Dokumen ini menjelaskan alat dan file yang dapat Anda gunakan untuk memantau dan memecahkan masalah batch workload Serverless untuk Apache Spark.
Memecahkan masalah workload dari konsol Google Cloud
Jika tugas batch gagal atau memiliki performa yang buruk, langkah pertama yang direkomendasikan adalah membuka halaman Batch details dari halaman Batches di konsol Google Cloud .
Menggunakan tab Ringkasan: Hub pemecahan masalah Anda
Tab Ringkasan, yang dipilih secara default saat halaman Detail batch terbuka, menampilkan metrik penting dan log yang difilter untuk membantu Anda melakukan penilaian awal cepat terhadap kesehatan batch. Setelah penilaian awal ini, Anda dapat melakukan analisis yang lebih mendalam menggunakan alat yang lebih khusus yang tercantum di halaman Detail batch, seperti UI Spark, Logs Explorer, dan Gemini Cloud Assist.
Sorotan metrik batch
Tab Ringkasan di halaman Detail batch berisi diagram yang menampilkan nilai metrik workload batch penting. Diagram metrik diisi setelah selesai, dan menawarkan indikasi visual potensi masalah seperti perebutan resource, kemiringan data, atau tekanan memori.
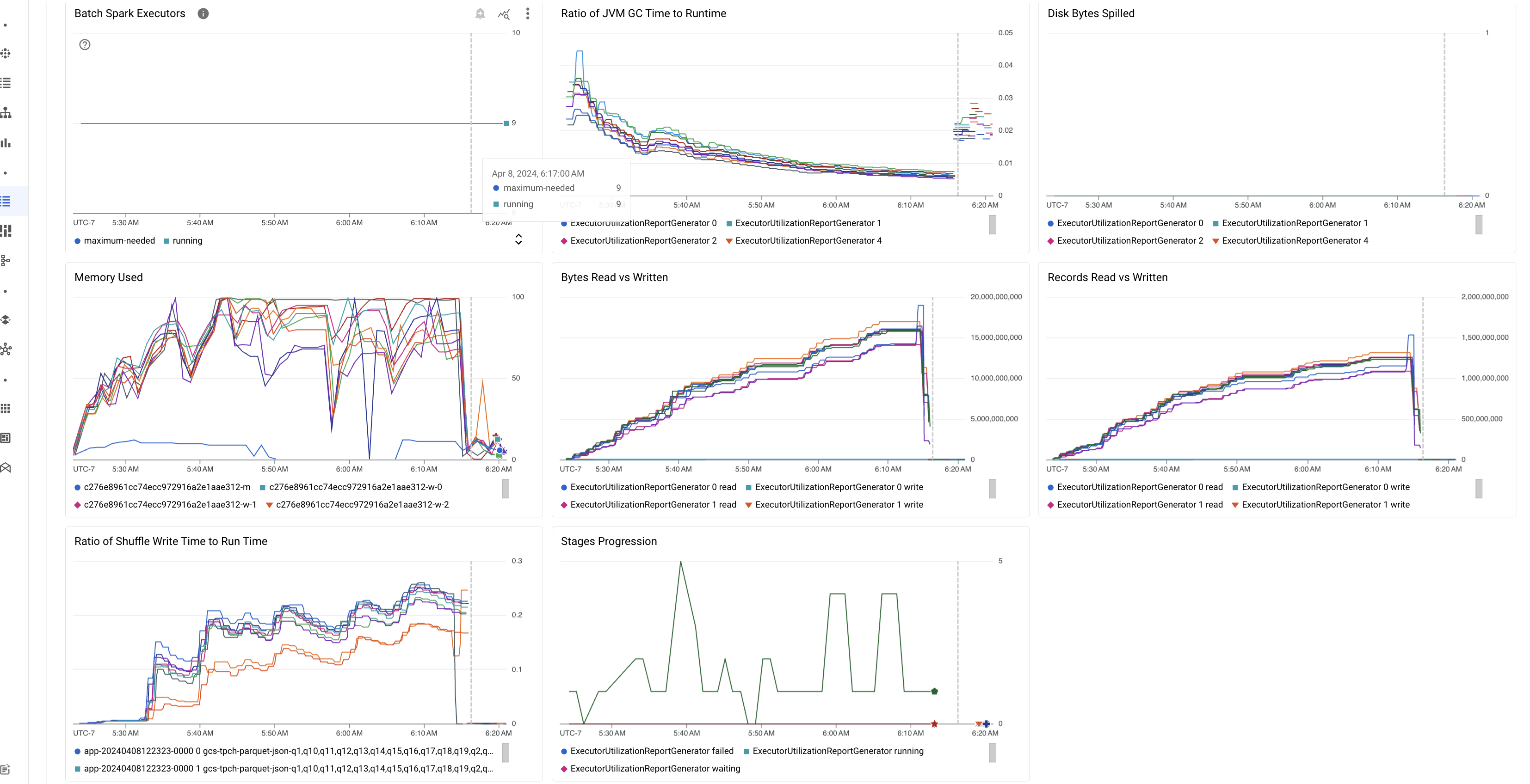
Tabel berikut mencantumkan metrik beban kerja Spark yang ditampilkan di halaman Detail batch di konsol Google Cloud , dan menjelaskan cara nilai metrik dapat memberikan insight tentang status dan performa beban kerja.
| Metrik | Apa yang ditampilkan? |
|---|---|
| Metrik di tingkat Executor | |
| Rasio Waktu GC JVM terhadap Runtime | Metrik ini menunjukkan rasio waktu GC (pengumpulan sampah) JVM terhadap runtime per eksekutor. Rasio yang tinggi dapat menunjukkan kebocoran memori dalam tugas yang berjalan di executor tertentu atau struktur data yang tidak efisien, yang dapat menyebabkan churn objek yang tinggi. |
