A labeled dataset of documents is required to train, up-train, or evaluate a processor version.
This page describes how to apply labels from your processor schema to imported documents in your dataset.
This page assumes you have already created a processor that supports training, up-training, or evaluation. If your processor is supported, you now see the Train tab in the Google Cloud console. It also assumes you have created a dataset, imported documents, and defined a processor schema.
Name fields for generative AI extraction
The way fields are named influences how accurately fields are extracted using generative AI. We recommend the following best practices when naming fields:
Name the field with the same language used to describe it in the document: For example, if a document has a field described as
Employer Address, then name the fieldemployer_address. Don't use abbreviations such asemplr_addr.Spaces are currently not supported in field names: Instead of using spaces, use
_. For example:First Namewould be namedfirst_name.Iterate on names to improve accuracy: Document AI has a limitation that does not allow field names to change. To test different names, use the renaming entity name tool to update the old entity's name with a newer one in the dataset, import the dataset, enable the new entities in the processor, and disable or delete the existing fields.
Zero-shot and few-shot learning
Models with Gemini have zero-shot and few-shot learning, which can create high-performing models with little to no training data.
Zero-shot learning is a machine learning example where a pre-trained model without any up-training learns to recognize and classify classes and entities which it hasn't encountered before during testing.
Few-shot learning is a where a model learns to recognize and classify new classes and entities with only a few training examples per class. It leverages knowledge from pre-trained models on large, well-labeled datasets to improve performance on few-shot tasks.
Few-shot becomes more effective when the training dataset is tidy and carefully labeled. Typically, this means having at least 10 testing and 10 training examples available for the model to learn from.
Labeling options
Here are your options for labeling documents:
Manual: manually label your documents in the Google Cloud console
Auto-labeling: use an existing processor version to generate labels
Import pre-labeled documents: save time if you already have labeled documents
Manually label in the Google Cloud console
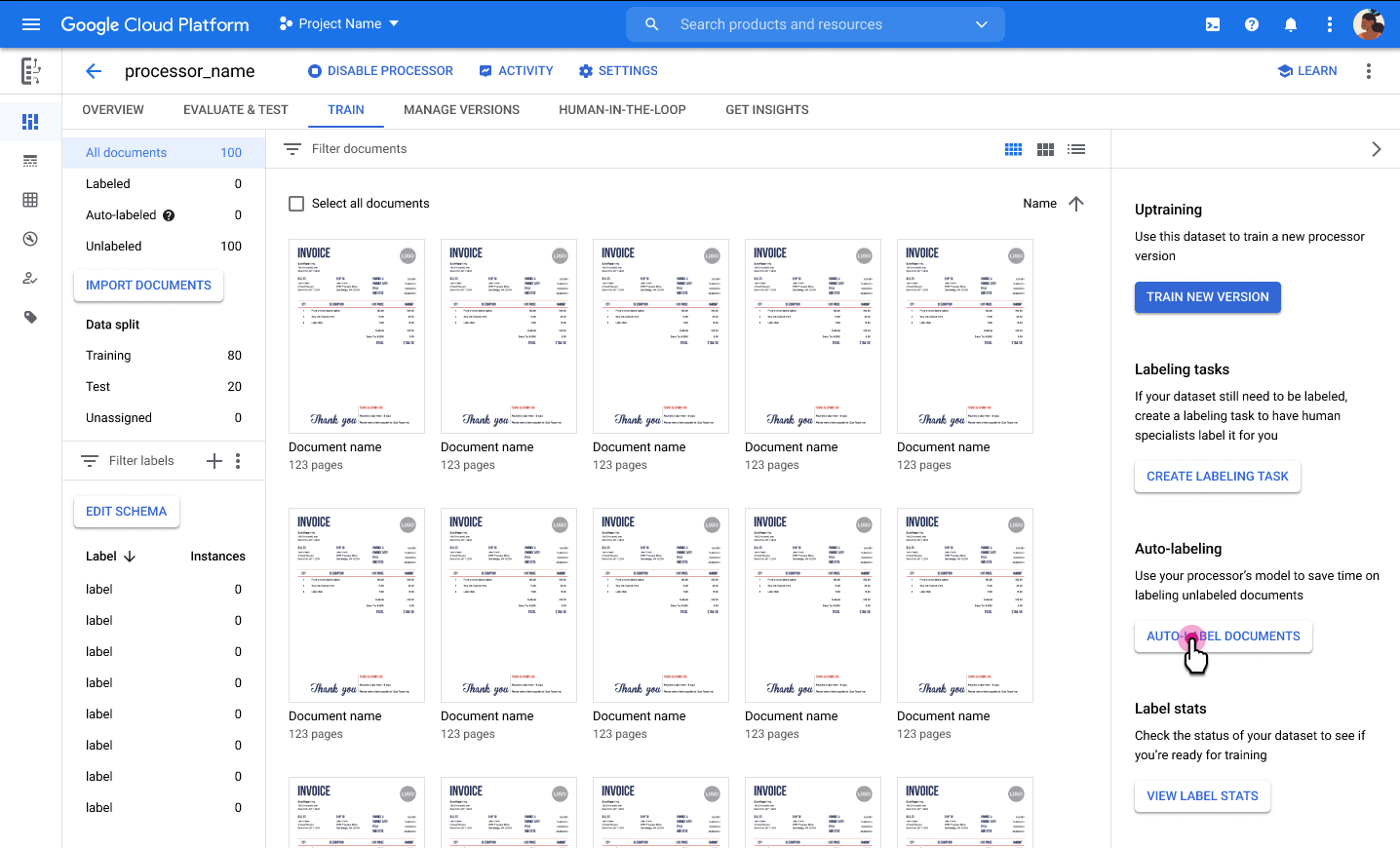
In the Train tab, select a document to open the labeling tool.
