Dataproc-Job- und -Clusterlogs können in Cloud Logging angesehen, durchsucht, gefiltert und archiviert werden.
Unter Google Cloud Observability-Preise finden Sie Informationen zu Ihren Kosten.
Unter Aufbewahrungsdauer von Logs finden Sie Informationen zur Logging-Aufbewahrung.
Unter Logausschlüsse finden Sie Informationen zum Deaktivieren aller Logs oder Ausschließen von Logs vom Logging.
Unter Übersicht: Routing und Speicher erfahren Sie, wie Sie Logs von Logging an Cloud Storage, BigQuery oder Pub/Sub weiterleiten.
Komponentenprotokollierungsebenen
Sie können die Protokollierungsebenen für Spark, Hadoop, Flink und andere Dataproc-Komponenten mit komponentenbezogenen Log4j-Clusterattributen wie hadoop-log4j festlegen, wenn Sie einen Cluster erstellen. Clusterbasierte Komponenten-Logging-Stufen gelten für Dienst-Daemons wie den YARN ResourceManager und für Jobs, die im Cluster ausgeführt werden.
Wenn log4j-Properties für eine Komponente wie die Presto-Komponente nicht unterstützt werden, schreiben Sie eine Initialisierungsaktion, mit der die log4j.properties- oder log4j2.properties-Datei der Komponente bearbeitet wird.
Jobspezifische Logging-Ebenen für Komponenten: Sie können auch Logging-Ebenen für Komponenten festlegen, wenn Sie einen Job senden. Diese Logging-Ebenen werden auf den Job angewendet und haben Vorrang vor den Logging-Ebenen, die beim Erstellen des Clusters festgelegt wurden. Weitere Informationen finden Sie unter Cluster- und Jobattribute.
Protokollierungsebenen für Spark- und Hive-Komponentenversionen:
Die Komponenten Spark 3.3.X und Hive 3.X verwenden log4j2-Properties, während frühere Versionen dieser Komponenten log4j-Properties verwenden (siehe Apache Log4j2).
Verwenden Sie das Präfix spark-log4j:, um die Spark-Logging-Ebenen für einen Cluster festzulegen.
Beispiel: Dataproc-Image-Version 2.0 mit Spark 3.1 zum Festlegen von
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Beispiel: Dataproc-Image-Version 2.1 mit Spark 3.3 zum Festlegen von
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Logebenen für Job-Treiber
Dataproc verwendet die standardmäßige Logging-Ebene INFO für Job-Treiberprogramme. Sie können diese Einstellung für ein oder mehrere Pakete mit dem Flag --driver-log-levels des Befehls gcloud dataproc jobs submit ändern.
Beispiel:
Legen Sie die Protokollierungsebene DEBUG fest, wenn Sie einen Spark-Job senden, der Cloud Storage-Dateien liest.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Beispiel:
Legen Sie die root-Logger-Ebene auf WARN und die com.example-Logger-Ebene auf INFO fest.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Logebenen für Spark-Ausführer
So konfigurieren Sie die Logebenen für Spark-Ausführer:
log4j-Konfigurationsdatei vorbereiten und in Cloud Storage hochladen
Verweisen Sie beim Senden des Jobs auf Ihre Konfigurationsdatei.
Beispiel:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark lädt die Cloud Storage-Eigenschaftendatei in das lokale Arbeitsverzeichnis des Jobs herunter, auf das in -Dlog4j.configuration als file:<name> verwiesen wird.
Dataproc-Joblogs in Logging
Informationen zum Aktivieren von Dataproc-Jobtreiberlogs in Logging finden Sie unter Dataproc-Jobausgabe und -Logs.
Auf Joblogs in Logging zugreifen
Sie können auf Dataproc-Joblogs mit dem Log-Explorer, dem Befehl „gcloud logging“ oder der Logging API zugreifen.
Console
Dataproc-Jobtreiber und YARN-Containerlogs werden unter der Ressource Cloud Dataproc-Job aufgelistet.