| Byte Disk yang Ditumpahkan | Metrik ini menunjukkan total jumlah byte disk yang tumpah di berbagai eksekutor. Jika eksekutor menunjukkan byte disk yang tumpah dalam jumlah besar, hal ini dapat mengindikasikan kemiringan data. Jika metrik meningkat dari waktu ke waktu, hal ini dapat menunjukkan bahwa ada tahap dengan tekanan memori atau kebocoran memori. |
| Byte yang Dibaca dan Ditulis | Metrik ini menunjukkan byte yang ditulis versus byte yang dibaca per eksekutor. Perbedaan besar dalam byte yang dibaca atau ditulis dapat menunjukkan skenario saat gabungan yang direplikasi menyebabkan amplifikasi data pada eksekutor tertentu. |
| Data yang Dibaca dan Ditulis | Metrik ini menampilkan data yang dibaca dan ditulis per eksekutor. Jumlah besar yang mencatat pembacaan dengan jumlah kecil catatan yang ditulis dapat menunjukkan hambatan dalam logika pemrosesan pada eksekutor tertentu, sehingga menyebabkan catatan dibaca saat menunggu. Eksekutor yang terus-menerus tertinggal dalam pembacaan dan penulisan dapat menunjukkan pertentangan resource pada node tersebut atau inefisiensi kode khusus eksekutor. |
| Rasio Waktu Penulisan Acak terhadap Waktu Proses | Metrik ini menunjukkan jumlah waktu yang dihabiskan oleh executor dalam shuffle runtime dibandingkan dengan runtime keseluruhan. Jika nilai ini tinggi untuk beberapa eksekutor, hal ini dapat menunjukkan kemiringan data atau serialisasi data yang tidak efisien. Anda dapat mengidentifikasi tahap dengan waktu penulisan shuffle yang lama di UI Spark. Cari tugas pencilan dalam tahap tersebut yang memerlukan waktu lebih lama dari rata-rata untuk diselesaikan. Periksa apakah eksekutor dengan waktu penulisan shuffle yang tinggi juga menunjukkan aktivitas I/O disk yang tinggi. Serialisasi yang lebih efisien dan langkah-langkah partisi tambahan dapat membantu. Penulisan kumpulan data yang sangat besar dibandingkan dengan pembacaan kumpulan data dapat menunjukkan duplikasi data yang tidak diinginkan karena gabungan yang tidak efisien atau transformasi yang salah. |
