Beim Erstellen eines Dataproc-Clusters können Sie die Dataproc-Cluster-Clusterauthentifizierung aktivieren, damit interaktive Arbeitslasten im Cluster sicher als Nutzeridentität ausgeführt werden können. Dies bedeutet, dass Interaktionen mit anderen Google Cloud Ressourcen wie Cloud Storage als Sie selbst und nicht als das Clusterdienstkonto authentifiziert werden.
Hinweise
Wenn Sie einen Cluster mit aktivierter personalisierter Clusterauthentifizierung erstellen, kann der Cluster nur unter Ihrer Identität verwendet werden. Andere Nutzer können dann keine Jobs auf dem Cluster ausführen und nicht auf Component Gateway-Endpunkte im Cluster zugreifen.
Cluster mit aktivierter personalisierter Clusterauthentifizierung blockieren den SSH-Zugriff und Compute Engine-Features wie Startskripts auf allen VMs im Cluster.
Bei Clustern, bei denen die personalisierte Clusterauthentifizierung automatisch aktiviert ist, wird Kerberos im Cluster automatisch für eine sichere Kommunikation innerhalb des Clusters aktiviert und konfiguriert. Alle Kerberos-Identitäten auf dem Cluster interagieren jedoch mit Google Cloud-Ressourcen wie derselbe Nutzer.
Cluster mit aktivierter personalisierter Clusterauthentifizierung unterstützen keine benutzerdefinierten Images.
Die Dataproc-Personal-Cluster-Authentifizierung unterstützt keine Dataproc-Workflows.
Die Dataproc-Clustercluster-Authentifizierung ist nur für interaktive Jobs vorgesehen, die von einem einzelnen Nutzer ausgeführt werden. Für lang andauernde Jobs und Vorgänge sollte eine entsprechende Dienstkontoidentität konfiguriert und verwendet werden.
Die weitergegebenen Anmeldedaten werden mit einer Zugriffsgrenze für Anmeldedaten herabgestuft. Die Standardzugriffsgrenze ist auf das Lesen und Schreiben von Cloud Storage-Objekten in Cloud Storage-Buckets beschränkt, die zu demselben Projekt gehören, das den Cluster enthält. Sie können eine nicht standardmäßige Zugriffsgrenze definieren, wenn Sie enable_an_interactive_session aktivieren.
Bei der persönlichen Clusterauthentifizierung von Dataproc werden Gastattribute von Compute Engine verwendet. Wenn das Feature für Gastattribute deaktiviert ist, schlägt die persönliche Clusterauthentifizierung fehl.
Ziele
Dataproc-Cluster mit aktiviertem Dataproc-Clustercluster-Authentifizierung erstellen
Starten Sie die Weitergabe von Anmeldedaten an den Cluster.
Mit einem Jupyter-Notebook im Cluster können Sie Spark-Jobs ausführen, die sich mit Ihren Anmeldedaten authentifizieren.
Vorbereitung
Projekt erstellen
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init - Starten Sie eine Cloud Shell-Sitzung.
- Führen Sie
gcloud auth loginaus, um gültige Nutzeranmeldedaten zu erhalten. Suchen Sie in gcloud nach der E-Mail-Adresse Ihres aktiven Kontos.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
einen Cluster erstellen
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Aktivieren Sie eine Sitzung zur Weitergabe der Anmeldedaten für den Cluster, um Ihre persönlichen Anmeldedaten für die Interaktion mit Google Cloud-Ressourcen zu verwenden.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Beispielausgabe:
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Beispiel für eine herabgestufte Zugriffsgrenze: Im folgenden Beispiel wird eine persönliche Authentifizierungssitzung aktiviert, die restriktiver als die standardmäßige Zugriffsgrenze für Anmeldedaten ist. Der Zugriff wird auf den Staging-Bucket des Dataproc-Clusters beschränkt. Weitere Informationen finden Sie unter Downscope mit Zugriffsgrenzen für Anmeldedaten .
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Lassen Sie den Befehl weiter laufen und wechseln Sie zu einem neuen Cloud Shell-Tab oder einer neuen Terminalsitzung. Der Client aktualisiert die Anmeldedaten, während der Befehl ausgeführt wird.
Geben Sie
Ctrl-Cein, um die Sitzung zu beenden.- Clusterdetails abrufen
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
Die URL der Jupyter-Weboberfläche wird in den Clusterdetails aufgeführt.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Kopieren Sie die URL in Ihren lokalen Browser, um die Jupyter-Benutzeroberfläche zu starten.
- Prüfen, ob die persönliche Cluster-Authentifizierung erfolgreich war.
- Starten Sie ein Jupyter-Terminal.