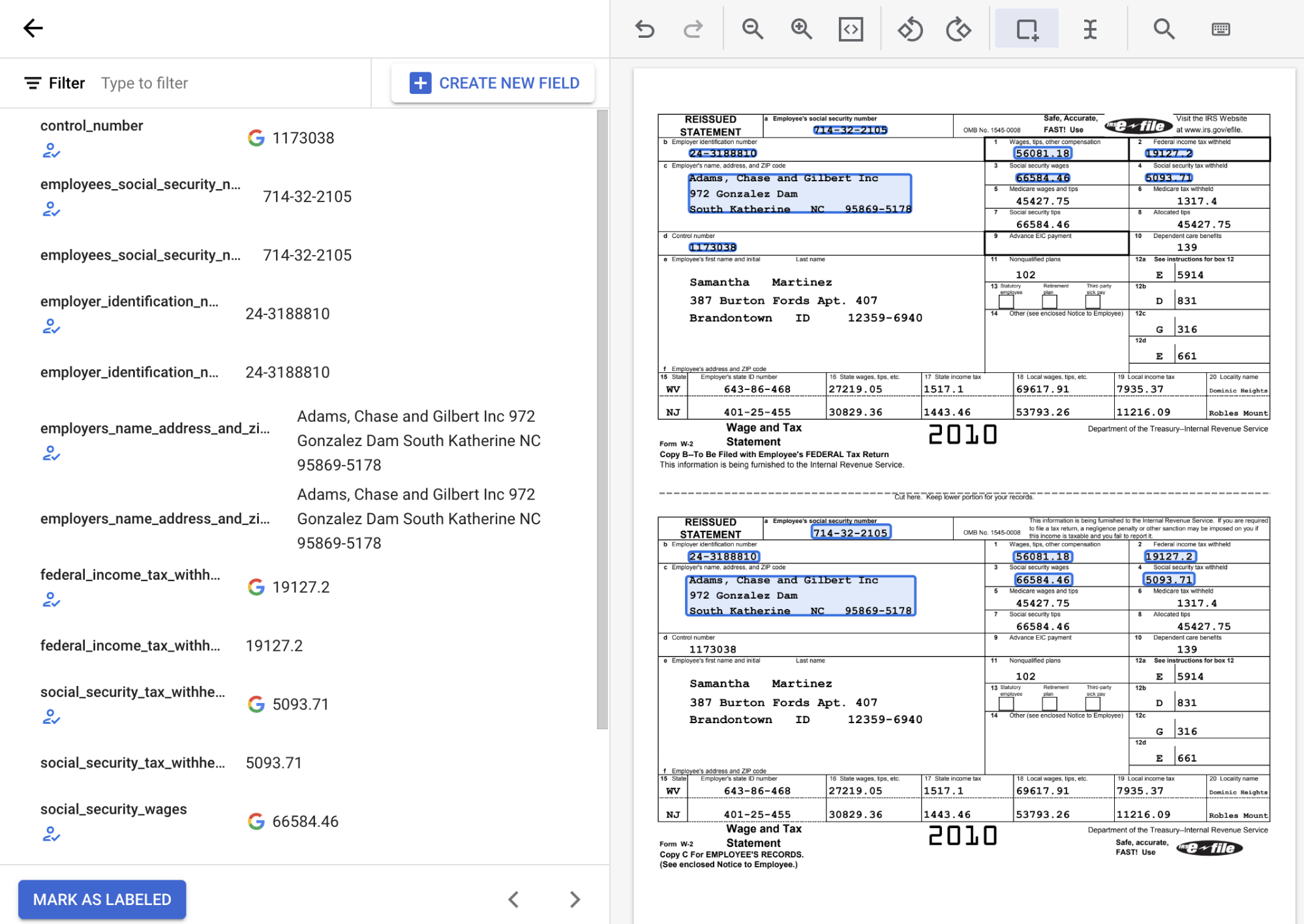
From the list of schema labels on the left side of the labeling tool, select the 'Add' symbol to select the Bounding box tool to highlight entities in the document and assign them to a label.