| Metrik di tingkat Aplikasi | |
| Progres Tahapan | Metrik ini menunjukkan jumlah tahap dalam tahap yang gagal, menunggu, dan berjalan. Sejumlah besar tahap yang gagal atau menunggu dapat menunjukkan kemiringan data. Periksa partisi data, dan debug alasan kegagalan tahap menggunakan tab Stages di UI Spark. |
| Batch Spark Executor | Metrik ini menunjukkan jumlah eksekutor yang mungkin diperlukan dibandingkan dengan jumlah eksekutor yang berjalan. Perbedaan besar antara eksekutor yang diperlukan dan yang berjalan dapat menunjukkan masalah penskalaan otomatis. |
| Metrik di tingkat VM | |
| Memori yang Digunakan | Metrik ini menunjukkan persentase memori VM yang digunakan. Jika persentase master tinggi, hal ini dapat menunjukkan bahwa driver mengalami tekanan memori. Untuk node VM lainnya, persentase yang tinggi dapat menunjukkan bahwa executor kehabisan memori, yang dapat menyebabkan tumpahan disk yang tinggi dan runtime workload yang lebih lambat. Gunakan UI Spark untuk menganalisis eksekutor guna memeriksa waktu GC yang tinggi dan kegagalan tugas yang tinggi. Selain itu, debug kode Spark untuk caching set data besar dan siaran variabel yang tidak perlu. |
Log tugas
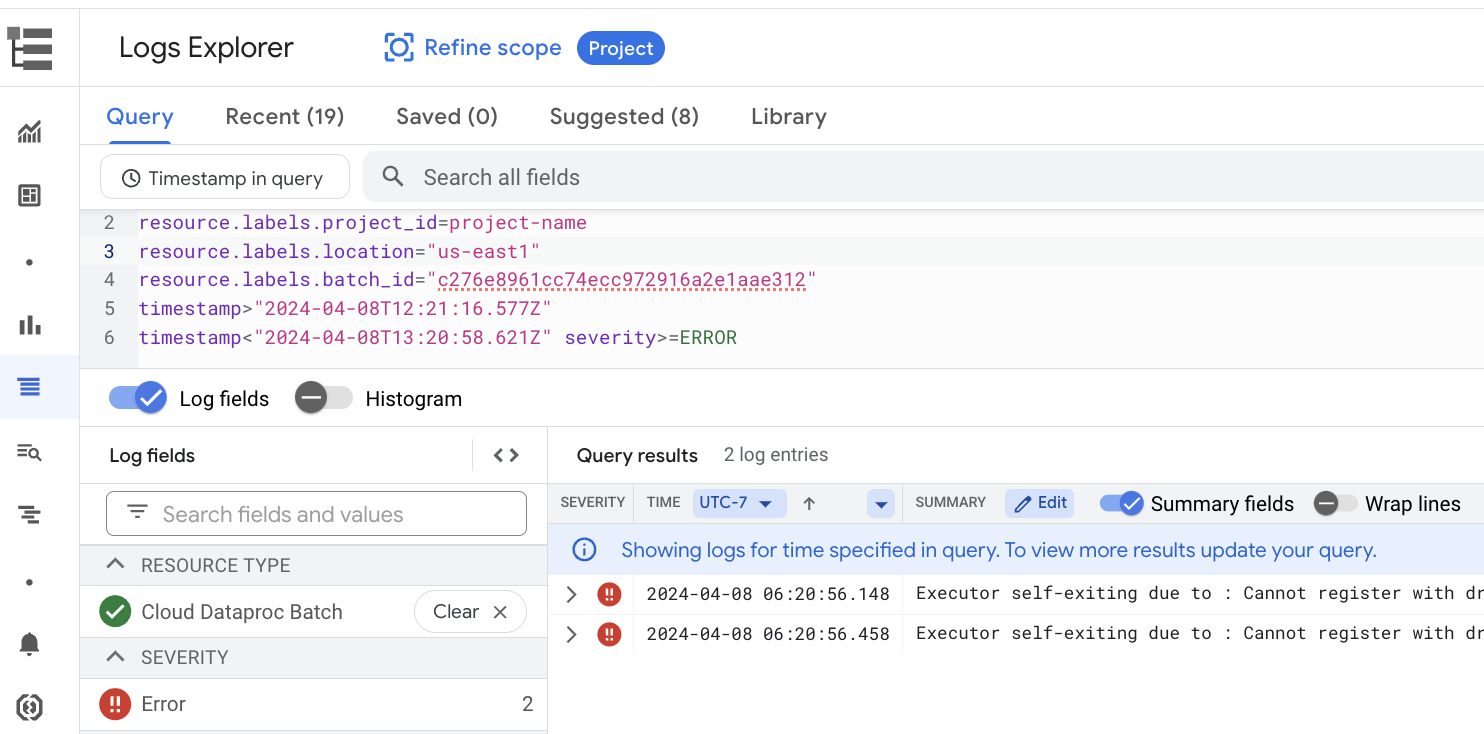
Halaman Detail batch mencakup bagian Log tugas yang mencantumkan peringatan dan error yang difilter dari log tugas (workload batch). Fitur ini memungkinkan identifikasi cepat masalah penting tanpa perlu mengurai file log yang ekstensif secara manual. Anda dapat memilih Severity log (misalnya, Error) dari menu drop-down dan menambahkan Filter teks untuk mempersempit hasil. Untuk melakukan analisis yang lebih mendalam, klik ikon Lihat di Logs Explorer
untuk membuka log batch yang dipilih di Logs Explorer.
