Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Pengayaan
Document AI menggunakan Enterprise Knowledge Graph untuk menormalisasi dan
memperkaya hasil ekstraksi entitas (untuk kolom yang didukung). Misalnya, alamat
123 Main St Apt 1 dan 123 Main street # 1 dapat dinormalisasi ke alamat standar
yang sama.
Untuk setiap kolom yang didukung, Document AI juga menampilkan normalizedValue
selain kolom mentah yang diekstrak, yang menormalisasi teks literal.
File ini berisi data dalam format standar untuk mengurangi pascapemrosesan.
Sebagian besar data termasuk dalam salah satu kategori berikut:
Uang
Tanggal
Stempel waktu
Alamat
Boolean
Bilangan bulat
Float
Contoh respons
Nilai yang diperkaya dapat ditemukan di kolom
entities.normalizedValue
seperti yang ditunjukkan dalam contoh yang terpotong berikut:
{"entities":[{"textAnchor":{"textSegments":[...],"content":"Google Singapore"},"type":"employer_name","mentionText":"Google Singapore","confidence":0.69933707,"pageAnchor":{"pageRefs":[{"boundingPoly":{"normalizedVertices":[...]}}]},"id":"9","normalizedValue":{"text":"Google Asia Pacific, Singapore"}}]}
Dalam contoh, employer_name asli "Google Singapore" telah
dinormalisasi menjadi "Google Asia Pacific, Singapore".
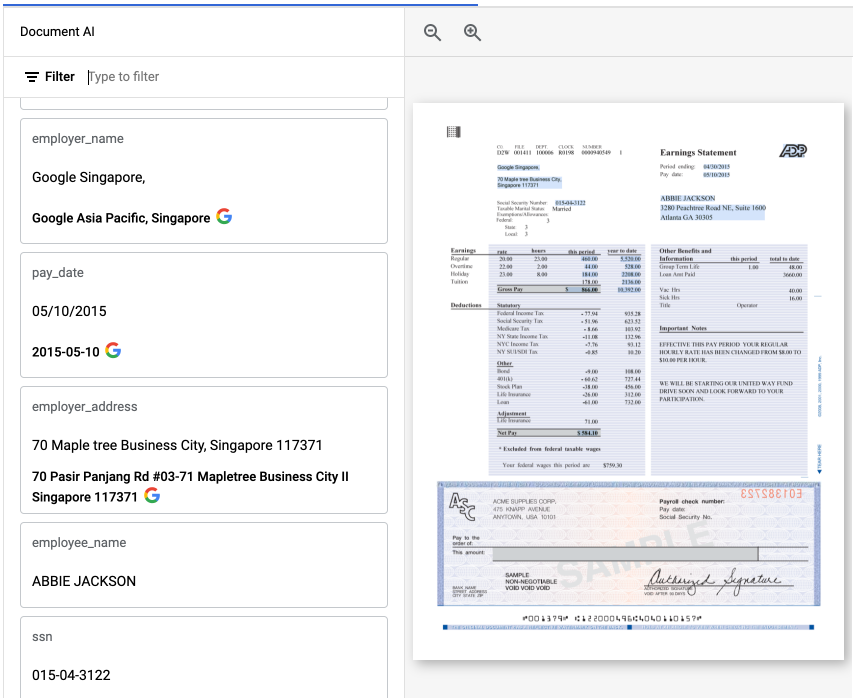
Di konsol Google Cloud , kolom yang diperkaya dan dinormalisasi dianotasi dengan G. Contoh:
Contoh kolom yang dinormalisasi yang ditampilkan di aplikasi web.
Prosesor yang didukung
Berikut adalah pemroses dan kolom yang mendukung pengayaan entitas.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-02 UTC."],[[["\u003cp\u003eDocument AI normalizes and enriches extracted entities using the Enterprise Knowledge Graph, standardizing variations of the same information, such as addresses.\u003c/p\u003e\n"],["\u003cp\u003eThe \u003ccode\u003enormalizedValue\u003c/code\u003e field in Document AI's response provides the standardized data format for supported fields, reducing the need for manual post-processing.\u003c/p\u003e\n"],["\u003cp\u003eEnriched values, which can be found in the \u003ccode\u003eentities.normalizedValue\u003c/code\u003e field, represent the original extracted text transformed into a standard format.\u003c/p\u003e\n"],["\u003cp\u003eEntity enrichment is available for specific fields in several processors, including Bank Statement Parser, W2 Parser, Pay Slip Parser, Expense Parser, and Invoice Parser.\u003c/p\u003e\n"],["\u003cp\u003eThe enriched field data is subject to change with new processor versions, so users should refer to the Document AI release notes for updates.\u003c/p\u003e\n"]]],[],null,["# Enrichment\n==========\n\nDocument AI uses [Enterprise Knowledge Graph](/enterprise-knowledge-graph/docs/overview) to normalize and\nenrich entity extraction results (for supported fields). For example, the addresses\n`123 Main St Apt 1` and `123 Main street # 1` could be normalized to the same\nstandardized address.\n\nFor each supported field, Document AI also returns a [`normalizedValue`](/document-ai/docs/reference/rest/v1/Document#normalizedvalue)\nin addition to the raw extracted field, normalizing the literal text.\nThis contains the data in a standardized format to reduce post-processing.\n\nMost data belongs to one of the following categories:\n\n- Money\n- Date\n- Timestamp\n- Address\n- Boolean\n- Integer\n- Float\n\nSample response\n---------------\n\nThe enriched values can be found in the\n[`entities.normalizedValue`](/document-ai/docs/reference/rest/v1/Document#NormalizedValue)\nfield as shown in the following truncated sample: \n\n {\n \"entities\": [\n {\n \"textAnchor\": {\n \"textSegments\": [ ... ],\n \"content\": \"Google Singapore\"\n },\n \"type\": \"employer_name\",\n \"mentionText\": \"Google Singapore\",\n \"confidence\": 0.69933707,\n \"pageAnchor\": {\n \"pageRefs\": [\n {\n \"boundingPoly\": {\n \"normalizedVertices\": [ ... ]\n }\n }\n ]\n },\n \"id\": \"9\",\n \"normalizedValue\": {\n \"text\": \"Google Asia Pacific, Singapore\"\n }\n }\n ]\n }\n\nIn the sample, the original `employer_name` \"Google Singapore\" has been\nnormalized to \"Google Asia Pacific, Singapore\".\n\nIn the Google Cloud console, the enriched and normalized fields are annotated with *G*. For example:\nSample normalized field shown in the web application.\n\nSupported processors\n--------------------\n\nHere are the processors and fields that support entity enrichment.\n**Note:** Enriched fields are subject to change with new processor versions. Follow the [Release notes](/document-ai/docs/release-notes) for Document AI updates."]]