- Führen Sie
gcloud auth listaus - Vergewissern Sie sich, dass Ihr Nutzername das einzige aktive Konto ist.
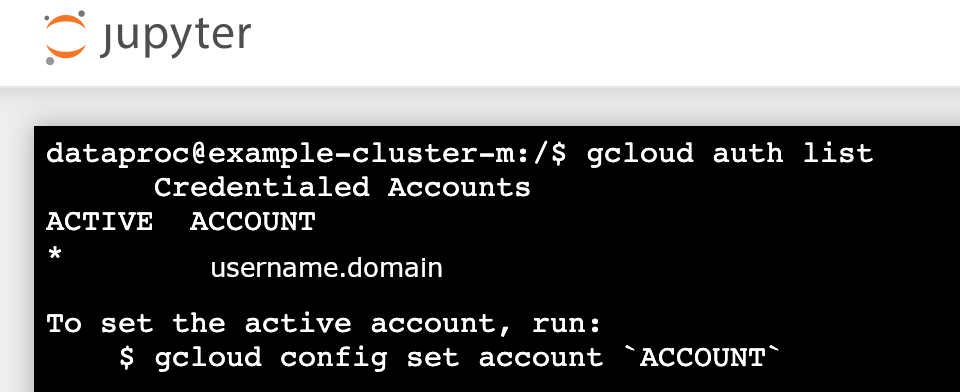
- Aktivieren Sie Jupyter in einem Jupyter-Terminal, um sich mit Kerberos zu authentifizieren und Spark-Jobs zu senden.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Führen Sie
klistaus, um zu prüfen, ob Jupyter ein gültiges TGT-Objekt erhalten hat.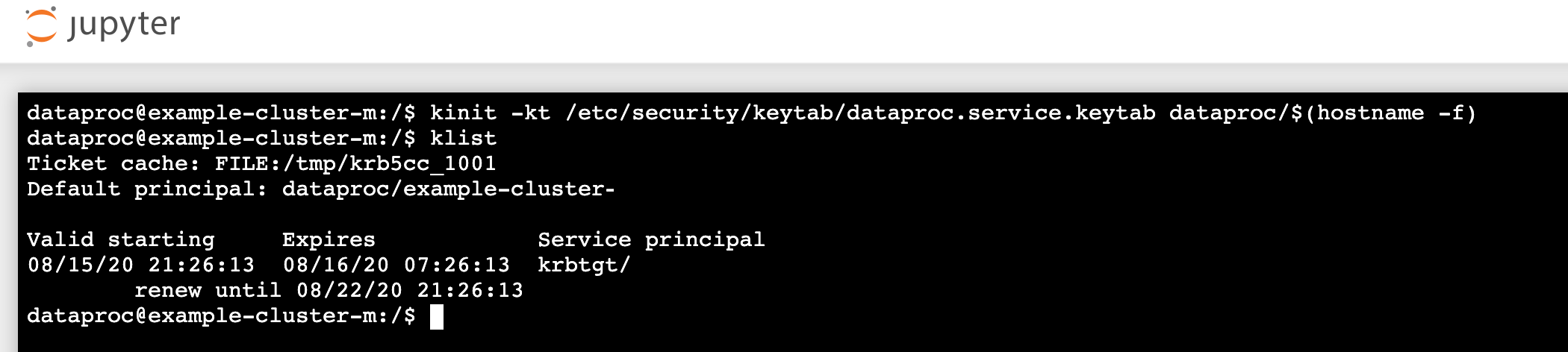
- Führen Sie
- Erstellen Sie in einem Juypter-Terminal mit der gcloud CLI eine
rose.txt-Datei in einem Cloud Storage-Bucket in Ihrem Projekt.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Kennzeichnen Sie die Datei als privat, sodass nur Ihr Nutzerkonto sie lesen oder schreiben kann. Jupyter verwendet Ihre persönlichen Anmeldedaten bei der Interaktion mit Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
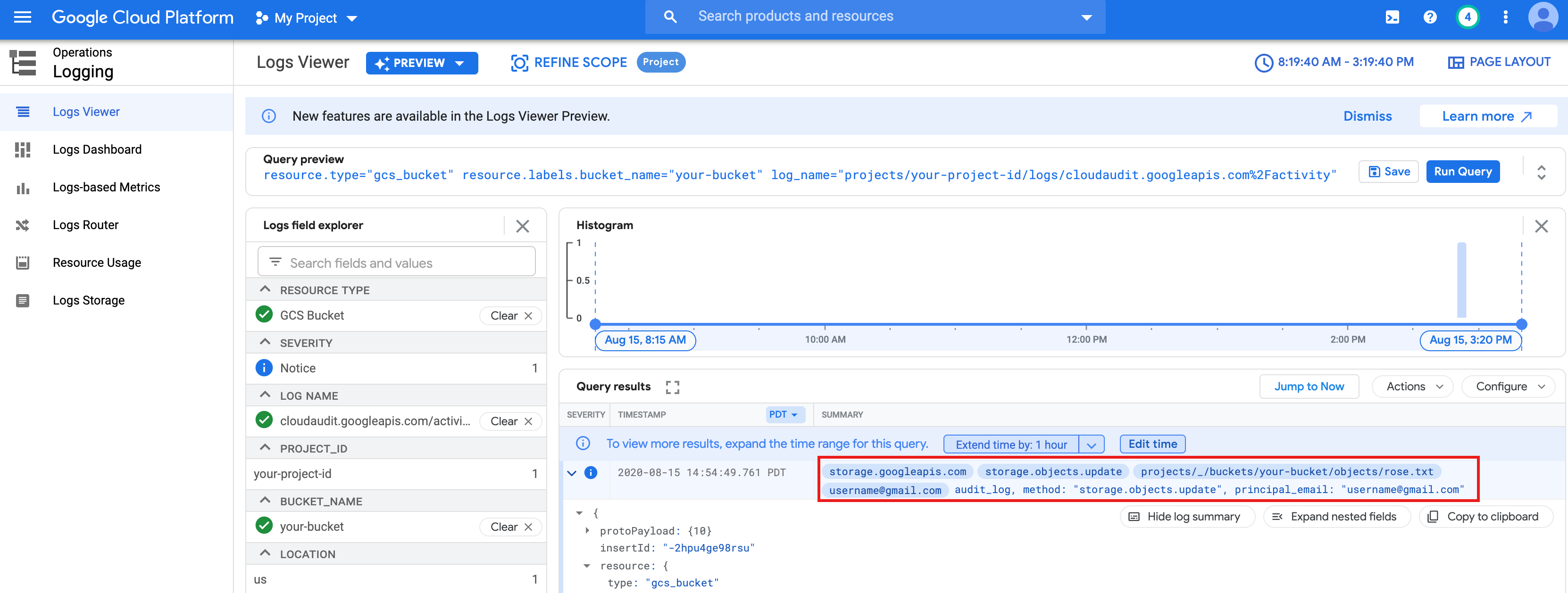
- Prüfen Sie Ihren privaten Zugriff.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Kennzeichnen Sie die Datei als privat, sodass nur Ihr Nutzerkonto sie lesen oder schreiben kann. Jupyter verwendet Ihre persönlichen Anmeldedaten bei der Interaktion mit Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Klicken Sie auf den Link Component Gateway Jupyter, um die Jupyter-Benutzeroberfläche zu starten.
- Prüfen, ob die persönliche Cluster-Authentifizierung erfolgreich war.
- Jupyter-Terminal starten
- Führen Sie
gcloud auth listaus - Vergewissern Sie sich, dass Ihr Nutzername das einzige aktive Konto ist.