Contoh: Logs Explorer terbuka setelah memilih Errors dari pemilih Tingkat Keparahan
di halaman Batch details di konsol Google Cloud .
UI Spark
UI Spark mengumpulkan detail eksekusi Apache Spark dari workload batch Serverless untuk Apache Spark. Fitur Spark UI tidak dikenai biaya dan diaktifkan secara default.
Data yang dikumpulkan oleh fitur Spark UI dipertahankan selama 90 hari. Anda dapat menggunakan antarmuka web ini untuk memantau dan men-debug workload Spark tanpa harus membuat Persistent History Server.
Izin dan peran Identity and Access Management yang diperlukan
Izin berikut diperlukan untuk menggunakan fitur UI Spark dengan workload batch.
Izin pengumpulan data:
dataproc.batches.sparkApplicationWrite. Izin ini harus diberikan ke akun layanan yang menjalankan beban kerja batch. Izin ini disertakan dalam peranDataproc Worker, yang otomatis diberikan ke akun layanan default Compute Engine yang digunakan Serverless for Apache Spark secara default (lihat Akun layanan Serverless for Apache Spark). Namun, jika Anda menentukan akun layanan kustom untuk workload batch, Anda harus menambahkan izindataproc.batches.sparkApplicationWriteke akun layanan tersebut (biasanya, dengan memberikan peranWorkerDataproc ke akun layanan).Izin akses UI Spark:
dataproc.batches.sparkApplicationRead. Izin ini harus diberikan kepada pengguna untuk mengakses UI Spark di konsolGoogle Cloud . Izin ini disertakan dalam peranDataproc Viewer,Dataproc Editor, danDataproc Administrator. Untuk membuka UI Spark di konsol Google Cloud , Anda harus memiliki salah satu peran ini atau memiliki peran kustom yang mencakup izin ini.
Membuka UI Spark
Halaman UI Spark tersedia di beban kerja batch konsol Google Cloud .
Buka halaman Sesi interaktif Serverless untuk Apache Spark.
Klik ID Batch untuk membuka halaman Detail batch.
Klik Lihat UI Spark di menu atas.
