Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
BigQuery terintegrasi dengan Document AI untuk membantu membangun analisis dokumen dan kasus penggunaan AI generatif. Seiring percepatan transformasi digital, organisasi menghasilkan sejumlah besar data teks dan dokumen lainnya, yang semuanya memiliki potensi besar untuk menghasilkan insight dan mendukung kasus penggunaan AI generatif baru. Untuk membantu memanfaatkan data ini, kami dengan senang hati mengumumkan integrasi antara BigQuery dan Document AI, yang memungkinkan Anda mengekstrak insight dari data dokumen dan membuat aplikasi model bahasa besar (LLM) baru.
Ringkasan
Pelanggan BigQuery kini dapat membuat pengekstrak kustom Document AI, yang didukung oleh model dasar canggih Google, yang dapat mereka sesuaikan berdasarkan dokumen dan metadata mereka sendiri. Model yang disesuaikan ini kemudian dapat dipanggil dari BigQuery untuk mengekstrak data terstruktur dari dokumen secara aman dan teratur, menggunakan kesederhanaan dan kecanggihan SQL.
Sebelum integrasi ini, beberapa pelanggan mencoba membuat pipeline Document AI independen, yang melibatkan kurasi logika dan skema ekstraksi secara manual. Kurangnya kemampuan integrasi bawaan membuat mereka harus mengembangkan infrastruktur khusus untuk menyinkronkan dan menjaga konsistensi data. Hal ini mengubah setiap project analisis dokumen menjadi tugas besar yang memerlukan investasi signifikan.
Sekarang, dengan integrasi ini, pelanggan dapat membuat model jarak jauh di BigQuery untuk ekstraktor kustom mereka di Document AI, dan menggunakannya untuk melakukan analisis dokumen dan AI generatif dalam skala besar, sehingga membuka era baru insight dan inovasi berbasis data.
Pengalaman data ke AI yang terpadu dan dikelola
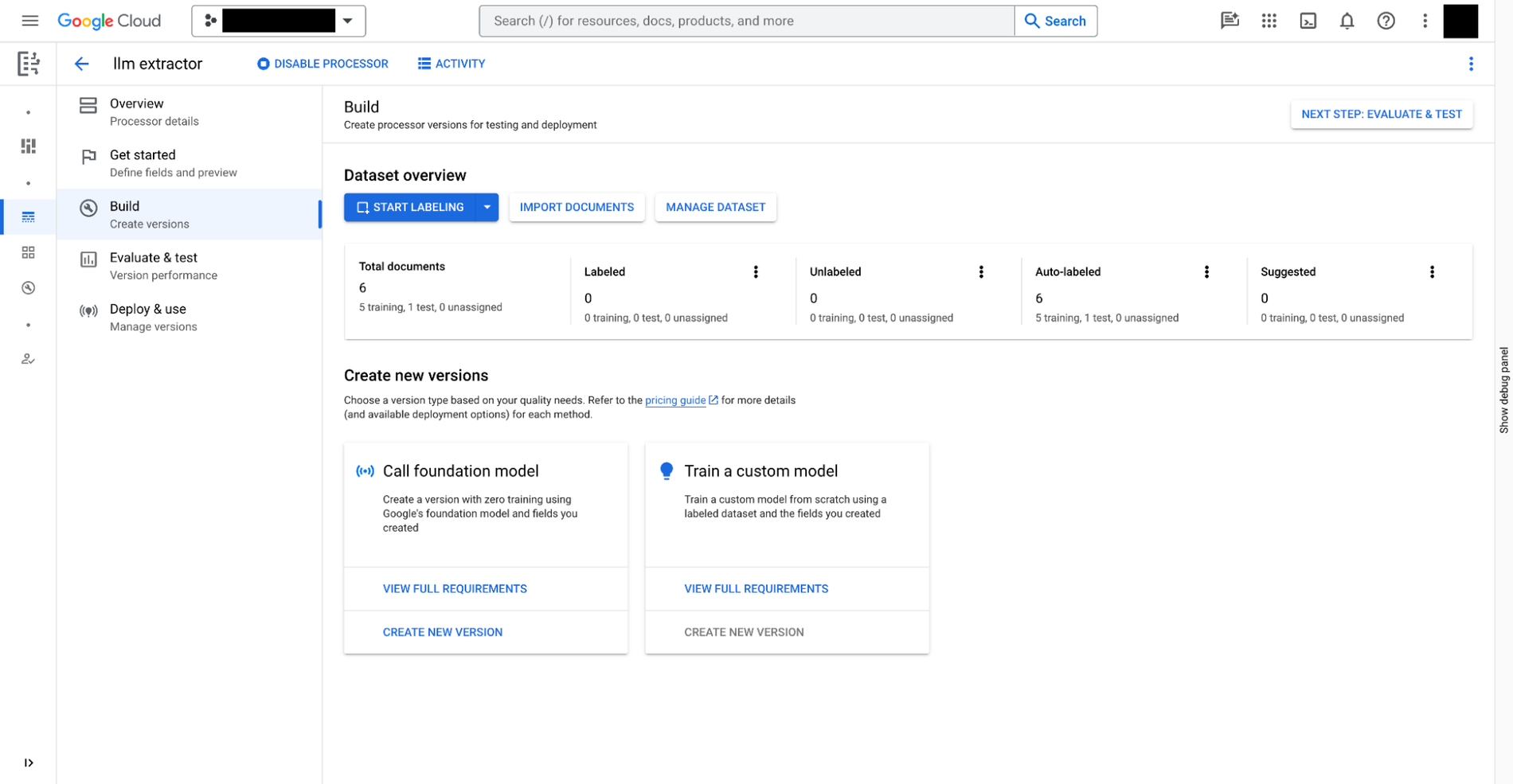