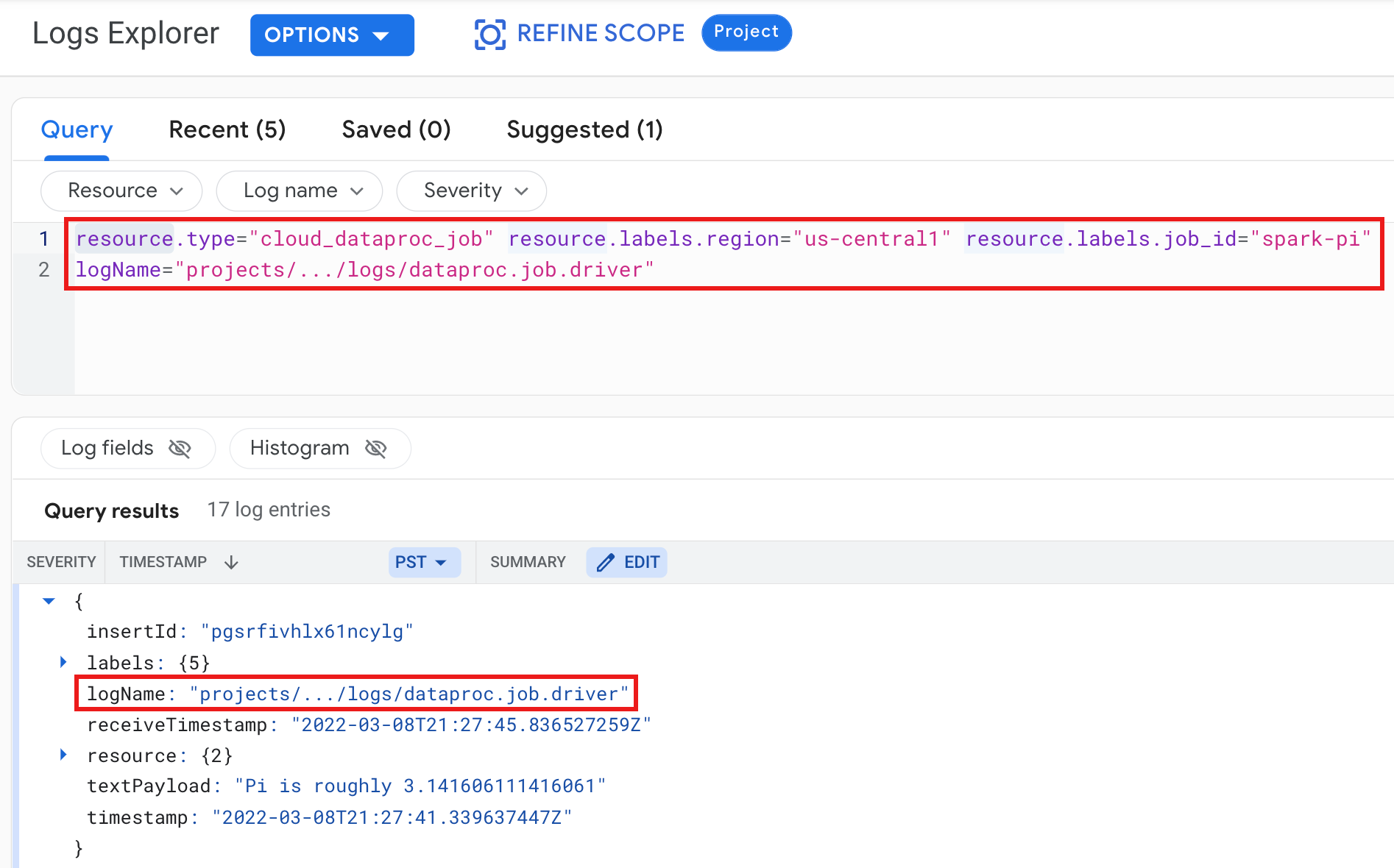
Beispiel: Job-Treiber-Log nach Ausführung einer Logs Explorer-Abfrage mit den folgenden Einstellungen:
- Ressource:
Cloud Dataproc Job - Log name:
dataproc.job.driver
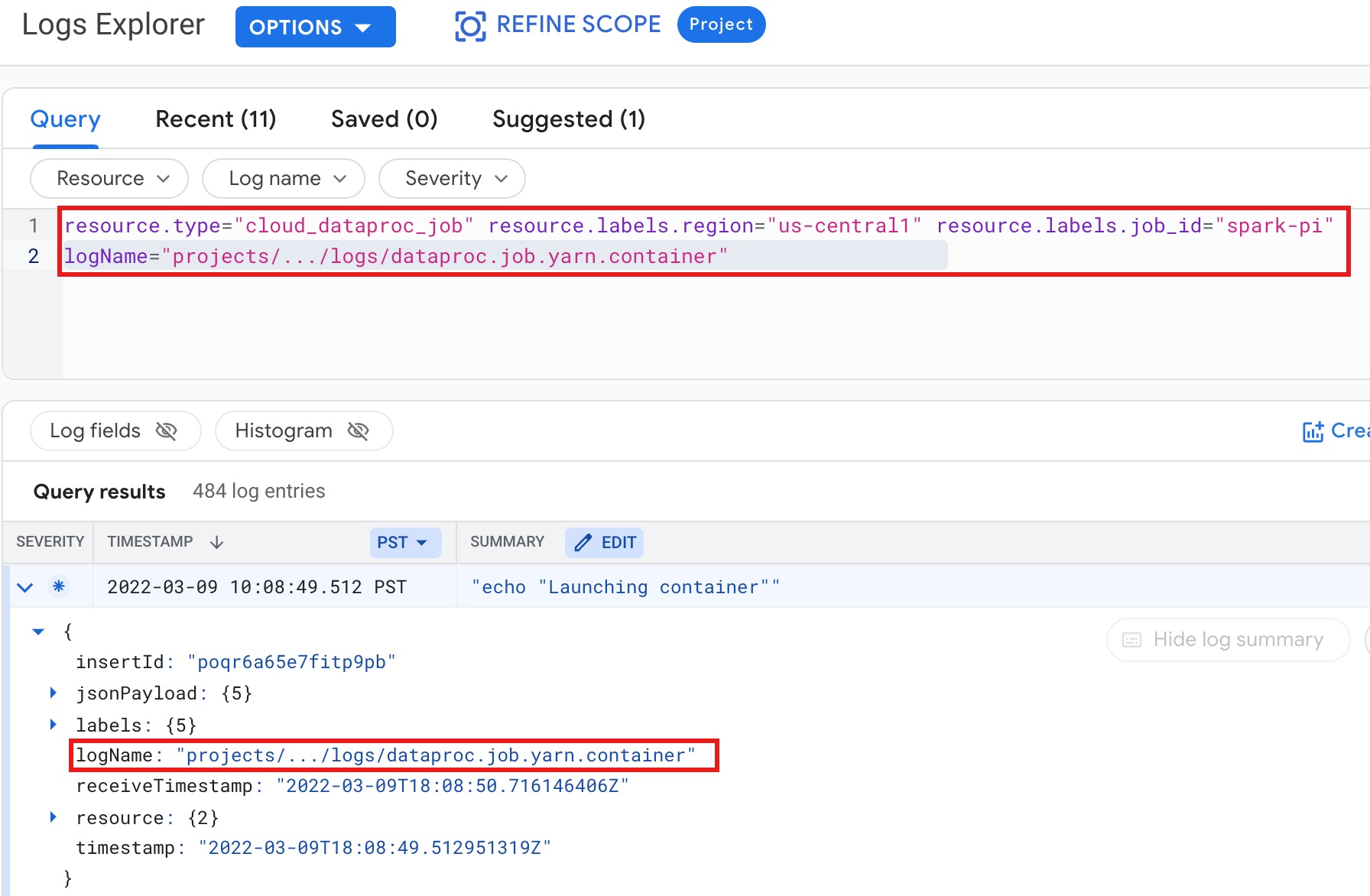
Beispiel: YARN-Containerlog nach Ausführung einer Logs Explorer-Abfrage mit den folgenden Einstellungen:
- Ressource:
Cloud Dataproc Job - Log name:
dataproc.job.yarn.container
gcloud
Sie können Joblogeinträge mit dem Befehl gcloud logging read lesen. Die Ressourcenargumente müssen in Anführungszeichen gesetzt werden („...”). Mit dem folgenden Befehl werden Clusterlabels verwendet, um die zurückgegebenen Logeinträge zu filtern.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Beispielausgabe (unvollständig):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
Sie können mit der Logging REST API Logeinträge auflisten (siehe entries.list).
