificare l'accuratezza dei dati. Puoi anche utilizzare Enterprise Document OCR per gestire attività come le seguenti:
- Digitalizzazione del testo:estrai testo e dati di layout dai documenti per la ricerca, pipeline di elaborazione dei documenti basate su regole o creazione di modelli personalizzati.
- Utilizzo di applicazioni di modelli linguistici di grandi dimensioni: utilizza la comprensione contestuale degli LLM e le funzionalità di estrazione di testo e layout dell'OCR per automatizzare domande e risposte. Estrai insight dai dati e semplifica i flussi di lavoro.
- Archiviazione:digitalizza i documenti cartacei in testo leggibile dalla macchina per migliorare l'accessibilità dei documenti.
Scegliere l'OCR migliore per il tuo caso d'uso
| Soluzione | Prodotto | Descrizione | Caso d'uso |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Modello specializzato per i casi d'uso dei documenti. Le funzionalità avanzate includono il punteggio di qualità dell'immagine, i suggerimenti sulla lingua e la correzione della rotazione. | Consigliato per l'estrazione del testo dai documenti. I casi d'uso includono PDF, documenti scansionati come immagini o file Microsoft DocX. |
| Document AI | Componenti aggiuntivi OCR | Funzionalità premium per requisiti specifici. Compatibile solo con Enterprise Document OCR versione 2.0 e successive. | Devi rilevare e riconoscere formule matematiche, ricevere informazioni sullo stile dei caratteri o attivare l'estrazione delle caselle di controllo. |
| API Cloud Vision | Rilevamento del testo | API REST disponibile a livello globale basata sul modello OCR standard. Google Cloud Quota predefinita di 1800 richieste al minuto. | Casi d'uso generici per l'estrazione del testo che richiedono bassa latenza e capacità elevata. |
| Cloud Vision | OCR Google Distributed Cloud (ritirato) | Applicazione Google Cloud Marketplace di cui è possibile eseguire il deployment come container in qualsiasi cluster GKE utilizzando GKE Enterprise. | Per soddisfare i requisiti di conformità o residenza dei dati. |
Rilevamento ed estrazione
Enterprise Document OCR è in grado di rilevare blocchi, paragrafi, righe, parole e simboli da PDF e immagini, nonché di raddrizzare i documenti per una maggiore precisione.
Attributi di rilevamento ed estrazione del layout supportati:
| Printed text | Scrittura a mano libera | Paragrafo | Blocca | Linea | Word | Livello di simbolo | Numero di pagina |
|---|---|---|---|---|---|---|---|
| Predefinito | Predefinito | Predefinito | Predefinito | Predefinito | Predefinito | Configurabile | Predefinito |
Le funzionalità configurabili di Enterprise Document OCR includono:
Estrai testo incorporato o nativo dai PDF digitali:questa funzionalità estrae testo e simboli esattamente come appaiono nei documenti di origine, anche per testi ruotati, stili o dimensioni dei caratteri estreme e testo parzialmente nascosto.
Correzione della rotazione:utilizza Enterprise Document OCR per preelaborare le immagini dei documenti per correggere i problemi di rotazione che possono influire sulla qualità dell'estrazione o sull'elaborazione.
Punteggio di qualità dell'immagine:ricevi metriche di qualità che possono aiutarti con l'instradamento dei documenti. Il punteggio di qualità delle immagini fornisce metriche di qualità a livello di pagina in otto dimensioni, tra cui sfocatura, presenza di caratteri più piccoli del solito e abbagliamento.
Specifica intervallo di pagine:specifica l'intervallo di pagine in un documento di input per l'OCR. In questo modo si risparmia tempo di spesa ed elaborazione rispetto a pagine non necessarie.
Rilevamento della lingua:rileva le lingue utilizzate nei testi estratti.
Suggerimenti per la lingua e la scrittura: migliora l'accuratezza fornendo al modello OCR un suggerimento per la lingua o la scrittura in base alle caratteristiche note del tuo set di dati.
Per scoprire come attivare le configurazioni OCR, consulta Attivare le configurazioni OCR.
Componenti aggiuntivi OCR
Enterprise Document OCR offre funzionalità di analisi facoltative che possono essere attivate su singole richieste di elaborazione in base alle esigenze.
Le seguenti funzionalità aggiuntive sono disponibili per le versioni Stable
pretrained-ocr-v2.0-2023-06-02 e pretrained-ocr-v2.1-2024-08-07
e per la versione Release Candidate pretrained-ocr-v2.1.1-2025-01-31.
- OCR matematico: identifica ed estrai le formule dai documenti in formato LaTeX.
- Estrazione delle caselle di controllo: rileva le caselle di controllo ed estrai il loro stato (contrassegnato/non contrassegnato) nella risposta di Enterprise Document OCR.