- Aktivieren Sie Jupyter in einem Jupyter-Terminal, um sich mit Kerberos zu authentifizieren und Spark-Jobs zu senden.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Führen Sie
klistaus, um zu prüfen, ob Jupyter ein gültiges TGT-Objekt erhalten hat.
- Führen Sie
- Erstellen Sie in einem Jupyter-Terminal mit der gcloud CLI eine
rose.txt-Datei in einem Cloud Storage-Bucket in Ihrem Projekt.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Kennzeichnen Sie die Datei als privat, sodass nur Ihr Nutzerkonto sie lesen oder schreiben kann. Jupyter verwendet Ihre persönlichen Anmeldedaten bei der Interaktion mit Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Prüfen Sie Ihren privaten Zugriff.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Kennzeichnen Sie die Datei als privat, sodass nur Ihr Nutzerkonto sie lesen oder schreiben kann. Jupyter verwendet Ihre persönlichen Anmeldedaten bei der Interaktion mit Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Rufen Sie einen Ordner auf und erstellen Sie ein PySpark-Notebook.
Führen Sie einen einfachen Wortcount-Job für die
rose.txt-Datei aus, die Sie oben erstellt haben.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtin Cloud Storage lesen, da sie mit Ihren Nutzeranmeldedaten ausgeführt wird.Sie können auch die Audit-Logs des Cloud Storage-Buckets prüfen, um zu verifizieren, ob der Job mit Ihrer Identität auf Cloud Storage zugreift. Weitere Informationen finden Sie unter Cloud-Audit-Logs mit Cloud Storage.
- Löschen Sie den Dataproc-Cluster.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Umgebung konfigurieren
Konfigurieren Sie die Umgebung in Cloud Shell oder einem lokalen Terminal: