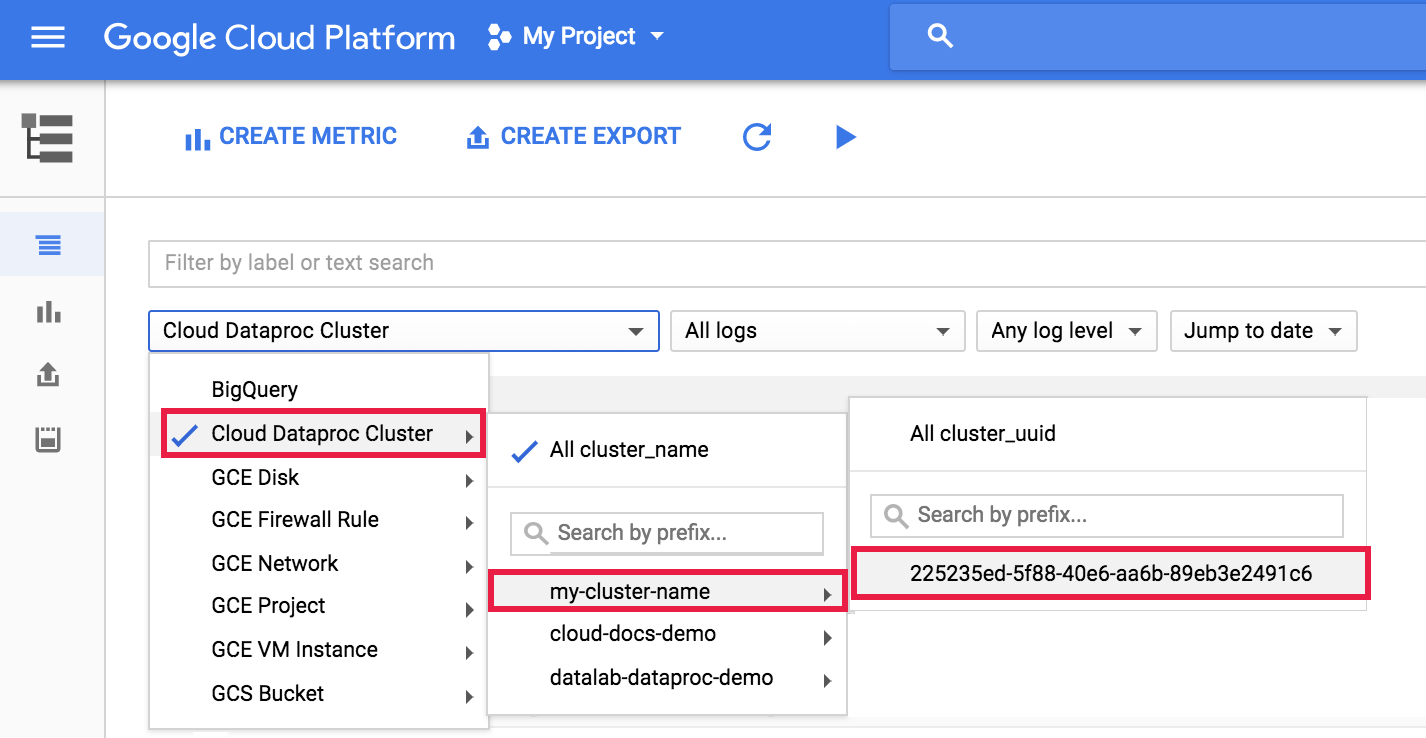
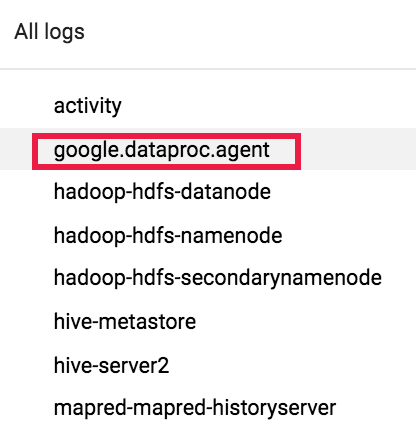
Mencari detail tugas akan menampilkan siapa yang mengirimkan tugas tersebut di kolom submittedBy. Misalnya, output tugas ini menunjukkan user@domain mengirimkan contoh
tugas ke cluster.