In the following screenshot, the EMPL_SSN EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS,
FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES, and WAGES_TIPS_OTHER_COMP
fields in the document have been assigned labels.
When you select a checkbox entity with the Bounding box tool, only select the checkbox itself, and not any associated text. Ensure that the checkbox entity shown on the left is either selected or deselected to match what is in the document.

When you label parent-child entities, don't label the parent entities. The parent entities are just containers of the child entities. Only label the child entities. The parent entities are updated automatically.
When you label child entities, label the first child entity and then associate the related child entities with that line. You notice this at the second child entity the first time you label such entities. For example, with an invoice, if you label description, it seem like any other entity. However, if you label quantity next, you are prompted to pick the parent.
Repeat this step for each line item by selecting New Parent Entity for each new line item.
Parent-child entities are supported for tables with up to three layers of nesting. Foundation models support three tiers of fields (grandparent, parent, child), so child entities can have one level of children. To learn more about nesting, refer to Three-level nesting.
Quick tables
When labeling a table, it could be tedious to label each row over and over again. There is a very convenient tool that can replicate a row entity structure. Note that, this feature only works on horizontally aligned rows.
- First, label the first row as usual.
Then, hold the pointer over the parent entity representing the row. Select Add more rows. The row becomes a template to create more rows.
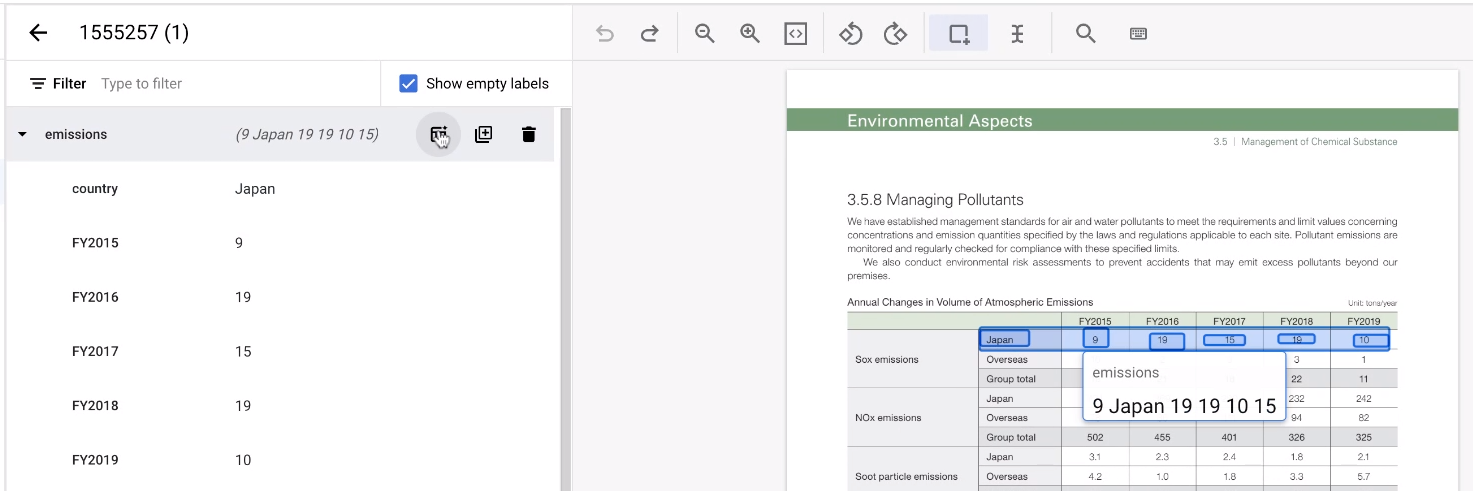
Select the rest of the area of the table.
