Derived field and signature detection
The public preview derived fields feature enables Document AI customers to configure a field to be populated through intelligent inference or generation based on document context, rather than direct text extraction.
This release also adds another feature to detect the presence of signatures in
documents. You can use the new signature entity type to specify a schema for
such entities. The signature entities are derived using visual cues from the
document.
Derived fields in the custom extractor
Custom extractor supports derived fields in the following models:
pretrained-foundation-model-v1.4-2025-02-05as General Availability (GA)pretrained-foundation-model-v1.5-2025-05-05as Previewpretrained-foundation-model-v1.5-pro-2025-06-20as Preview
You can enable these features in the console UI when creating or editing labels in your document schema.
Derived Fields is a powerful feature that lets you extract information that isn't explicitly written in a document. This lets you configure a field to be populated through intelligent inference or generation based on the document's overall context. This goes beyond rudimentary text extraction and supports advanced use cases, such as:
- Deducing the country from an address.
- Counting the total number of items in a table.
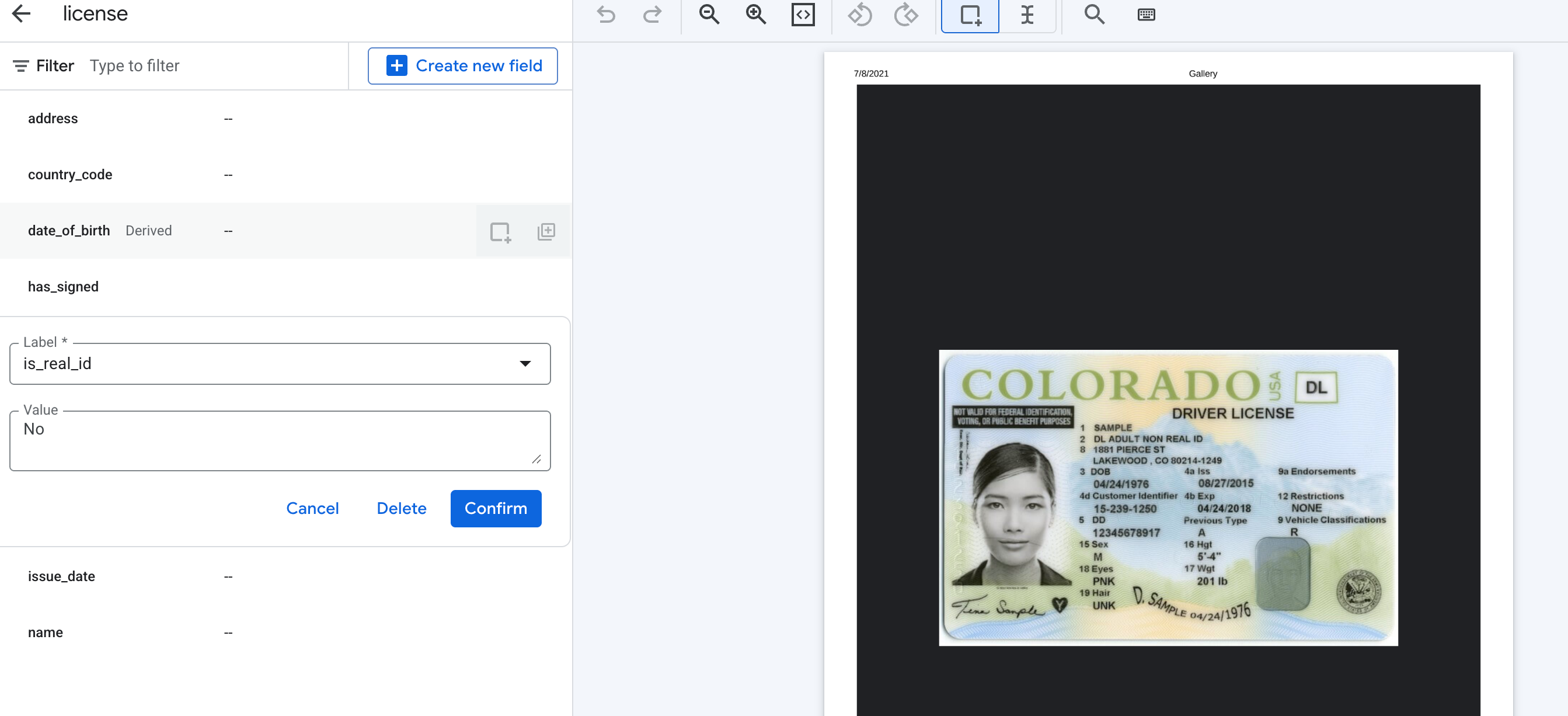
- Detecting if an ID card is a "Real ID".