Hal ini menunjukkan bahwa agen Dataproc
di node master tidak dapat memperoleh tugas dari bidang kontrol.
Hal ini sering terjadi karena masalah kehabisan memori (OOM) atau masalah jaringan.
Jika tugas sebelumnya berhasil dijalankan dan Anda tidak mengubah setelan konfigurasi jaringan, OOM adalah penyebab yang paling mungkin terjadi, sering kali akibat pengiriman banyak tugas yang berjalan secara bersamaan atau tugas yang drivernya menggunakan banyak memori (misalnya, tugas yang memuat set data besar ke dalam memori).
Tidak ada agen di node master yang ditemukan aktif
Hal ini menunjukkan bahwa agen Dataproc di node master tidak aktif dan tidak dapat menerima tugas baru. Hal ini sering terjadi karena masalah kehabisan memori (OOM)
atau masalah jaringan, atau jika VM node master tidak sehat. Jika tugas berhasil dijalankan sebelumnya dan Anda belum mengubah setelan konfigurasi jaringan, OOM adalah penyebab yang paling mungkin terjadi, yang sering kali disebabkan oleh pengiriman banyak tugas yang berjalan secara bersamaan atau tugas yang drivernya menggunakan banyak memori (tugas yang memuat set data besar ke dalam memori).
Untuk membantu menyelesaikan masalah ini, Anda dapat mencoba tindakan berikut:
Error ini menunjukkan bahwa cluster dihapus saat tugas sedang berjalan.
Anda dapat melakukan tindakan berikut untuk mengidentifikasi prinsipal yang
melakukan penghapusan dan mengonfirmasi bahwa penghapusan cluster terjadi saat
tugas sedang berjalan:
Lihat log audit Dataproc untuk mengidentifikasi
akun utama yang melakukan
operasi penghapusan.
Gunakan Logging atau gcloud CLI untuk memeriksa apakah status terakhir yang diketahui dari aplikasi YARN adalah RUNNING:
Gunakan filter berikut di Logging:
resource.type="cloud_dataproc_cluster"
resource.labels.cluster_name="CLUSTER_NAME"
resource.labels.cluster_uuid="CLUSTER_UUID"
"YARN_APPLICATION_ID State change from"
Jalankan gcloud dataproc jobs describe job-id --region=REGION,
lalu periksa yarnApplications: > STATE dalam output.
Untuk menghindari error Task not found, gunakan otomatisasi untuk memastikan bahwa cluster tidak dihapus sebelum semua tugas yang sedang berjalan selesai.
Tidak ada ruang tersisa di perangkat
Dataproc menulis data HDFS dan data sementara ke disk. Pesan error ini menunjukkan bahwa cluster dibuat dengan ruang disk yang tidak mencukupi. Untuk menganalisis dan menghindari error ini:
Periksa ukuran disk utama cluster yang tercantum di tab Configuration di
halaman Cluster details di konsol Google Cloud .
Ukuran disk minimum yang direkomendasikan adalah 1000 GB untuk cluster yang menggunakan jenis mesin n1-standard-4 dan 2 TB untuk cluster yang menggunakan jenis mesin n1-standard-32.
Jika ukuran disk cluster lebih kecil dari ukuran yang direkomendasikan,
buat ulang cluster
dengan ukuran disk minimal yang direkomendasikan.