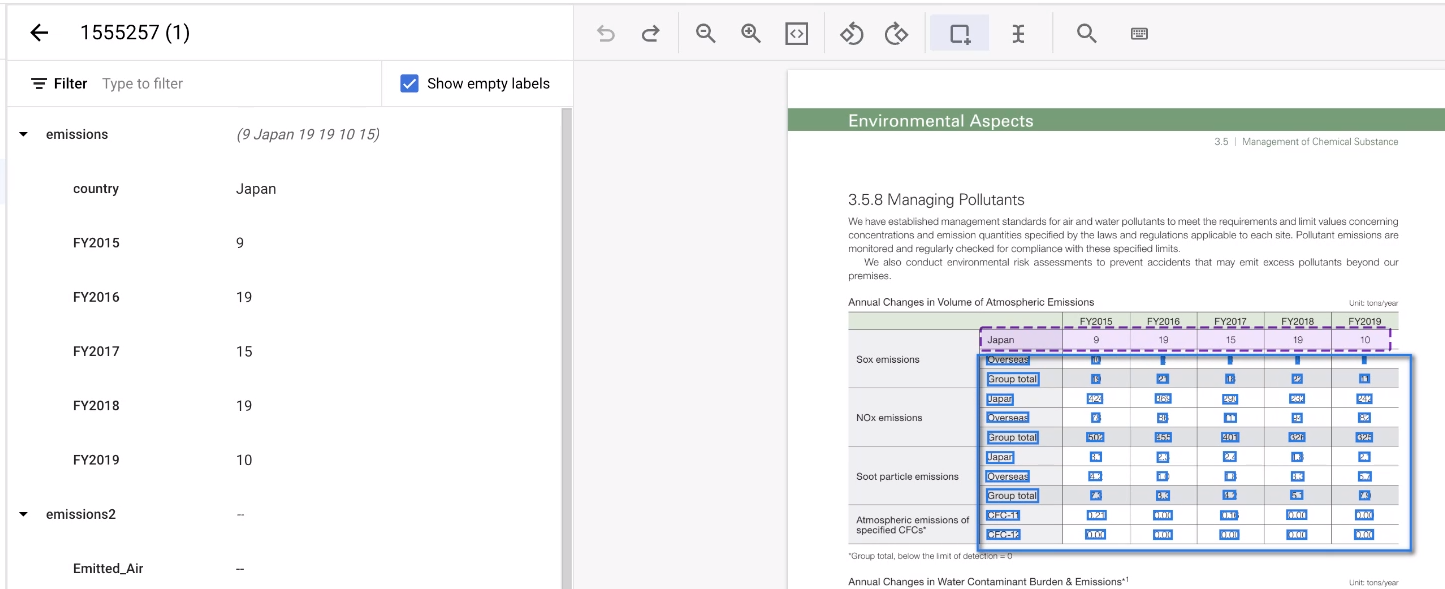
The tool guesses the annotations, and it usually works. For any tables it can't handle, annotate those manually.
Use keyboard shortcuts in console
To see the keyboard shortcuts that are available, select the menu at the upper right of the labeling console. It displays a list of keyboard shortcuts, as shown in the following table.
| Action | Shortcut |
|---|---|
| Zoom in | Alt + = (Option + = on macOS) |
| Zoom out | Alt + - (Option + - on macOS) |
| Zoom to fit | Alt + 0 (Option + 0 on macOS) |
| Scroll to zoom | Alt + Scroll (Option + Scroll on macOS) |
| Panning | Scroll |
| Reversed panning | Shift + Scroll |
| Drag to pan | Space + Mouse drag |
| Undo | Ctrl + Z (Control + Z on macOS) |
| Redo | Ctrl + Shift + Z (Control + +Shift + Z on macOS) |
Auto-label
If available, you can use an existing version of your processor to start labeling.
Auto-label can be initiated during import. All documents are annotated using the specified processor version.