Schema creation example
Here is an example of creating a schema for derived fields for such use cases and the expected output, using a US driver's license.
Select the
Derivedmethod when creating a schema element.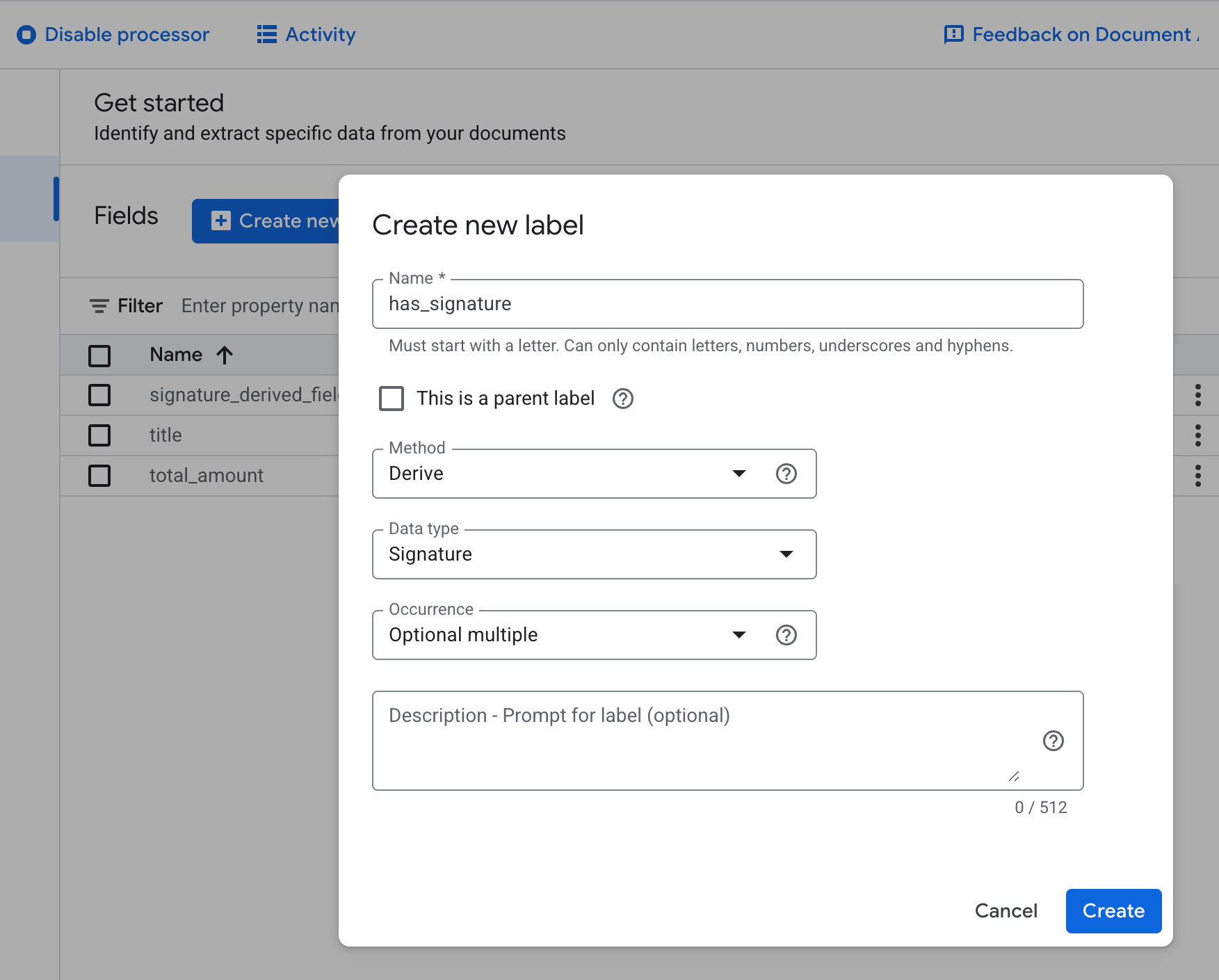
Add descriptive labels to improve performance.
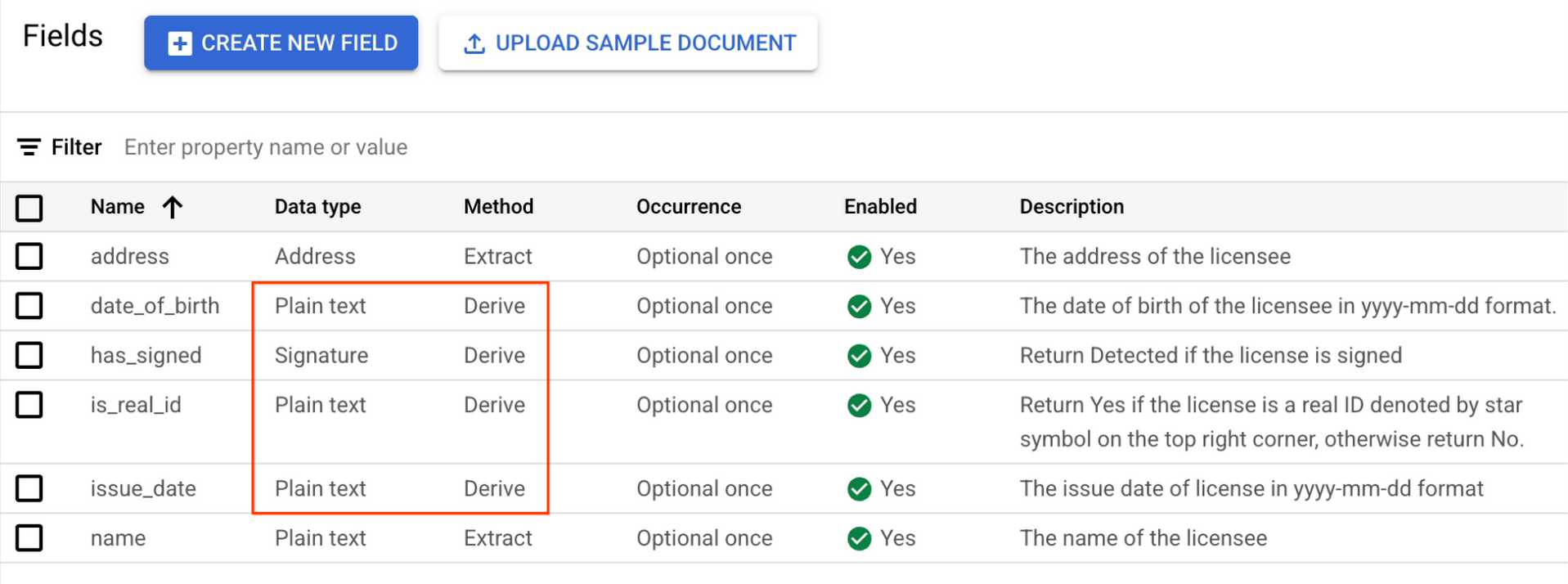
Derived fields such as signatures don't require setting bounding boxes when labeling documents. For Value, select Detected.
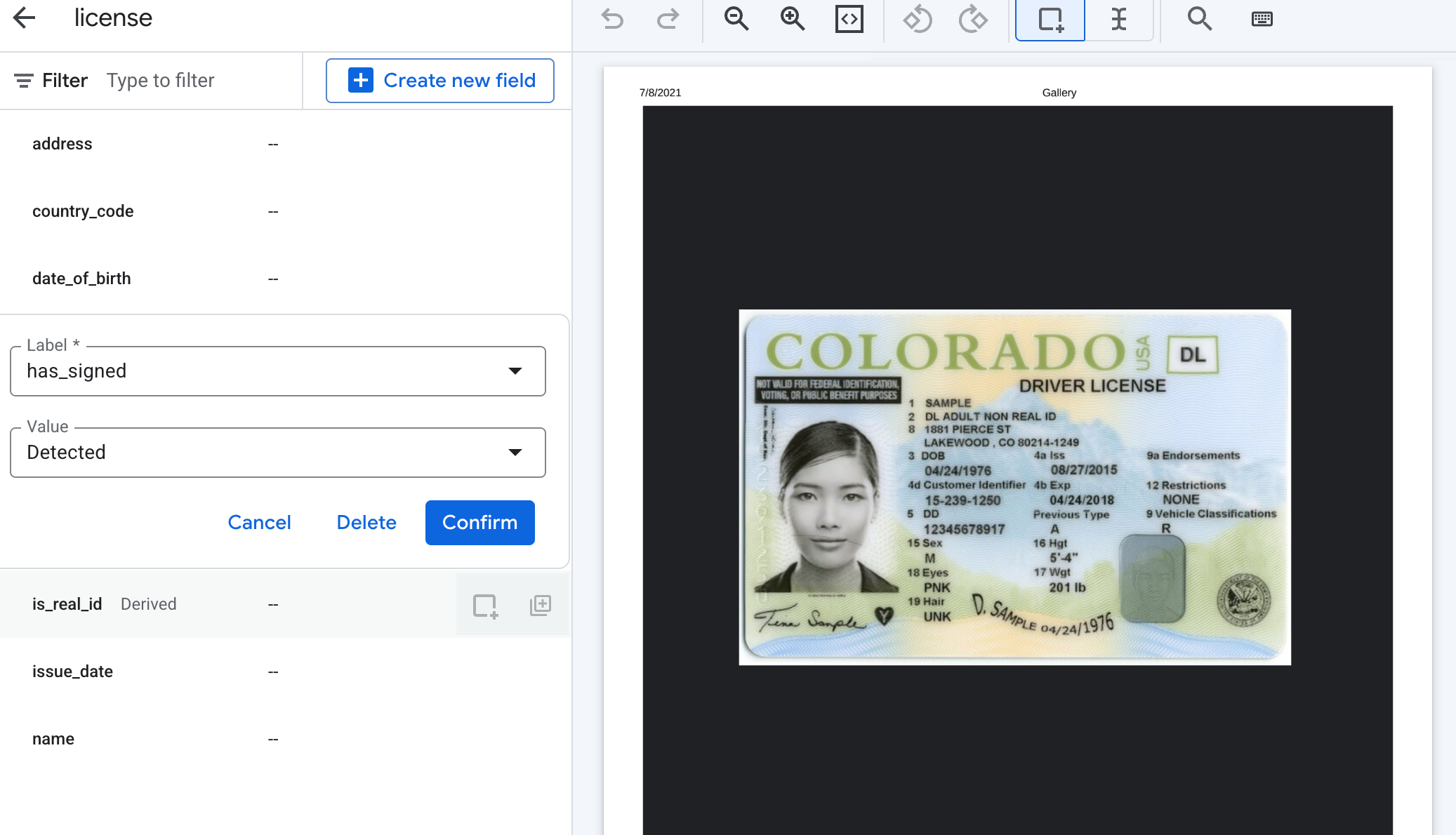
For derived fields other than signatures, you can enter any Value as part of labeling to define the possible outputs.
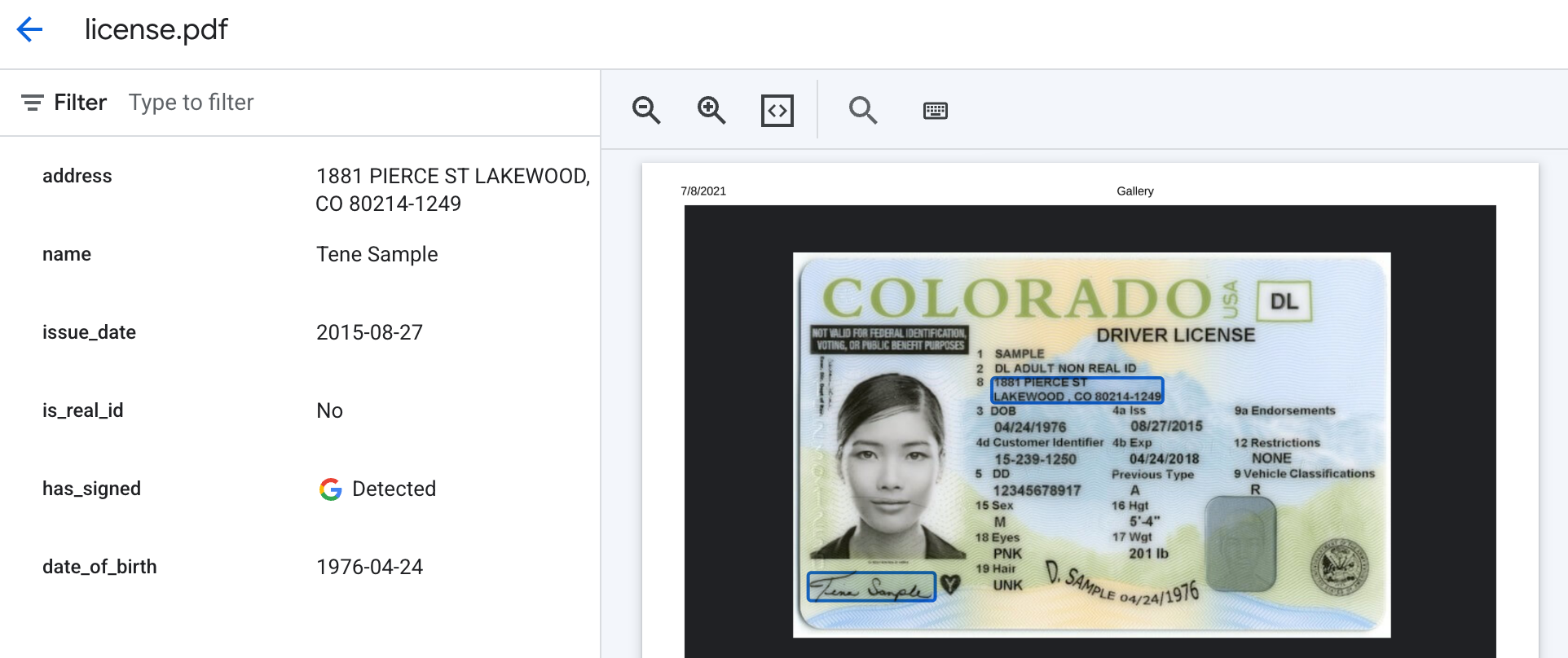
The expected output will look similar to this, with the presence of a signature returned as "Detected" or "", and derived fields returned as text as the label's description prompts request.