Jika ukuran disk adalah ukuran yang direkomendasikan atau lebih besar, gunakan
SSH untuk terhubung ke VM master cluster, lalu jalankan df -h di VM master untuk memeriksa pemanfaatan disk
guna menentukan apakah ruang disk tambahan diperlukan.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[[["\u003cp\u003eThis page helps users monitor and debug Dataproc jobs, offering guidance on understanding job error messages.\u003c/p\u003e\n"],["\u003cp\u003eUsers can analyze and debug Dataproc jobs using the Google Cloud CLI, Dataproc REST API, and Google Cloud console.\u003c/p\u003e\n"],["\u003cp\u003eJob logs can be accessed in Logging, and the specific logs of the dataproc agent can be selected via the Logs Explorer using specific filters.\u003c/p\u003e\n"],["\u003cp\u003eIf a job fails, users can access job logs in Logging, or use the details of a job to check who submitted it.\u003c/p\u003e\n"],["\u003cp\u003eCommon error messages, such as "Task was not acquired," "No agent on master node(s) found to be active," and "Task not found," are explained, with troubleshooting steps provided for each.\u003c/p\u003e\n"]]],[],null,["This page provides information to help you monitor and debug Dataproc\njobs and understand Dataproc job error messages.\n\nJob monitoring and debugging\n\nUse the Google Cloud CLI, Dataproc REST API, and Google Cloud console\nto analyze and debug Dataproc jobs. \n\ngcloud CLI\n\nTo examine a running job's status: \n\n```\ngcloud dataproc jobs describe job-id \\\n --region=region\n```\n\nTo view job driver output, see\n[View job output](/dataproc/docs/guides/dataproc-job-output#view_job_output).\n\nREST API\n\nCall [jobs.get](/dataproc/docs/reference/rest/v1/projects.regions.jobs/get)\nto examine a job's\n[JobStatus.State](/dataproc/docs/reference/rest/v1/projects.regions.jobs#State),\n[JobStatus.Substate](/dataproc/docs/reference/rest/v1/projects.regions.jobs#substate),\n[JobStatus.details](/dataproc/docs/reference/rest/v1/projects.regions.jobs#jobstatus), and\n[YarnApplication](/dataproc/docs/reference/rest/v1/projects.regions.jobs#YarnApplication)\nfields.\n\nConsole\n\nTo view job driver output, see\n[View job output](/dataproc/docs/guides/dataproc-job-output#view_job_output).\n\nTo view the dataproc agent log in [Logging](https://console.cloud.google.com/logs/query),\nselect **Dataproc Cluster→Cluster Name→Cluster UUID**\nfrom the Logs Explorer cluster selector.\n\nThen use the logs selector to select `google.dataproc.agent` logs.\n\nView job logs in Logging\n\nIf a job fails, you can\n[access job logs in Logging](/dataproc/docs/guides/logging#accessing_job_logs_in).\n\nDetermine who submitted a job **Google Cloud console support** \n| The ability to see who submitted a job in the Google Cloud console will be added in a future Dataproc release.\n\n[Looking up the details of a job](/dataproc/docs/guides/dataproc-job-output#view_job_output) will show who submitted that job in the `submittedBy`\nfield. For example, this job output shows `user@domain` submitted the example\njob to a cluster. \n\n```\n...\nplacement:\n clusterName: cluster-name\n clusterUuid: cluster-uuid\nreference:\n jobId: job-uuid\n projectId: project\nstatus:\n state: DONE\n stateStartTime: '2018-11-01T00:53:37.599Z'\nstatusHistory:\n- state: PENDING\n stateStartTime: '2018-11-01T00:33:41.387Z'\n- state: SETUP_DONE\n stateStartTime: '2018-11-01T00:33:41.765Z'\n- details: Agent reported job success\n state: RUNNING\n stateStartTime: '2018-11-01T00:33:42.146Z'\nsubmittedBy: \u003cvar translate=\"no\"\u003euser@domain\u003c/var\u003e\n```\n\nError messages\n\nTask was not acquired\n\nThis indicates that the Dataproc\nagent on the master node was unable to acquire the task from the control plane.\nThis often happens due to out-of-memory (OOM) or network issues.