Tombol View Spark UI dinonaktifkan dalam kasus berikut:
- Jika izin yang diperlukan tidak diberikan
- Jika Anda menghapus centang pada kotak Aktifkan UI Spark di halaman Detail batch
- Jika Anda menetapkan properti
spark.dataproc.appContext.enabledkefalsesaat Anda mengirimkan beban kerja batch
Investigasi yang didukung AI dengan Gemini Cloud Assist (Pratinjau)
Ringkasan
Fitur pratinjau Investigasi Gemini Cloud Assist menggunakan kemampuan canggih Gemini untuk membantu membuat dan menjalankan workload batch Serverless untuk Apache Spark. Fitur ini menganalisis workload yang gagal dan berjalan lambat untuk mengidentifikasi akar masalah dan merekomendasikan perbaikan. Fitur ini membuat analisis persisten yang dapat Anda tinjau, simpan, dan bagikan kepada tim dukungan untuk memfasilitasi kolaborasi dan mempercepat penyelesaian masalah. Google Cloud
Fitur
Gunakan fitur ini untuk membuat penyelidikan dari konsol Google Cloud :
- Tambahkan deskripsi konteks bahasa alami ke masalah sebelum membuat penyelidikan.
- Menganalisis beban kerja batch yang gagal dan lambat.
- Dapatkan insight tentang penyebab utama masalah dengan perbaikan yang direkomendasikan.
- Buat Google Cloud kasus dukungan dengan konteks penyelidikan lengkap terlampir.
Sebelum memulai
Untuk mulai menggunakan fitur Investigasi, di Google Cloud project Anda, aktifkan Gemini Cloud Assist API.
Memulai investigasi
Untuk memulai penyelidikan, lakukan salah satu hal berikut:
Opsi 1: Di konsol Google Cloud , buka Halaman Daftar Batch. Untuk setiap batch dengan status
Failed, tombol SELIDIKI akan muncul di kolom Insight dari Gemini. Klik tombol untuk memulai penyelidikan.
Opsi 2: Buka Halaman Detail Batch dari beban kerja batch untuk menyelidiki. Untuk workload batch
SucceededdanFailed, di bagian Ringkasan performa pada tab Ringkasan, tombol SELIDIKI akan muncul di panel Insight dari Gemini. Klik tombol untuk memulai penyelidikan.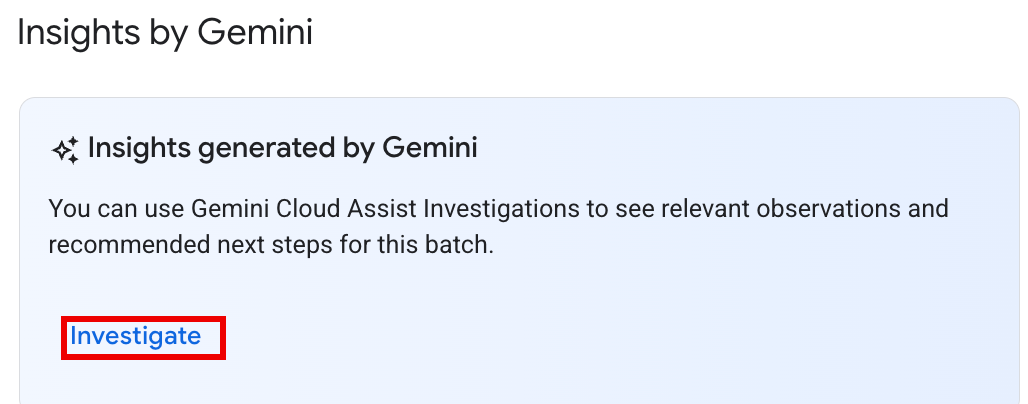
Teks tombol penyelidikan menunjukkan status penyelidikan:
- SELIDIKI: Tidak ada penyelidikan yang telah dijalankan untuk batch_details ini. Klik tombol untuk memulai penyelidikan.
- LIHAT PENYELIDIKAN: Penyelidikan telah selesai. Klik tombol Untuk melihat hasilnya.
- MENYELIDIKI: Penyelidikan sedang berlangsung.
Menafsirkan hasil investigasi
Setelah penyelidikan selesai, halaman Detail penyelidikan akan terbuka. Halaman ini berisi analisis Gemini lengkap, yang disusun ke dalam bagian-bagian berikut:
- Masalah: Bagian yang diciutkan yang berisi detail yang terisi otomatis dari beban kerja batch yang sedang diselidiki.