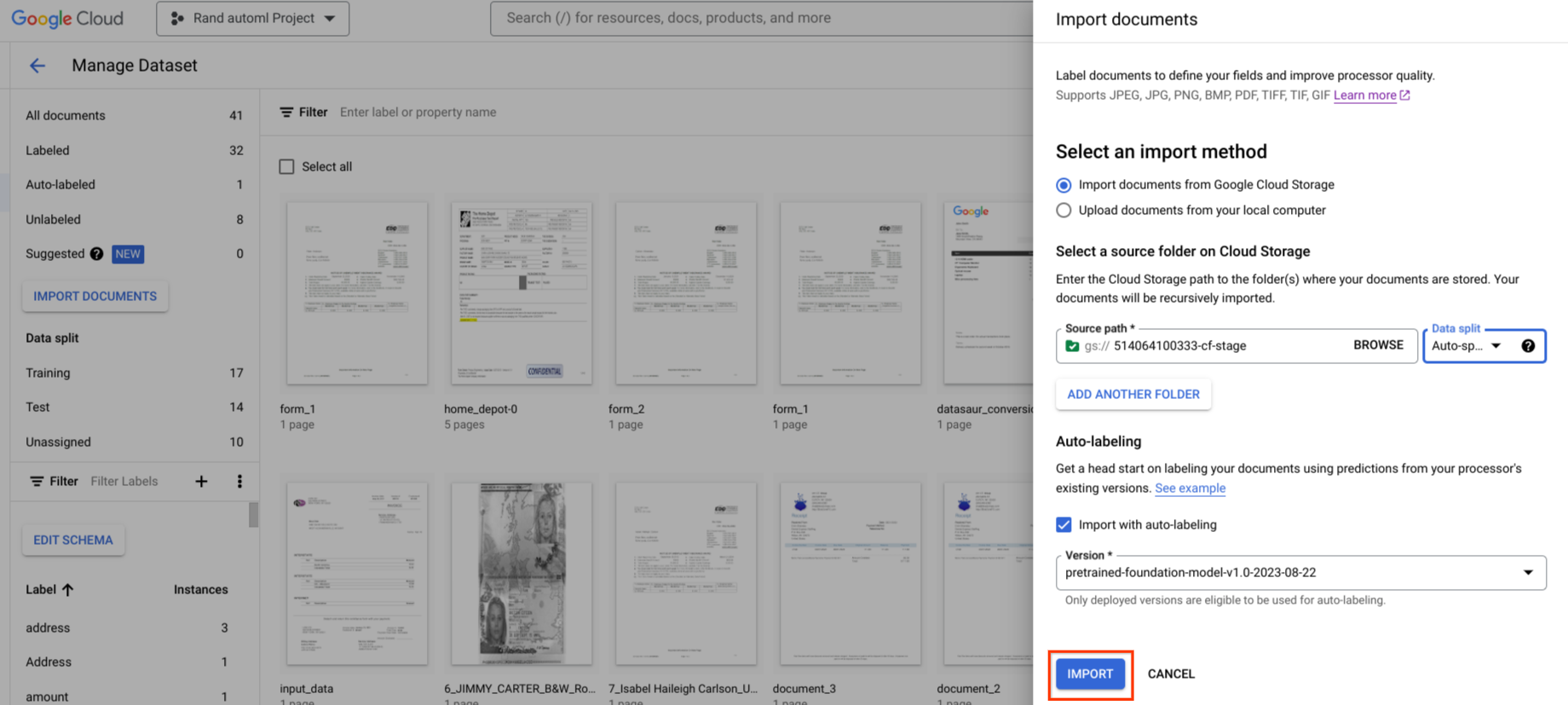
Auto-label can be initiated after import for documents in the unlabeled or auto-labeled category. All selected documents are annotated using the specified processor version.
You can't train or up-train on auto-labeled documents, or use them in the test set, without marking them as labeled. Manually review and correct the auto-labeled annotations, then select Mark as Labeled to save the corrections. You can then assign the documents as appropriate.
Import pre-labeled documents
You can import JSON Document
files. If the entity in the document matches the label in the processor
schema, the entity is converted to a label instance by the importer. There are
several ways you can get JSON Document files:
Exporting a dataset from another processor. See Export dataset.
Sending a processing request to an existing processor.
Use the import toolkit to convert existing labels from another system, for example, CSV format label to JSON documents.
Best practices for labeling documents
Consistent labeling is required to train a high quality processor. We recommend that you:
Create labeling instructions: Your instructions should include examples for both the common and corner cases. Some tips:
- Explain which fields should be annotated and how exactly to make labeling consistent. For example, when labeling "amount", specify whether the currency symbol should be labeled. If the labels are not consistent, then processor quality is reduced.
- Label all occurrences of an entity, even if the label type is
REQUIRED_ONCEorOPTIONAL_ONCE. For example, ifinvoice_idappears two times in the doc, label all occurrences of them. - Generally it is preferred to label with the default bounding box tool first. If that fails, then use the select text tool.
- If the value of the label is not correctly detected by OCR, don't manually correct the value. That would render it unusable for training purposes.
Here are some sample labeling instructions:
- Train annotators: make sure that annotators understand and can follow the guidelines without any systematic errors. One way to achieve this is to have different trainees annotate the same set of documents. The trainer can then check the quality of each trainee's annotation work. You might need to repeat this process until the trainees achieve a benchmark level of accuracy.
- Initial reviews: The first few (10 or so) documents labeled for a use case by a new labeler should be reviewed before large numbers of documents are labeled to prevent a large number of mistakes that need to be corrected.
- Annotation quality reviews: Given the laborious nature of annotation, even trained annotators may make mistakes. We recommend that annotations are checked by at least one more trained annotator.
Add a description prompt
When adding labels to the schema in custom extractor and custom classifier, you can add a description for the label. This helps train the processor by providing a prompt with which to identify the label. You can try slight variations to test response quality. For example, "total amount", "total invoice amount", or "total amount of invoice".