\nIf the job ran successfully previously and you have no\nt changed network\nconfiguration settings, OOM is the most likely cause, often the\nresult of the submission of many concurrently running jobs or\njobs whose drivers consume significant memory (for example, jobs that\nload large datasets into memory).\n\nNo agent on master node(s) found to be active\n\nThis indicates that the Dataproc agent on the master node is not\nactive and cannot accept new jobs. This often happens due to out-of-memory (OOM)\nor network issues, or if the master node VM is unhealthy. If the job ran successfully\npreviously and you have not changed\nnetwork configuration settings, OOM is the most likely cause, which often\nresults from the submission of many concurrently running jobs or jobs\nwhose drivers consume significant memory (jobs that load\nlarge datasets into memory).\n\nTo help resolve the problem, you can try the following actions:\n\n- Restart the job.\n- [Connect using SSH to the cluster master node](/dataproc/docs/concepts/accessing/ssh), and then determine what job or other resource is using the most memory.\n- If you can't sign in to the master node, you can check the\n [serial port (console) logs](/compute/docs/troubleshooting/viewing-serial-port-output).\n\n- [Generate a diagnostic bundle](/dataproc/docs/support/diagnose-clusters),\n which contains the syslog and other data.\n\nTask not found\n\nThis error indicates that the cluster was deleted while a job was running.\nYou can perform the following actions to identify the principal that\nperformed the deletion and confirm that cluster deletion occurred when a\njob was running:\n\n- View the Dataproc audit logs to identify\n the principal that performed the\n [delete operation](/dataproc/docs/guides/audit-logging#google.cloud.dataproc.v1.ClusterController.DeleteCluster).\n\n- Use Logging or the gcloud CLI to\n check that the YARN application's last known state was\n [RUNNING](https://hadoop.apache.org/docs/current/api//org/apache/hadoop/yarn/api/records/YarnApplicationState.html#RUNNING):\n\n - Use the following filter in Logging:\n\n ```\n resource.type=\"cloud_dataproc_cluster\"\n resource.labels.cluster_name=\"CLUSTER_NAME\"\n resource.labels.cluster_uuid=\"CLUSTER_UUID\"\n \"YARN_APPLICATION_ID State change from\"\n ```\n - Run `gcloud dataproc jobs describe job-id --region=`\u003cvar translate=\"no\"\u003eREGION\u003c/var\u003e, then check `yarnApplications: \u003e `\u003cvar translate=\"no\"\u003eSTATE\u003c/var\u003e in the output.\n- If the principal that deleted the cluster is the\n [Dataproc service agent service account](/dataproc/docs/concepts/iam/dataproc-principals#service_agent_control_plane_identity),\n check if the cluster was configured with an\n [auto-delete duration](/dataproc/docs/concepts/configuring-clusters/scheduled-deletion)\n that is less than the job duration.\n\nTo avoid `Task not found` errors, use automation to make sure that clusters are not deleted\nbefore all running jobs have completed.\n\nNo space left on device\n\nDataproc writes HDFS and scratch\ndata to disk. This error message indicates that the cluster was created with\ninsufficient disk space. To analyze and avoid this error:\n\n- Check the cluster primary disk size listed under the **Configuration** tab on\n the **Cluster details** page in the Google Cloud console.\n The recommended minimum disk size is `1000 GB` for clusters using the\n `n1-standard-4` machine-type and `2 TB` for clusters using the `n1-standard-32`\n machine-type.\n\n- If the cluster disk size is less than the recommended size,\n [recreate the cluster](/dataproc/docs/guides/recreate-cluster)\n with at least the recommended disk size.\n\n- If disk size is the recommended size or greater, use\n [SSH to connect to the cluster](/dataproc/docs/concepts/accessing/ssh)\n master VM, and then run `df -h` on the master VM to check disk utilization\n to determine if additional disk space is needed.\n\n- [Collect and check disk metrics](/dataproc/docs/guides/dataproc-metrics#custom_metric_collection)."]]