Anda dapat membuat ekstraktor kustom di Document AI dengan tiga langkah:
Tentukan data yang perlu diekstrak dari dokumen Anda. Hal ini disebut
document schema, disimpan dengan setiap versi ekstraktor kustom, dapat diakses dari BigQuery.
Jika perlu, berikan dokumen tambahan dengan anotasi sebagai contoh ekstraksi.
Latih model untuk pengekstraksi kustom, berdasarkan model dasar yang disediakan di Document AI.
Selain pengekstraksi kustom yang memerlukan pelatihan manual, Document AI juga menyediakan pengekstraksi siap pakai untuk pengeluaran, tanda terima, invoice, formulir pajak, tanda pengenal pemerintah, dan berbagai skenario lainnya, di galeri pemroses.
Kemudian, setelah pengekstraksi kustom siap, Anda dapat beralih ke BigQuery Studio untuk menganalisis dokumen menggunakan SQL dalam empat langkah berikut:
Daftarkan model jarak jauh BigQuery untuk ekstraktor menggunakan SQL. Model dapat
memahami skema dokumen (yang dibuat di atas), memanggil ekstraktor kustom,
dan mengurai hasilnya.
Buat tabel objek menggunakan SQL untuk dokumen yang disimpan di Cloud Storage. Anda
dapat mengatur data tidak terstruktur dalam tabel dengan menetapkan kebijakan akses tingkat baris,
yang membatasi akses pengguna ke dokumen tertentu dan dengan demikian membatasi kemampuan AI untuk
privasi dan keamanan.
Gunakan fungsi ML.PROCESS_DOCUMENT pada tabel objek untuk mengekstrak kolom yang relevan dengan melakukan panggilan inferensi ke endpoint API. Anda juga dapat memfilter dokumen untuk ekstraksi dengan klausa WHERE di luar fungsi.
Fungsi ini menampilkan tabel terstruktur, dengan setiap kolom adalah kolom yang diekstrak.
Gabungkan data yang diekstrak dengan tabel BigQuery lain untuk menggabungkan data terstruktur dan tidak terstruktur, sehingga menghasilkan nilai bisnis.