Extract versus derived overview
When you define an entity in your processor schema, you can choose a method for how its value is populated.
Extract: This is the default method. It works when the entity's value should be extracted directly from the document text. The system identifies the text and populates fields like
textAnchorandpageAnchorto show its location.Derived: This method is used when the entity's value needs to be inferred from the document's content. Since the value is not directly present in the text, the
textAnchorandpageAnchorfields aren't populated.
Example use case: finding a currency code
Imagine you need to identify the currency code (for example, USD, CAD, EUR) for transactions in your documents.
When to use
Extract: If the documents consistently contain unambiguous currency symbols or codes like "USD" or "€", use theExtractmethod to find and extract that exact text.When to use
Derived: If a document uses an ambiguous symbol like "$" (which could refer to USD, CAD, AUD, etc.) or has no symbol at all, use theDerivedmethod. The model analyzes the document's context—such as a billing address or company location—to infer the correct ISO 4217 currency code.
Configuration best practices
To get the best results with derived fields, we strongly recommend that you
write a clear, instructional description for the property in your schema
during labeling. This helps to guide the
model in its derivation task.
In the currency code example, you can create a field with the name
currency_code and provide the following description: "Find the ISO 4217
currency code of the amount values in the document, using contextual signals
present in the document, like currency symbols and addresses."
Limitations
Derived fields are generated on a per-page basis. This means that use cases requiring information from across multiple pages are not fully supported. For example, if you configure a derived field to summarize a document, it generates a separate summary for each individual page rather than one cohesive summary for the entire document. This limitation applies to any field where the value must be derived using cross-page information.
Signature detection in custom extractor
Document AI's custom extractor supports signature detection in custom
extractor models pretrained-foundation-model-v1.4-2025-02-05 and
pretrained-foundation-model-v1.5-2025-05-05. You can enable this feature in
the console UI when creating or editing labels in your document schema.
Signature detection is a feature that lets you determine if a signature is present in your documents. This feature verifies that a signature exists by analyzing visual cues, rather than extracting text.
How signature detection works
To enable this functionality, a signature data type is available when
defining your processor schema. The processor's behavior depends on whether a
signature is detected in the document.
If a signature is found, the extractor returns a signature entity in its response.
For a field named has_signed, the response object has the following structure:
"has_signed": {
"mention_text": "Detected",
"confidence": <confidence_score_between 0 to 1>,
"normalized_value": {
"text": "Detected",
"signature_value": true
}
}
If a signature isn't found, the entity isn't returned in the processor's response.
Configure and set up key requirements
To set up signature detection:
- Define the schema: In your processor schema, add a new entity for the signature you want to detect.
- Set data type: Select Signature as the data type for this new entity.
- Set method to derived: Entities with the
signaturedata type can only use theDerivedmethod. Because the model infers the signature's presence visually, it doesn't extract a text value. Therefore, fields liketextAnchorandpageAnchoraren't populated for signature entities.
Example use case
Imagine you are processing contracts and need to verify that they have been signed.
You can create a schema field named is_contract_signed and set its data type to
signature. When you process a signed contract, the response includes an
is_contract_signed entity, confirming the signature's presence. If no signature
is present, this entity is absent from the response. This lets you quickly flag
unsigned documents for review.
What's next
Learn about uptraining a specialized processor.