This document is a guide to the fundamental concepts of using Document AI. You should read this page before proceeding to any other documentation or quickstarts.
Automate document processing workflows
Businesses all over the world rely heavily on documents to store and convey information. This information often needs to be digitized for it to become useful. However, this is usually accomplished through time-intensive, manual processes.
For example:
- Digitizing books for e-readers.
- Processing medical intake forms at doctor's offices.
- Parsing receipts and invoices for expense report validation.
- Authenticating identity based on ID cards.
- Extracting income information from tax forms for approving loans.
- Understanding contracts for key business agreement terms.
Each of these workflows involve getting the raw text from documents, then extracting specific text from that which corresponds to the data needed (the fields or entities). However, each document type has a different structure and layout, and the pattern of fields vary depending on the specific use case.
Document AI components
Document AI is a document processing and understanding platform that takes unstructured data from documents and transforms it into structured data (specific fields, suitable for a database), making it easier to understand, analyze, and consume.
Document AI is built on top of products within Vertex AI with generative AI to help you create scalable, end-to-end, cloud-based document processing applications without specialized machine learning expertise.
Using Document AI, you can:
- Digitize documents using OCR to get text, layout, and various add ons such as image quality detection (for readability) and deskewing (fully automatic).
- Extract text and layout information, from document files and normalize entities.
- Identify key-value pairs (kvp) in structured forms and regular tables. For example:
Name: Jill Smithis a kvp. - Classify document types to drive downstream processes such as extraction and storage.
- Split and classify documents by type. For example, a PDF file with multiple real documents.
- Prepare datasets to be used in fine-tuning and model evaluations using auto-labeling, schema management, and dataset management features such as document and prediction review.
- Integrate it with products like Cloud Storage, BigQuery, and Vertex AI Search to help you store, search, organize, govern, and analyze documents and metadata.
This diagram illustrates all of the key document processing steps that are supported by Document AI and how they can connect to each other.
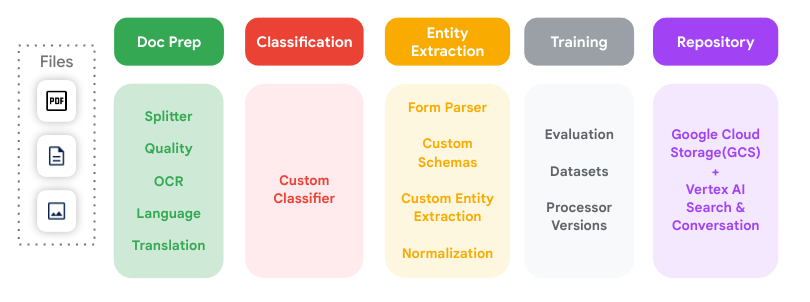
Processor
A Document AI processor lies between the document file and a machine learning model that performs document processing and understanding actions. They can be used to classify, split, parse, or analyze a document.
Each Google Cloud project needs to create its own processor instances.
Processors fit into one of the following categories:
- Digitize: OCR.
- Extract: Custom extractor, Form Parser, layout parser, and pretrained parsers.
- Classify: Custom classifier and custom splitter.
Refer to the Full processor and detail list for information about all available processor types for Document AI.
Which processor should I use?
To decide what processor type to use for a specific application, here are some general guidelines:
| Category | Use case | Processor type |
|---|---|---|
| Digitize | Extract text and layout information from documents. | Enterprise Document OCR |
| Analyze the scanned image quality (readability) of a document. | Enterprise Document OCR with image-quality analysis enabled | |
| Extract entities from a custom document that does not meet the custom processor criteria. | ||
| Extract | Extract tables or kvp from a structured form in a document. | Form Parser |
| Extract elements like text, tables, and lists in a document and return context aware chunks. | Layout Parser | |
| Extract entities from a custom document that meets the custom processor criteria. | Create a custom extractor | |
| Extract entities from a specialized document type. | A pretrained processor (Up-train to improve quality.) | |
| Classify | Classify documents. | Create a Custom Classifier |
| Split documents. | Create a Custom Splitter |
This diagram helps determine which processor works best for each use case.
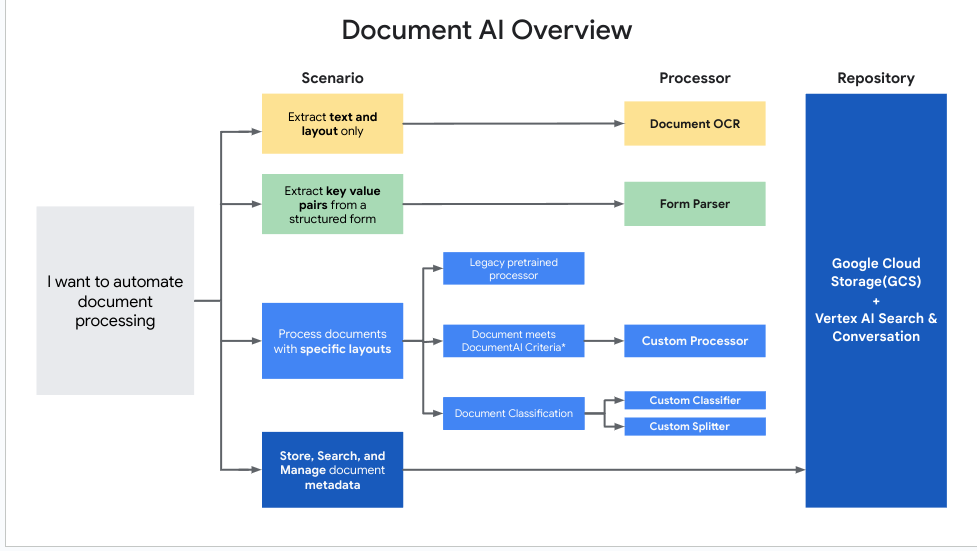
Use Document AI processors
Here are the major steps to use Document AI to start processing documents:
Choose a processor that is suitable for your use case.
- For complete information on each processor, see the Full processor and detail list.
Create a processor using the Google Cloud console or the Document AI API.
Document AI creates a prediction endpoint where you can send your documents.
For detailed instructions, see Creating a processor.
Train a processor with train and test data from scratch, or uptrain a new (pretrained) processor version on top of an existing one.
- For detailed instructions, see Train processor.
Send your documents for processing.
Document AI processes the documents and returns one or more
Documentobjects, which contain the extracted, structured information.For detailed instructions, see Sending a processing request and Handle the processing response.