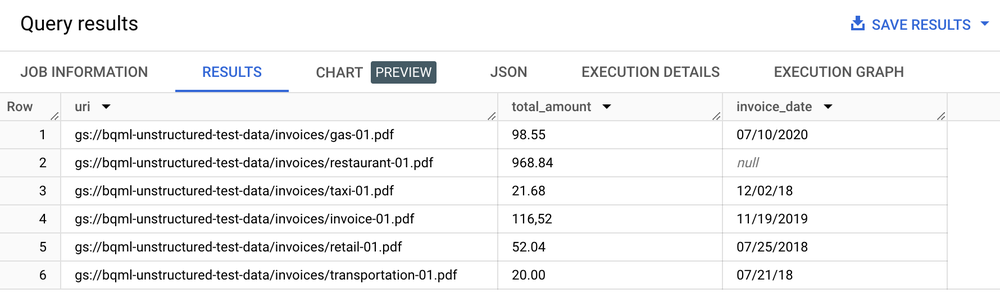
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.CREATEORREPLACEEXTERNALTABLE`my_dataset.document`WITHCONNECTION`my_project.us.example_connection`OPTIONS(object_metadata='SIMPLE',uris=['gs://my_bucket/path/*'],metadata_cache_mode='AUTOMATIC',max_staleness=INTERVAL1HOUR);# Create a remote model to register your Doc AI processor in BigQuery.CREATEORREPLACEMODEL`my_dataset.layout_parser`REMOTEWITHCONNECTION`my_project.us.example_connection`OPTIONS(remote_service_type='CLOUD_AI_DOCUMENT_V1',document_processor='PROCESSOR_ID');# Invoke the registered model over the object table to parse PDF documentSELECTuri,total_amount,invoice_dateFROMML.PROCESS_DOCUMENT(MODEL`my_dataset.layout_parser`,TABLE`my_dataset.document`,PROCESS_OPTIONS=> (JSON'{"layout_config": {"chunking_config": {"chunk_size": 250}}}'))WHEREcontent_type='application/pdf';
Tabel hasil
Analisis teks, pembuatan ringkasan, dan kasus penggunaan analisis dokumen lainnya
Setelah mengekstrak teks dari dokumen, Anda dapat melakukan analisis dokumen dengan beberapa cara:
Menggunakan BigQuery ML untuk melakukan analisis teks: BigQuery ML mendukung pelatihan dan deployment model sematan dengan berbagai cara. Misalnya, Anda dapat menggunakan BigQuery ML untuk mengidentifikasi sentimen pelanggan dalam panggilan dukungan, atau untuk mengklasifikasikan masukan produk ke dalam berbagai kategori. Jika Anda adalah pengguna Python, Anda juga dapat menggunakan BigQuery DataFrames
untuk pandas, dan API seperti scikit-learn untuk analisis teks pada data Anda.
Gunakan LLM text-embedding-004 untuk membuat embedding dari dokumen yang dipecah:
BigQuery memiliki fungsi ML.GENERATE_EMBEDDING yang memanggil model text-embedding-004 untuk membuat embedding. Misalnya, Anda dapat menggunakan Document AI untuk mengekstrak masukan pelanggan dan meringkas masukan tersebut menggunakan PaLM 2, semuanya dengan BigQuery SQL.
Gabungkan metadata dokumen dengan data terstruktur lainnya yang disimpan dalam tabel BigQuery:
Misalnya, Anda dapat membuat embedding menggunakan dokumen yang di-chunk dan menggunakannya untuk penelusuran vektor.
# Example 1: Parse the chunked dataCREATEORREPLACETABLEdocai_demo.demo_result_parsedAS(SELECTuri,JSON_EXTRACT_SCALAR(json,'$.chunkId')ASid,JSON_EXTRACT_SCALAR(json,'$.content')AScontent,JSON_EXTRACT_SCALAR(json,'$.pageFooters[0].text')ASpage_footers_text,JSON_EXTRACT_SCALAR(json,'$.pageSpan.pageStart')ASpage_span_start,JSON_EXTRACT_SCALAR(json,'$.pageSpan.pageEnd')ASpage_span_endFROMdocai_demo.demo_result,UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks,'$'))json)# Example 2: Generate embeddingCREATEORREPLACETABLE`docai_demo.embeddings`ASSELECT*FROMML.GENERATE_EMBEDDING(MODEL`docai_demo.embedding_model`,TABLE`docai_demo.demo_result_parsed`);
Menerapkan kasus penggunaan penelusuran dan AI generatif
Setelah mengekstrak teks terstruktur dari dokumen, Anda dapat membuat indeks yang dioptimalkan untuk kueri mencari jarum dalam tumpukan jerami, yang dimungkinkan oleh kemampuan penelusuran dan pengindeksan BigQuery, sehingga membuka kemampuan penelusuran yang canggih.
Integrasi ini juga membantu membuka aplikasi LLM generatif baru seperti menjalankan
pemrosesan file teks untuk pemfilteran privasi, pemeriksaan keamanan konten, dan pengelompokan token
menggunakan SQL dan model Document AI kustom. Teks yang diekstrak, yang digabungkan dengan metadata lain, menyederhanakan kurasi korpus pelatihan yang diperlukan untuk menyesuaikan model bahasa besar. Selain itu, Anda membangun kasus penggunaan LLM pada data perusahaan yang diatur dan telah dirujuk melalui kemampuan pembuatan embedding dan pengelolaan indeks vektor BigQuery. Dengan menyinkronkan indeks ini dengan Vertex AI, Anda dapat menerapkan kasus penggunaan retrieval-augmented generation, untuk pengalaman AI yang lebih teratur dan efisien.
Contoh aplikasi
Untuk contoh aplikasi end-to-end yang menggunakan Konektor Document AI:
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[[["\u003cp\u003eBigQuery now integrates with Document AI, enabling users to extract insights from document data and create new large language model (LLM) applications.\u003c/p\u003e\n"],["\u003cp\u003eCustomers can create custom extractors in Document AI, powered by Google's foundation models, and then invoke these models from BigQuery to extract structured data using SQL.\u003c/p\u003e\n"],["\u003cp\u003eThis integration simplifies document analytics projects by eliminating the need for manually building extraction logic and schemas, thus reducing the investment needed.\u003c/p\u003e\n"],["\u003cp\u003eBigQuery's \u003ccode\u003eML.PROCESS_DOCUMENT\u003c/code\u003e function, along with remote models, object tables, and SQL, facilitates the extraction of relevant fields from documents and the combination of this data with other structured data.\u003c/p\u003e\n"],["\u003cp\u003ePost-extraction, BigQuery ML and the \u003ccode\u003etext-embedding-004\u003c/code\u003e model can be leveraged for text analytics, generating embeddings, and building indexes for advanced search and generative AI applications.\u003c/p\u003e\n"]]],[],null,["# BigQuery integration\n====================\n\nBigQuery integrates with Document AI to help build document analytics and generative AI\nuse cases. As digital transformation accelerates, organizations are generating vast\namounts of text and other document data, all of which holds immense potential for\ninsights and powering novel generative AI use cases. To help harness this data,\nwe're excited to announce an integration between [BigQuery](/bigquery)\nand [Document AI](/document-ai), letting you extract insights from document data and build\nnew large language model (LLM) applications.\n\nOverview\n--------\n\nBigQuery customers can now create Document AI [custom extractors](/blog/products/ai-machine-learning/document-ai-workbench-custom-extractor-and-summarizer), powered by Google's\ncutting-edge foundation models, which they can customize based on their own documents\nand metadata. These customized models can then be invoked from BigQuery to\nextract structured data from documents in a secure, governed manner, using the\nsimplicity and power of SQL.\nPrior to this integration, some customers tried to construct independent Document AI\npipelines, which involved manually curating extraction logic and schema. The\nlack of built-in integration capabilities left them to develop bespoke infrastructure\nto synchronize and maintain data consistency. This turned each document analytics\nproject into a substantial undertaking that required significant investment.\nNow, with this integration, customers can create remote models in BigQuery\nfor their custom extractors in Document AI, and use them to perform document analytics\nand generative AI at scale, unlocking a new era of data-driven insights and innovation.\n\nA unified, governed data to AI experience\n-----------------------------------------\n\nYou can build a custom extractor in the Document AI with three steps:\n\n1. Define the data you need to extract from your documents. This is called `document schema`, stored with each version of the custom extractor, accessible from BigQuery.\n2. Optionally, provide extra documents with annotations as samples of the extraction.\n3. Train the model for the custom extractor, based on the foundation models provided in Document AI.\n\nIn addition to custom extractors that require manual training, Document AI also\nprovides ready to use extractors for expenses, receipts, invoices, tax forms,\ngovernment ids, and a multitude of other scenarios, in the processor gallery.\n\nThen, once you have the custom extractor ready, you can move to BigQuery Studio\nto analyze the documents using SQL in the following four steps:\n\n1. Register a BigQuery remote model for the extractor using SQL. The model can understand the document schema (created above), invoke the custom extractor, and parse the results.\n2. Create object tables using SQL for the documents stored in Cloud Storage. You can govern the unstructured data in the tables by setting row-level access policies, which limits users' access to certain documents and thus restricts the AI power for privacy and security.