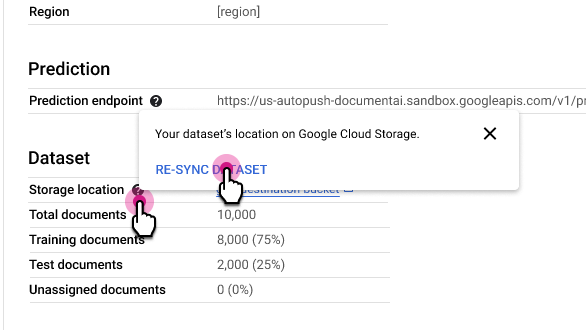
Resync dataset
Resync keeps your dataset's Cloud Storage folder consistent with Document AI's internal index of metadata. This is useful if you've accidentally made changes to the Cloud Storage folder and would like to synchronize the data.
To resync:
In the Processor Details tab, next to the Storage location row, select and then select Re-sync Dataset.
Usage notes:
- If you delete a document from the Cloud Storage folder, resync removes it from the dataset.
- If you add a document to the Cloud Storage folder, resync does not add it to the dataset. To add documents, import them.
- If you modify document labels in the Cloud Storage folder, resync updates the document labels in the dataset.
Migrate dataset
Import and export lets you move all the documents in a dataset from one processor to another. This can be useful if you have processors in different regions or Google Cloud projects, if you have different processors for staging and production, or for general offline consumption.
Note that only the documents and their labels are exported. Dataset metadata, such as processor schema, document assignments (training/test/unassigned), and document labeling status (labeled, unlabeled, auto-labeled) are not exported.
Copying and importing the dataset and then training the target processor is not
exactly the same as training the source processor. This is because random values are used
at the beginning of the training process. Use the importProcessorVersion API
call to import-migrate the exact same model between projects. This is best
practice for migration of processors to higher environments (for example development
to staging to production) if policies allow.
Export dataset
To export all documents as JSON
Document files to a Cloud Storage folder,
select Export Dataset.
A few important things to note:
During export, three sub-folders are created: Test, Train, and Unassigned. Your documents are placed into those sub-folders accordingly.
A document's labeling status is not exported. If you later import the documents, they won't be marked auto-labeled.
If your Cloud Storage is in a different Google Cloud project, make sure to grant access so that Document AI is allowed to write files to that location. Specifically, you must grant the Storage Object Creator role to Document AI's core service agent
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. For more information, see Service agents.
Import dataset
The procedure is the same as Import documents.
Selective labeling user guide
Selective labeling helps with recommendations on which documents to label. You can create diverse training and test datasets to train representative models. Each time selective labeling is performed, the most diverse (up to 30) documents from the dataset is selected.
Getting suggested documents
Create a CDE processor and import documents.
- At least 100 are required for training (25 for testing).
- Once sufficient documents are imported and after selective labeling, the information bar should appear.
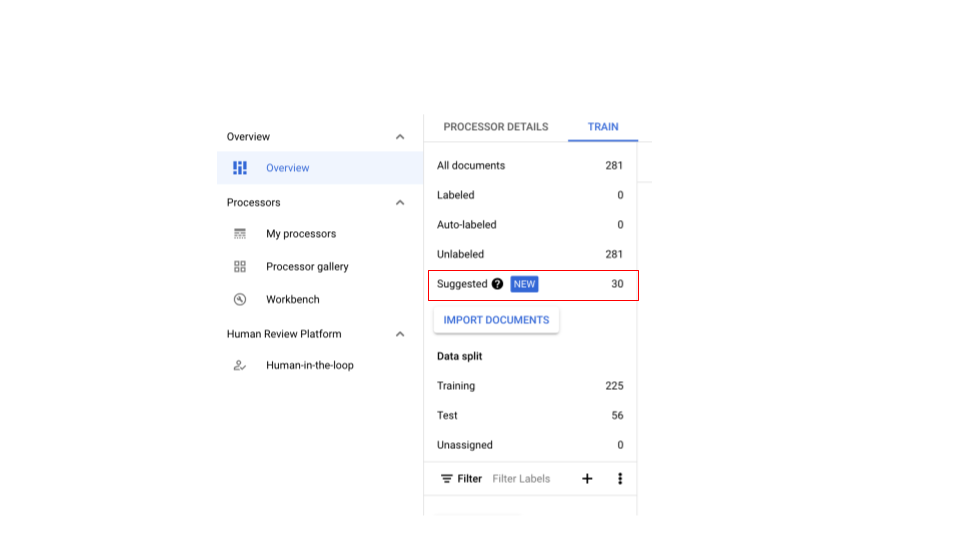
In case of a CDE processor with zero suggested documents, import more to have sufficient documents in either split for sampling.
- This should enable the suggested documents in Suggested category. You should be able to request suggested documents manually.
- There's a new filter on top to filter out suggested documents.
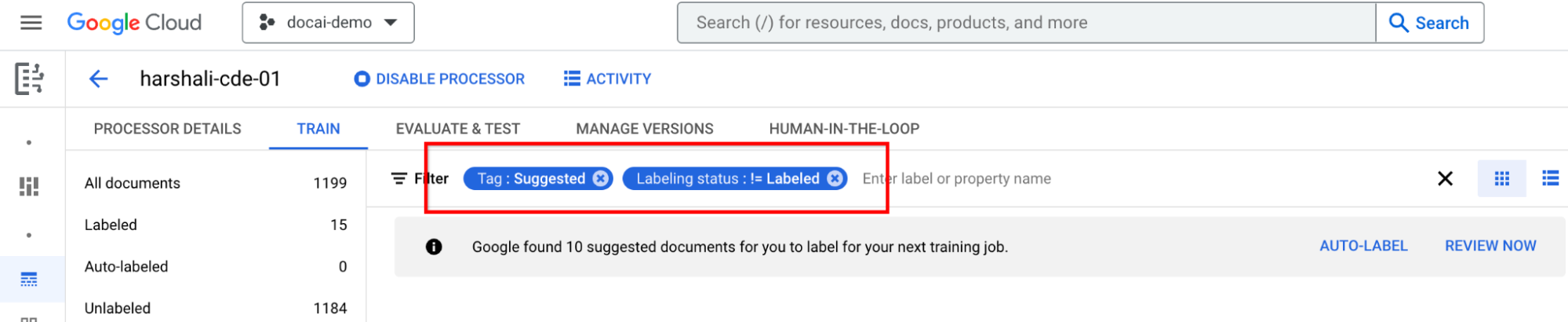
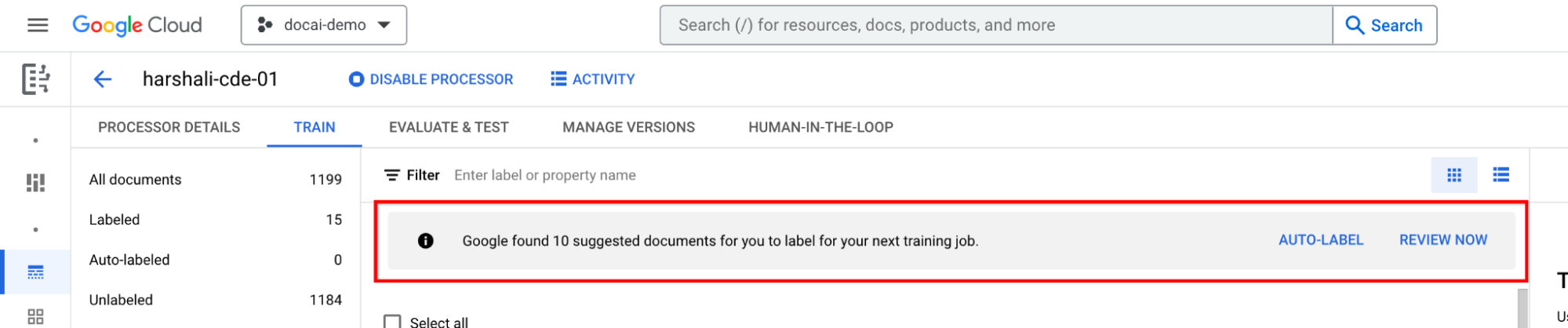
Label suggested documents
Go to Suggested category on the left-hand label list panel. Start labeling these documents.
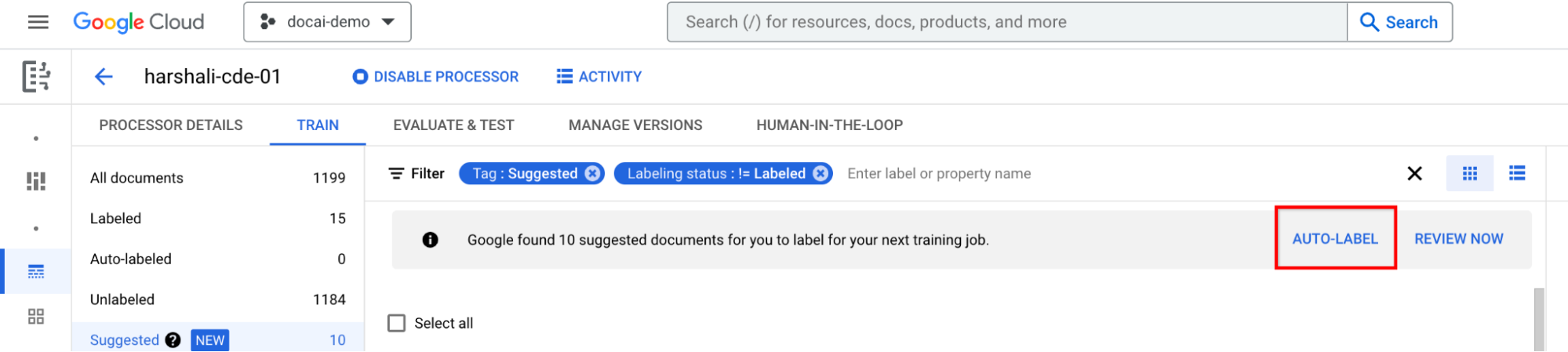
Select Auto-label on the information bar if the processor is trained. Label the suggested documents.
