Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Untuk banyak kolom spesifik yang didukung, Document AI juga menampilkan
entity.normalizedValue
selain kolom yang diekstrak mentah yang diperoleh melalui textAnchor setiap
entitas. Opsi ini menormalisasi teks literal. Normalisasi sering kali memecah nilai teks menjadi sub-kolom.
Ini berisi data dalam format standar untuk mengurangi pasca-pemrosesan, dan memungkinkan konversi ke format apa pun yang dipilih. mentionText, yang merepresentasikan apa yang ada di dokumen, tidak pernah diubah oleh normalisasi.
Kolom yang dinormalisasi termasuk dalam salah satu kategori berikut.
Nilai yang dinormalisasi di konsol
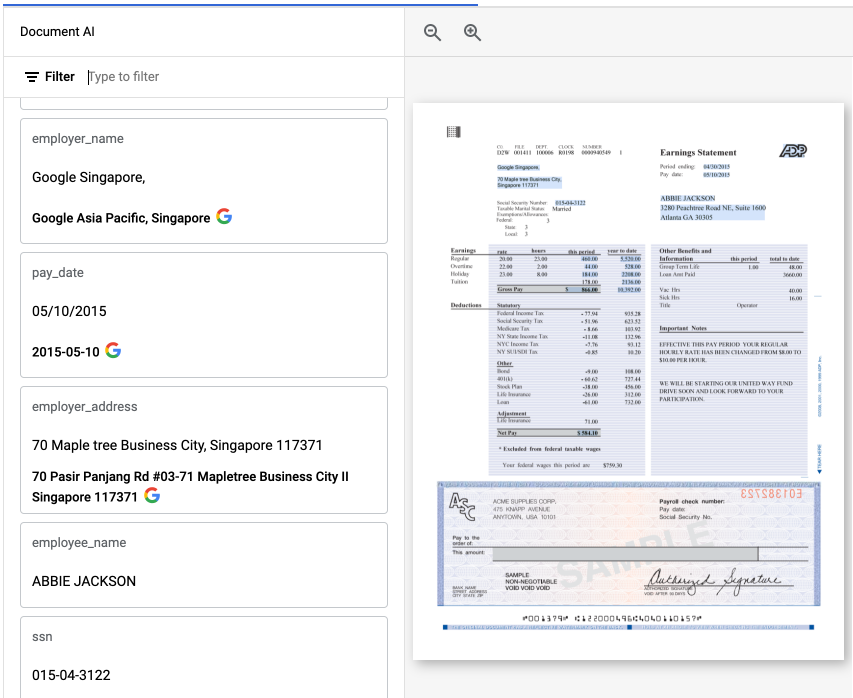
Di konsol Google Cloud , kolom yang dinormalisasi diberi anotasi G. Contoh:
Contoh kolom yang dinormalisasi yang ditampilkan di aplikasi web.
Prosesor yang didukung
Berikut adalah prosesor dan kolom yang mendukung pengayaan dan normalisasi entity:
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[[["\u003cp\u003eDocument AI provides \u003ccode\u003eentity.normalizedValue\u003c/code\u003e for supported fields, standardizing extracted data for easier post-processing and format conversion.\u003c/p\u003e\n"],["\u003cp\u003eNormalization breaks down text values into sub-fields while preserving the original \u003ccode\u003ementionText\u003c/code\u003e found on the document.\u003c/p\u003e\n"],["\u003cp\u003eSeveral pretrained processors, including Bank Statement, US Passport, Utility, Identity Document Proofing, Pay Slip, US Driver License, Expense, and Invoice Parsers, support entity normalization.\u003c/p\u003e\n"],["\u003cp\u003eCustom Extractor supports normalization for common data types such as \u003ccode\u003edateTime\u003c/code\u003e, \u003ccode\u003ecurrency\u003c/code\u003e, \u003ccode\u003emoney\u003c/code\u003e, and \u003ccode\u003enumber\u003c/code\u003e.\u003c/p\u003e\n"],["\u003cp\u003eNormalized fields are labeled with a \u003cstrong\u003eG\u003c/strong\u003e in the Google Cloud console for easy identification.\u003c/p\u003e\n"]]],[],null,["# Normalization\n=============\n\nFor many specific supported fields, Document AI also returns an\n[`entity.normalizedValue`](/document-ai/docs/reference/rest/v1/Document#normalizedvalue)\nin addition to the raw extracted field obtained through the `textAnchor` of each\nentity. It normalize the literal text. Normalization often breaks the text value\nup into sub-fields.\n\nThis contain the data in a standardized format to reduce post processing, and\nenable conversion to whatever format is selected. The `mentionText`, representing\nwhat is literally on the document, is never changed by normalization.\n\nNormalized fields belong to one of the following categories.\n\nNormalized values in the console\n--------------------------------\n\nIn the Google Cloud console, the normalized fields are annotated with **G**. For example:\nSample normalized field shown in the web application.\n\nSupported processors\n--------------------\n\nHere are the processors and fields that support entity enrichment and normalization: \n\n### Extraction processors\n\nCustom extractor supports normalization of all entities with the following Google Cloud\ncommon data types: [`dateTime`](/ruby/docs/reference/google-cloud-document_ai-v1/latest/Google-Type-DateTime), `currency`, [`money`](/ruby/docs/reference/google-cloud-document_ai-v1/latest/Google-Type-Money),\nand `number`."]]