Dataproc-Cluster-Logs in Logging
Dataproc exportiert die folgenden Apache Hadoop-, Spark-, Hive-, ZooKeeper- und andere Dataproc-Clusterlogs in Cloud Logging.
| Logtyp | Logname | Beschreibung | Hinweise |
|---|---|---|---|
| Master-Daemon-Logs | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Journal-Knoten HDFS-NameNode Sekundärer HDFS-NameNode Zookeeper-Failover-Controller YARN-Ressourcenmanager YARN-Timeline-Server Hive-Metaspeicher Hive-Server2 MapReduce-Jobverlaufsserver Zookeeper-Server |
|
| Worker-Daemon-Logs |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS DataNode YARN NodeManager |
|
| Systemprotokolle |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc-Autoscaling-Log Dataproc-Agent-Log Dataproc-Startskript-Log + Initialisierungsaktionslog |
|
| Erweiterte (zusätzliche) Logs |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Alle Logs in /var/log/-Unterverzeichnissen, die mit Folgendem übereinstimmen:knox (einschließlich gateway-audit.log) zeppelin ranger-usersync jupyter_notebook <x0A> jupyter_kernel_gateway <x0A> spark-history-server |
Wenn Sie das Attribut
dataproc:dataproc.logging.extended.enabled=false festlegen, wird die Erfassung erweiterter Logs im Cluster deaktiviert.
|
| VM-Syslogs |
syslog |
Syslogs von Master- und Worker-Knoten des Clusters |
Wenn Sie die Eigenschaft
dataproc:dataproc.logging.syslog.enabled=false festlegen, wird die Erfassung von VM-Syslogs im Cluster deaktiviert.
|
Auf Clusterlogs in Cloud Logging zugreifen