\n3. Use the function `ML.PROCESS_DOCUMENT` on the object table to extract relevant fields by making inference calls to the API endpoint. You can also filter out the documents for the extractions with a `WHERE` clause outside of the function. The function returns a structured table, with each column being an extracted field.\n4. Join the extracted data with other BigQuery tables to combine structured and unstructured data, producing business values.\n\nThe following example illustrates the user experience:\n\n # Create an object table in BigQuery that maps to the document files stored in Cloud Storage.\n CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`\n WITH CONNECTION `my_project.us.example_connection`\n OPTIONS (\n object_metadata = 'SIMPLE',\n uris = ['gs://my_bucket/path/*'],\n metadata_cache_mode= 'AUTOMATIC',\n max_staleness= INTERVAL 1 HOUR\n );\n\n # Create a remote model to register your Doc AI processor in BigQuery.\n CREATE OR REPLACE MODEL `my_dataset.layout_parser`\n REMOTE WITH CONNECTION `my_project.us.example_connection`\n OPTIONS (\n remote_service_type = 'CLOUD_AI_DOCUMENT_V1', \n document_processor='\u003cvar translate=\"no\"\u003ePROCESSOR_ID\u003c/var\u003e'\n );\n\n # Invoke the registered model over the object table to parse PDF document\n SELECT uri, total_amount, invoice_date\n FROM ML.PROCESS_DOCUMENT(\n MODEL `my_dataset.layout_parser`,\n TABLE `my_dataset.document`,\n PROCESS_OPTIONS =\u003e (\n JSON '{\"layout_config\": {\"chunking_config\": {\"chunk_size\": 250}}}')\n )\n WHERE content_type = 'application/pdf';\n\nTable of results\n\nText analytics, summarization and other document analysis use cases\n-------------------------------------------------------------------\n\nOnce you have extracted text from your documents, you can then perform document\nanalytics in a few ways:\n\n- Use BigQuery ML to perform text-analytics: BigQuery ML supports training and deploying embedding models in a variety of ways. For example, you can use BigQuery ML to identify customer sentiment in support calls, or to classify product feedback into different categories. If you are a Python user, you can also use BigQuery DataFrames for pandas, and scikit-learn-like APIs for text analysis on your data.\n- Use `text-embedding-004` LLM to generate embeddings from the chunked documents: BigQuery has a `ML.GENERATE_EMBEDDING` function that calls the `text-embedding-004` model to generate embeddings. For example, you can use a Document AI to extract customer feedback and summarize the feedback using PaLM 2, all with BigQuery SQL.\n- Join document metadata with other structured data stored in BigQuery tables:\n\nFor example, you can generate embeddings using the chunked documents and use it for vector search. \n\n # Example 1: Parse the chunked data\n\n CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT\n uri,\n JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,\n JSON_EXTRACT_SCALAR(json , '$.content') AS content,\n JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,\n JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,\n JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end\n FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)\n\n # Example 2: Generate embedding\n\n CREATE OR REPLACE TABLE `docai_demo.embeddings` AS\n SELECT * FROM ML.GENERATE_EMBEDDING(\n MODEL `docai_demo.embedding_model`,\n TABLE `docai_demo.demo_result_parsed`\n );\n\nImplement search and generative AI use cases\n--------------------------------------------\n\nOnce you've extracted structured text from your documents, you can build indexes\noptimized for needle in the haystack queries, made possible by BigQuery's search\nand indexing capabilities, unlocking powerful search capability.\nThis integration also helps unlock new generative LLM applications like executing\ntext-file processing for privacy filtering, content safety checks, and token chunking\nusing SQL and custom Document AI models. The extracted text, combined with other metadata,\nsimplifies the curation of the training corpus required to fine-tune large language\nmodels. Moreover, you're building LLM use cases on governed, enterprise data\nthat's been grounded through BigQuery's embedding generation and vector index\nmanagement capabilities. By synchronizing this index with Vertex AI, you can\nimplement retrieval-augmented generation use cases, for a more governed and\nstreamlined AI experience.\n\nSample application\n------------------\n\nFor an example of an end-to-end application using the Document AI Connector:\n\n- Refer to this expense report demo on [GitHub](https://github.com/GoogleCloudPlatform/smart-expenses).\n- Read the companion [blog post](/blog/topics/developers-practitioners/smarter-applications-document-ai-workflows-and-cloud-functions).\n- Watch a deep dive [video](https://www.youtube.com/watch?v=Bnac6JnBGQg&t=1s) from Google Cloud Next 2021."]]