- Rilevamento dello stile del carattere: identifica le proprietà del carattere a livello di parola, tra cui tipo, stile, calligrafia, spessore e colore.
Per scoprire come attivare i componenti aggiuntivi elencati, consulta Attivare i componenti aggiuntivi OCR.
Formati di file supportati
Enterprise Document OCR supporta i formati file PDF, GIF, TIFF, JPEG, PNG, BMP e WebP. Per ulteriori informazioni, vedi File supportati.
Enterprise Document OCR supporta anche i file DocX fino a 15 pagine in modalità sincrona e 30 pagine in modalità asincrona. Per presentare una richiesta di aumento della quota (QIR), segui i passaggi descritti in Richiedi un aggiustamento della quota. Il supporto di DocX è in anteprima privata. Per richiedere l'accesso, contatta il team del tuo Account Google.
Controllo versioni avanzato
Il controllo delle versioni avanzato è in anteprima. Gli upgrade ai modelli OCR di AI/ML sottostanti potrebbero comportare modifiche al comportamento dell'OCR. Se è necessaria una coerenza rigorosa, utilizza una versione del modello bloccata per bloccare il comportamento di un modello OCR legacy per un massimo di 18 mesi. In questo modo, si garantisce lo stesso risultato della funzione OCR. Consulta la tabella sulle versioni del processore.
Versioni del processore
Le seguenti versioni del processore sono compatibili con questa funzionalità. Per saperne di più, consulta Gestione delle versioni del processore.
| ID versione | Canale di rilascio | Descrizione |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stabile | Versione del modello bloccata v1.0: file, configurazioni e binari del modello di un'istantanea della versione bloccati in un'immagine container per un massimo di 18 mesi. |
pretrained-ocr-v2.0-2023-06-02 |
Stabile | Modello pronto per la produzione specializzato per i casi d'uso dei documenti. Include l'accesso a tutti i componenti aggiuntivi OCR. |
pretrained-ocr-v2.1-2024-08-07 |
Stabile | Le principali aree di miglioramento della versione 2.1 sono: un migliore riconoscimento del testo stampato, un rilevamento più preciso delle caselle di controllo e un ordine di lettura più accurato. |
pretrained-ocr-v2.1.1-2025-01-31 |
Candidato per la release | La versione 2.1.1 è simile alla versione 2.1 ed è disponibile in tutte le regioni, ad eccezione di: US, EU e asia-southeast1. |
Utilizzare Enterprise Document OCR per elaborare i documenti
Questa guida rapida introduce Enterprise Document OCR. Mostra come ottimizzare i risultati dell'OCR dei documenti per il tuo flusso di lavoro attivando o disattivando una qualsiasi delle configurazioni OCR disponibili.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Può restituire rilevamenti di falsi positivi con documenti digitali senza difetti. La funzionalità è più efficace sui documenti scansionati o fotografati.
I difetti di abbagliamento sono locali. La loro presenza potrebbe non compromettere la leggibilità complessiva del documento.
- Per elaborare solo la seconda e la quinta pagina:
- Per elaborare solo le prime tre pagine:
- Per elaborare solo le ultime quattro pagine:
Immagine rilevata
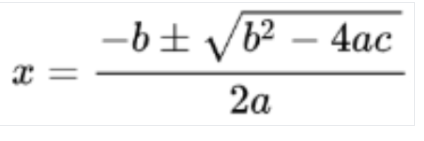
Conversione in LaTeX
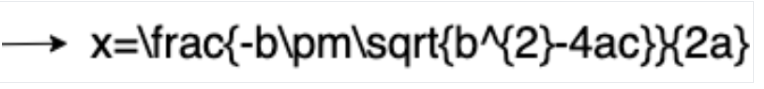
- Rilevamento della scrittura a mano libera
- Stile carattere
- Dimensione carattere
- Tipo di carattere
- Colore carattere
- Spessore del carattere
- Spaziatura tra le lettere
- Grassetto
- Corsivo
- Sottolineato
- Colore testo (RGBa)
Colore sfondo (RGBa)
- La risposta dell'API Vision AI compila solo
verticesper le richieste di immagini e solonormalized_verticesper le richieste di PDF. La risposta di Document AI e il convertitore compilano siaverticeschenormalized_vertices. - La risposta dell'API Vision AI compila il campo
detected_breaknell'ultimo simbolo della parola. La risposta dell'API Document AI e il convertitore compilanodetected_breaknella parola e nell'ultimo simbolo della parola. - La risposta dell'API Vision AI compila sempre i campi dei simboli. Per impostazione predefinita, la risposta di Document AI non compila i campi dei simboli. Per assicurarti che la risposta di Document AI e il convertitore compilino i campi dei simboli, imposta la funzionalità
enable_symbolcome dettagliata. - LOCATION: la posizione del tuo responsabile del trattamento, ad esempio:
us- Stati Unitieu- Unione Europea
- PROJECT_ID: il tuo ID progetto Google Cloud .
- PROCESSOR_ID: l'ID del tuo processore personalizzato.
- PROCESSOR_VERSION: l'identificatore della versione del processore. Per saperne di più, consulta Selezionare una versione del processore. Ad esempio:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: un valore booleano per disattivare la revisione umana (supportato solo dai processori Human-in-the-Loop).
true- skips human reviewfalse: attiva la revisione umana (impostazione predefinita)
- MIME_TYPE†: una delle opzioni valide per il tipo MIME.
- IMAGE_CONTENT†: uno dei contenuti validi
del documento in linea, rappresentati come
un flusso di byte. Per le rappresentazioni JSON, la codifica base64 (stringa ASCII) dei dati immagine binari. Questa stringa dovrebbe essere simile alla
seguente:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: specifica quali campi includere nell'output
Document. Si tratta di un elenco separato da virgole di nomi completi dei campi nel formatoFieldMask.- Esempio:
text,entities,pages.pageNumber
- Esempio:
- Configurazioni OCR
- ENABLE_NATIVE_PDF_PARSING: (booleano) estrae il testo incorporato dai PDF, se disponibile.
- ENABLE_IMAGE_QUALITY_SCORES: (booleano) attiva i punteggi di qualità intelligenti per i documenti.
- ENABLE_SYMBOL: (booleano) include informazioni OCR sui simboli (lettere).
- DISABLE_CHARACTER_BOXES_DETECTION: (booleano) Disattiva il rilevatore di caselle di caratteri nel motore OCR.
- LANGUAGE_HINTS: elenco dei codici lingua BCP-47 da utilizzare per l'OCR.
- ADVANCED_OCR_OPTIONS: un elenco di opzioni OCR avanzate per perfezionare ulteriormente il comportamento dell'OCR. I valori validi attuali sono:
legacy_layout: un algoritmo di rilevamento del layout euristico, che funge da alternativa all'attuale algoritmo di rilevamento del layout basato su ML.
- Componenti aggiuntivi OCR premium
- ENABLE_SELECTION_MARK_DETECTION: (booleano) attiva il rilevatore del segno di selezione nel motore OCR.
- COMPUTE_STYLE_INFO (booleano) Attiva il modello di identificazione dei caratteri e restituisce le informazioni sullo stile dei caratteri.
- ENABLE_MATH_OCR: (booleano) attiva il modello in grado di estrarre le formule matematiche LaTeX.
- INDIVIDUAL_PAGES: un elenco di singole pagine da elaborare.
- Esamina l'elenco dei processori.
- Separa i documenti in chunk leggibili con il parser di layout.
- Crea un classificatore personalizzato.
Crea un processore Enterprise Document OCR
Innanzitutto, crea un processore Enterprise Document OCR. Per saperne di più, consulta la pagina Creare e gestire i processori.
Configurazioni OCR
Tutte le configurazioni OCR possono essere abilitate impostando i rispettivi campi in ProcessOptions.ocrConfig in ProcessDocumentRequest o BatchProcessDocumentsRequest.
Per saperne di più, consulta Inviare una richiesta di elaborazione.
Analisi della qualità dell'immagine
L'analisi intelligente della qualità dei documenti utilizza il machine learning per eseguire la valutazione della qualità di un documento in base alla leggibilità dei suoi contenuti.
Questa valutazione della qualità viene restituita come punteggio di qualità [0, 1], dove 1 indica una qualità perfetta.
Se il punteggio di qualità rilevato è inferiore a 0.5, viene restituito anche un elenco di motivi di qualità negativi (ordinati in base alla probabilità).
Una probabilità superiore a 0.5 è considerata un rilevamento positivo.
Se il documento viene considerato difettoso, l'API restituisce i seguenti otto tipi di difetti del documento:
L'attuale analisi della qualità dei documenti presenta alcune limitazioni:
Input
Attiva impostando ProcessOptions.ocrConfig.enableImageQualityScores su true nella richiesta di elaborazione.
Questa funzionalità aggiuntiva aggiunge alla chiamata di processo una latenza paragonabile a quella dell'elaborazione OCR.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Output
I risultati del rilevamento dei difetti vengono visualizzati in Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Per esempi di output completi, consulta Esempio di output del processore.
Suggerimenti per la lingua
Il processore OCR supporta i suggerimenti per la lingua che definisci per migliorare le prestazioni del motore OCR. L'applicazione di un suggerimento di lingua consente all'OCR di ottimizzare una lingua selezionata anziché una lingua dedotta.
Input
Attiva impostando ProcessOptions.ocrConfig.hints[].languageHints[] con un elenco di codici lingua BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Per esempi di output completi, consulta Esempio di output del processore.
Rilevamento dei simboli
Inserisci i dati a livello di simbolo (o singola lettera) nella risposta del documento.
Input
Attiva impostando ProcessOptions.ocrConfig.enableSymbol su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Output
Se questa funzionalità è attivata, il campo Document.pages[].symbols[] viene compilato.
Per esempi di output completi, consulta Esempio di output del processore.
Analisi PDF integrata
Estrai il testo incorporato dai file PDF digitali. Se attivato, se è presente testo digitale, viene utilizzato automaticamente il modello PDF digitale integrato. Se è presente testo non digitale, viene utilizzato automaticamente il modello OCR ottico. L'utente riceve entrambi i risultati di testo uniti.
Input
Attiva impostando ProcessOptions.ocrConfig.enableNativePdfParsing su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Rilevamento del personaggio nella scatola
Per impostazione predefinita, Enterprise Document OCR ha un rilevatore attivato per migliorare la qualità dell'estrazione del testo dei caratteri contenuti in una casella. Ecco un esempio:

Se riscontri problemi di qualità dell'OCR con i caratteri all'interno delle caselle, puoi disattivarlo.
Input
Disattiva impostando ProcessOptions.ocrConfig.disableCharacterBoxesDetection su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Layout legacy
Se hai bisogno di un algoritmo di rilevamento del layout euristico, puoi attivare il layout legacy, che funge da alternativa all'attuale algoritmo di rilevamento del layout basato su ML. Questa non è la configurazione consigliata. I clienti possono scegliere l'algoritmo di layout più adatto in base al flusso di lavoro dei documenti.
Input
Attiva impostando ProcessOptions.ocrConfig.advancedOcrOptions su ["legacy_layout"] nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Specificare un intervallo di pagine
Per impostazione predefinita, l'OCR estrae il testo e le informazioni sul layout da tutte le pagine dei documenti. Puoi selezionare numeri di pagina o intervalli di pagine specifici ed estrarre il testo solo da queste pagine.
Esistono tre modi per configurare questa impostazione in ProcessOptions:
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
Nella risposta, ogni Document.pages[].pageNumber corrisponde alle stesse pagine specificate nella richiesta.
Utilizzi dei componenti aggiuntivi OCR
Queste funzionalità di analisi facoltative di Enterprise Document OCR possono essere attivate su singole richieste di elaborazione in base alle esigenze.
OCR matematico
L'OCR matematico rileva, riconosce ed estrae le formule, ad esempio le equazioni matematiche rappresentate come LaTeX, insieme alle coordinate del riquadro di delimitazione.
Ecco un esempio di rappresentazione LaTeX:
Input
Attiva impostando ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Output
L'output dell'OCR matematico viene visualizzato in Document.pages[].visualElements[] con "type": "math_formula".

"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Puoi controllare l'output JSON completo di Document in questo link .
Estrazione del segno di selezione
Se attivato, il modello tenta di estrarre tutte le caselle di controllo e i pulsanti di opzione nel documento, insieme alle coordinate del riquadro di delimitazione.
Input
Attiva impostando ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Output
L'output della casella di controllo viene visualizzato in Document.pages[].visualElements[] con "type": "unfilled_checkbox" o "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Puoi controllare l'output JSON completo di Document in questo link .
Rilevamento dello stile del carattere
Se il rilevamento dello stile del carattere è attivato, Enterprise Document OCR estrae gli attributi del carattere, che possono essere utilizzati per un migliore post-elaborazione.
A livello di token (parola), vengono rilevati i seguenti attributi:
Input
Attiva impostando ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo su true nella richiesta di elaborazione.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Output
L'output dello stile del carattere viene visualizzato in Document.pages[].tokens[].styleInfo con il tipo StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Puoi controllare l'output JSON completo di Document in questo link .
Convertire gli oggetti del documento nel formato dell'API Vision AI
Document AI Toolbox include uno strumento che converte il formato Document dell'API Document AI nel formato AnnotateFileResponse di Vision AI, consentendo agli utenti di confrontare le risposte tra il processore OCR di documenti e l'API Vision AI. Ecco un esempio di codice.
Discrepanze note tra la risposta dell'API Vision AI e la risposta e il convertitore dell'API Document AI:
Esempi di codice
I seguenti esempi di codice mostrano come inviare una richiesta di elaborazione che attiva le configurazioni e i componenti aggiuntivi OCR, quindi leggere e stampare i campi nel terminale:
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
† Questi contenuti possono essere specificati anche utilizzando contenuti codificati in base64 nell'oggetto
inlineDocument.
Metodo HTTP e URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corpo JSON della richiesta:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Se la richiesta riesce, il server restituisce un codice di stato HTTP 200 OK e la risposta in formato JSON. Il corpo della risposta contiene un'istanza di
Document.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.