Sie können auf Dataproc-Clusterlogs über den Log-Explorer, den Befehl „gcloud logging“ oder die Logging API zugreifen.
Console
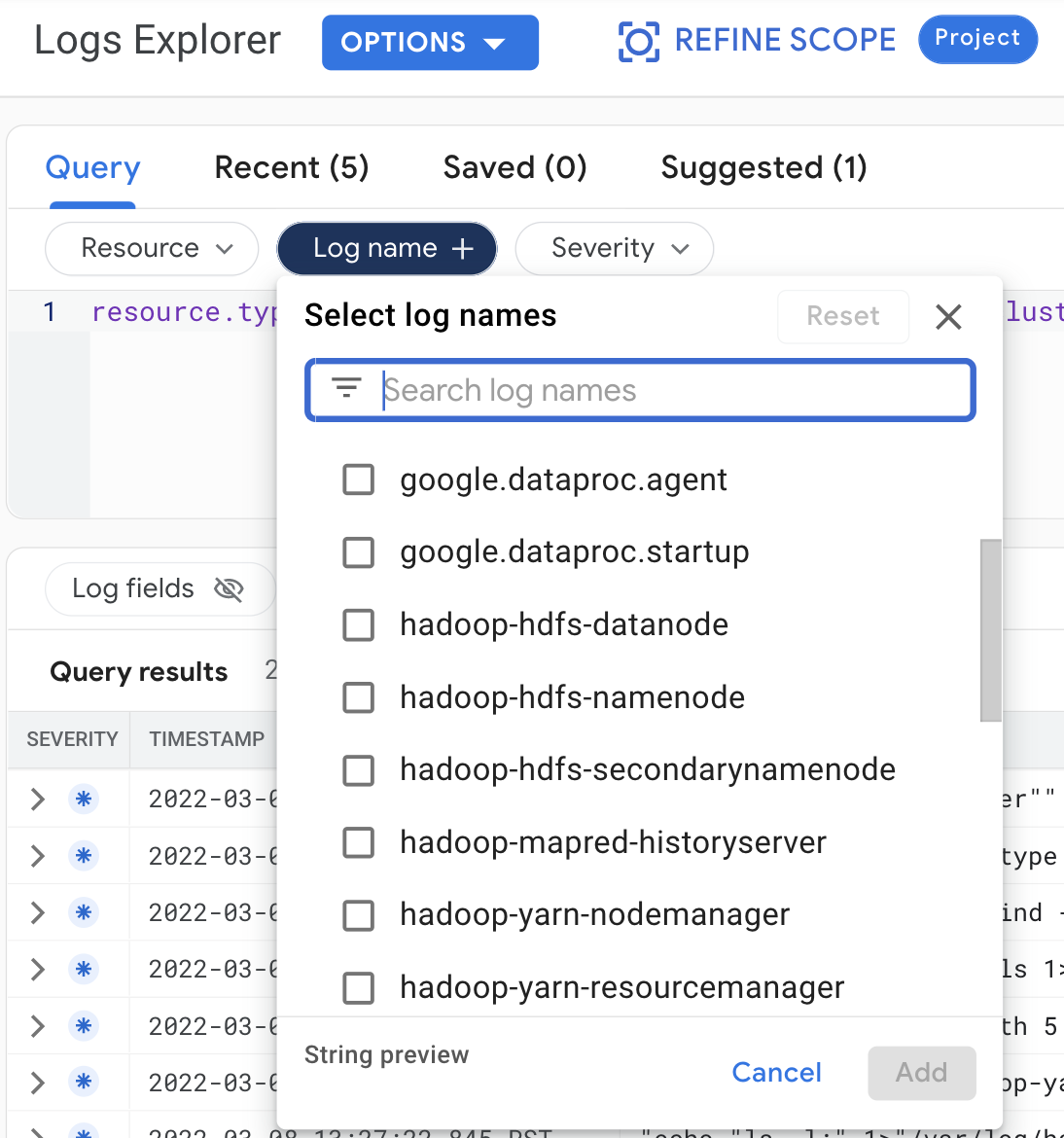
Treffen Sie die folgenden Abfrageauswahlen, um Clusterlogs im Log-Explorer aufzurufen:
- Ressource:
Cloud Dataproc Cluster - Log name: log name
gcloud
Sie können Clusterlogeinträge mit dem Befehl gcloud logging read lesen. Die Ressourcenargumente müssen in Anführungszeichen gesetzt werden („...”). Mit dem folgenden Befehl werden Clusterlabels verwendet, um die zurückgegebenen Logeinträge zu filtern.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Beispielausgabe (unvollständig):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
Sie können mit der Logging REST API Logeinträge auflisten (siehe entries.list).
Berechtigungen
Zum Schreiben von Logs in Logging muss das Dataproc-VM-Dienstkonto die IAM-Rolle logging.logWriter haben. Das Standard-Dataproc-Dienstkonto hat diese Rolle. Wenn Sie ein benutzerdefiniertes Dienstkonto verwenden, müssen Sie dem Dienstkonto diese Rolle zuweisen.
Logs schützen
Standardmäßig werden Logs in Logging verschlüsselt. Sie können vom Kunden verwaltete Verschlüsselungsschlüssel (CMEK) aktivieren, um die Logs zu verschlüsseln. Weitere Informationen zur CMEK-Unterstützung finden Sie unter Schlüssel verwalten, die Log-Router-Daten schützen und Schlüssel verwalten, die Logging-Speicherdaten schützen.
Nächste Schritte
- Google Cloud Observability entdecken.