Wenn Sie den Dataproc-Dienst zum Erstellen von Clustern und Ausführen von Jobs in diesen Clustern verwenden, richtet der Dienst die erforderlichen Dataproc-Rollen und -Berechtigungen in Ihrem Projekt ein, um auf die Google Cloud -Ressourcen zuzugreifen und diese zu verwenden, die für die Erledigung dieser Aufgaben erforderlich sind. Wenn Sie jedoch projektübergreifend arbeiten, um beispielsweise auf Daten in einem anderen Projekt zuzugreifen, müssen Sie die erforderlichen Rollen und Berechtigungen für den Zugriff auf projektübergreifende Ressourcen einrichten.
Für eine erfolgreiche projektübergreifende Arbeit werden in diesem Dokument die verschiedenen Hauptkonten aufgeführt, die den Dataproc-Dienst verwenden. Es werden auch die Rollen aufgeführt, die die erforderlichen Berechtigungen enthalten, die Hauptkonten benötigen, um auf Google Cloud -Ressourcen zugreifen und diese nutzen zu können.
Es gibt drei Hauptkonten (Identitäten), die auf Dataproc zugreifen und es verwenden können:
- Nutzeridentität
- Identität der Steuerungsebene
Identität der Datenebene
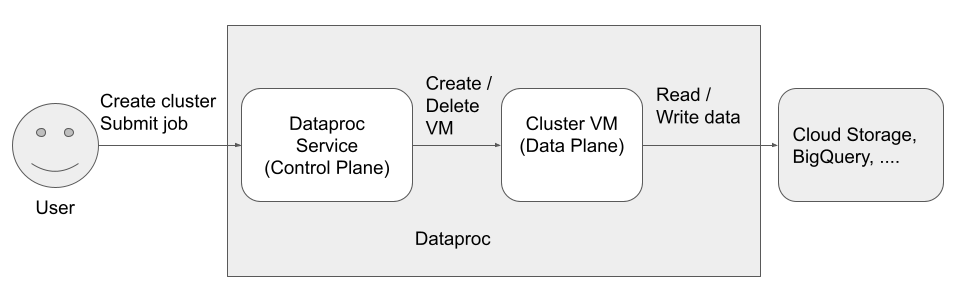
Dataproc API-Nutzer (Nutzeridentität)
Beispiel: username@example.com
Dies ist der Nutzer, der den Dataproc-Dienst aufruft, um Cluster zu erstellen, Jobs und andere Anfragen an den Dienst zu senden. Der Nutzer ist in der Regel eine Person. Wenn Dataproc über einen API-Client oder einen anderenGoogle Cloud -Dienst wie Compute Engine, Cloud Run-Funktionen oder Cloud Composer aufgerufen wird, kann es sich jedoch auch um ein Dienstkonto handeln.
Zugehörige Rollen
Hinweise
- Von Dataproc API gesendete Jobs werden unter Linux als
rootausgeführt. Dataproc-Cluster übernehmen projektweite Compute Engine-SSH-Metadaten, es sei denn, sie werden beim Erstellen Ihres Clusters explizit durch das Festlegen von
--metadata=block-project-ssh-keys=trueblockiert (siehe Cluster-Metadaten).HDFS-Nutzerverzeichnisse werden für jeden SSH-Nutzer auf Projektebene erstellt. Diese HDFS-Verzeichnisse werden bei der Clusterbereitstellung erstellt und ein neuer SSH-Nutzer (nach der Bereitstellung) erhält kein HDFS-Verzeichnis in vorhandenen Clustern.
Dataproc-Dienst-Agent (Identität der Steuerungsebene)
Beispiel: service-project-number@dataproc-accounts.iam.gserviceaccount.com
Das Dataproc-Dienst-Agent-Dienstkonto wird verwendet, um verschiedenste Systemvorgänge für Ressourcen auszuführen, die sich in dem Projekt befinden, in dem ein Dataproc-Cluster erstellt wird, darunter:
- Erstellen von Compute Engine-Ressourcen, einschließlich VM-Instanzen, Instanzgruppen und Instanzvorlagen
get- undlist-Vorgänge, um die Konfiguration von Ressourcen wie Images, Firewalls, Dataproc-Initialisierungsaktionen und Cloud Storage-Buckets zu bestätigen- Automatische Erstellung der Dataproc-Staging- und temporären Buckets, wenn vom Nutzer kein Staging- oder temporärer Bucket angegeben wurde
- Schreiben von Metadaten der Clusterkonfiguration in den Staging-Bucket
- Zugriff auf VPC-Netzwerke in einem Hostprojekt
Zugehörige Rollen
Dataproc-VM-Dienstkonto (Identität der Datenebene)
Beispiel: project-number-compute@developer.gserviceaccount.com
Ihr Anwendungscode wird auf Dataproc-VMs als VM-Dienstkonto ausgeführt. Nutzerjobs erhalten die Rollen (mit den zugehörigen Berechtigungen) dieses Dienstkontos.
Das VM-Dienstkonto hat folgende Funktionen:
- Kommuniziert mit der Dataproc-Steuerungsebene.
- Liest und schreibt Daten in und aus Dataproc-Staging- und temporären Buckets.
- Je nach Dataproc-Jobs, liest und schreibt es Daten in und aus Cloud Storage, BigQuery, Cloud Logging und anderen Google Cloud -Ressourcen.
Zugehörige Rollen
Nächste Schritte
- Weitere Informationen zu Dataproc-Rollen und ‑Berechtigungen
- Weitere Informationen zu Dataproc-Dienstkonten
- Weitere Informationen finden Sie unter BigQuery-Zugriffssteuerung.
- Weitere Informationen finden Sie unter Optionen für die Cloud Storage-Zugriffssteuerung.