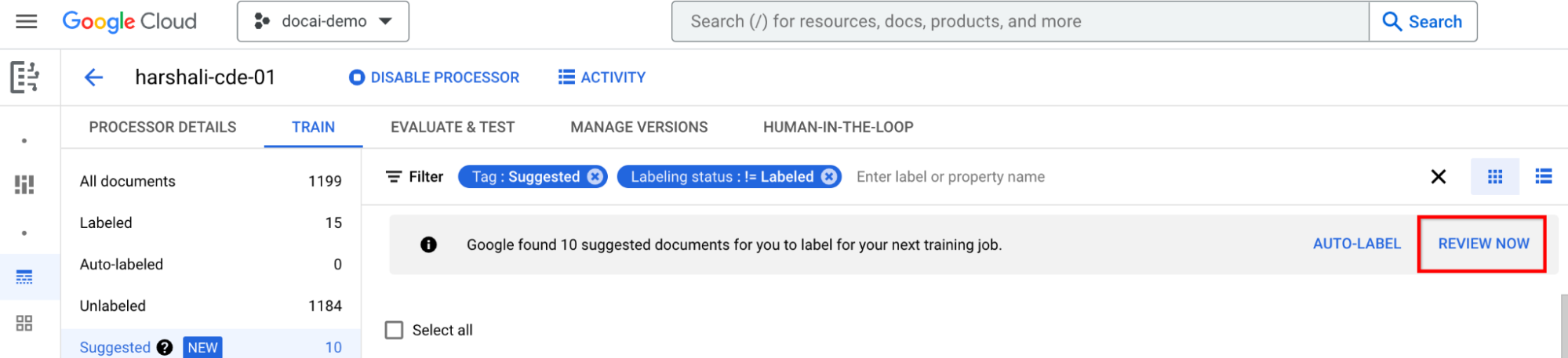
You can then select Review now on the bar when you have suggested documents in the processor to navigate to. All auto-labeled documents should be reviewed for accuracy. Start reviewing.
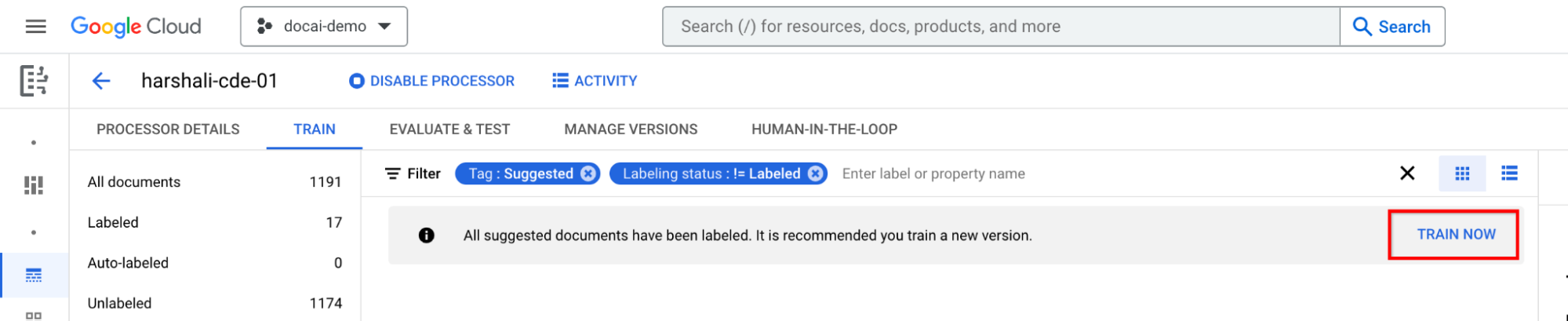
Train after labeling all suggested documents
Move to Train now on the information bar. When the suggested documents are labeled, you should see the following information bar recommending training.
Supported features and limitations
| Feature | Description | Supported |
|---|---|---|
| Support for old processors | Might not work well with old processors with previously imported dataset |