- Pengamatan yang Relevan: Bagian yang diciutkan yang mencantumkan titik data dan anomali utama yang ditemukan Gemini selama analisis log dan metrik.
- Hipotesis: Ini adalah bagian utama, yang diperluas secara default.
Bagian ini menampilkan daftar kemungkinan penyebab utama masalah yang diamati. Setiap hipotesis
mencakup:
- Ringkasan: Deskripsi kemungkinan penyebab, seperti "Waktu Penulisan Shuffle Tinggi dan Kemungkinan Kemiringan Tugas".
- Perbaikan yang Direkomendasikan: Daftar langkah-langkah yang dapat ditindaklanjuti untuk mengatasi kemungkinan masalah.
Ambil tindakan
Setelah meninjau hipotesis dan rekomendasi:
Terapkan satu atau beberapa perbaikan yang disarankan ke konfigurasi atau kode tugas, lalu jalankan kembali tugas.
Berikan masukan tentang kegunaan investigasi dengan mengklik ikon suka atau tidak suka di bagian atas panel.
Meninjau dan mengeskalasikan investigasi
Hasil investigasi yang dijalankan sebelumnya dapat ditinjau dengan mengklik nama investigasi di halaman Investigasi Cloud Assist untuk membuka halaman Detail investigasi.
Jika memerlukan bantuan lebih lanjut, Anda dapat membuka Google Cloud kasus dukungan. Proses ini memberikan konteks lengkap kepada engineer dukungan terkait penyelidikan yang dilakukan sebelumnya, termasuk pengamatan dan hipotesis yang dihasilkan oleh Gemini. Berbagi konteks ini secara signifikan mengurangi komunikasi bolak-balik yang diperlukan dengan tim dukungan, dan menghasilkan penyelesaian kasus yang lebih cepat.
Untuk membuat kasus dukungan dari penyelidikan:
Di halaman Detail penyelidikan, klik Minta dukungan.
Status dan harga pratinjau
Penyelidikan Gemini Cloud Assist tidak dikenai biaya selama pratinjau publik. Biaya akan berlaku untuk fitur ini saat tersedia secara umum (GA).
Untuk mengetahui informasi selengkapnya tentang harga setelah ketersediaan umum, lihat Harga Gemini Cloud Assist.
Pratinjau Tanya Gemini (Dihentikan pada 22 September 2025)
Fitur pratinjau Tanya Gemini memberikan akses sekali klik ke insight di halaman Batch dan Detail batch di konsol Google Cloud melalui tombol Tanya Gemini. Fungsi ini menghasilkan ringkasan error, anomali, dan potensi peningkatan performa berdasarkan log dan metrik beban kerja.
Setelah pratinjau "Tanya Gemini" dihentikan pada 22 September 2025, pengguna dapat terus mendapatkan bantuan yang didukung AI menggunakan fitur Investigasi Gemini Cloud Assist.
Penting: Untuk memastikan bantuan AI pemecahan masalah yang tidak terganggu, sebaiknya aktifkan Investigasi Gemini Cloud Assist sebelum 22 September 2025.
Log Serverless untuk Apache Spark
Logging diaktifkan secara default di Serverless untuk Apache Spark, dan log workload tetap ada setelah workload selesai. Serverless untuk Apache Spark mengumpulkan log workload di Cloud Logging.
Anda dapat mengakses log Serverless untuk Apache Spark di bagian resource
Cloud Dataproc Batch di Logs Explorer.
Membuat kueri log Serverless untuk Apache Spark
Logs Explorer di konsol Google Cloud menyediakan panel kueri untuk membantu Anda membuat kueri guna memeriksa log beban kerja batch. Berikut adalah langkah-langkah yang dapat Anda ikuti untuk membuat kueri guna memeriksa log workload batch:
- Project Anda saat ini dipilih. Anda dapat mengklik Perbaiki cakupan Project untuk memilih project lain.
Tentukan kueri log batch.
Gunakan menu filter untuk memfilter workload batch.
Di bagian All resources, pilih resource Cloud Dataproc Batch.
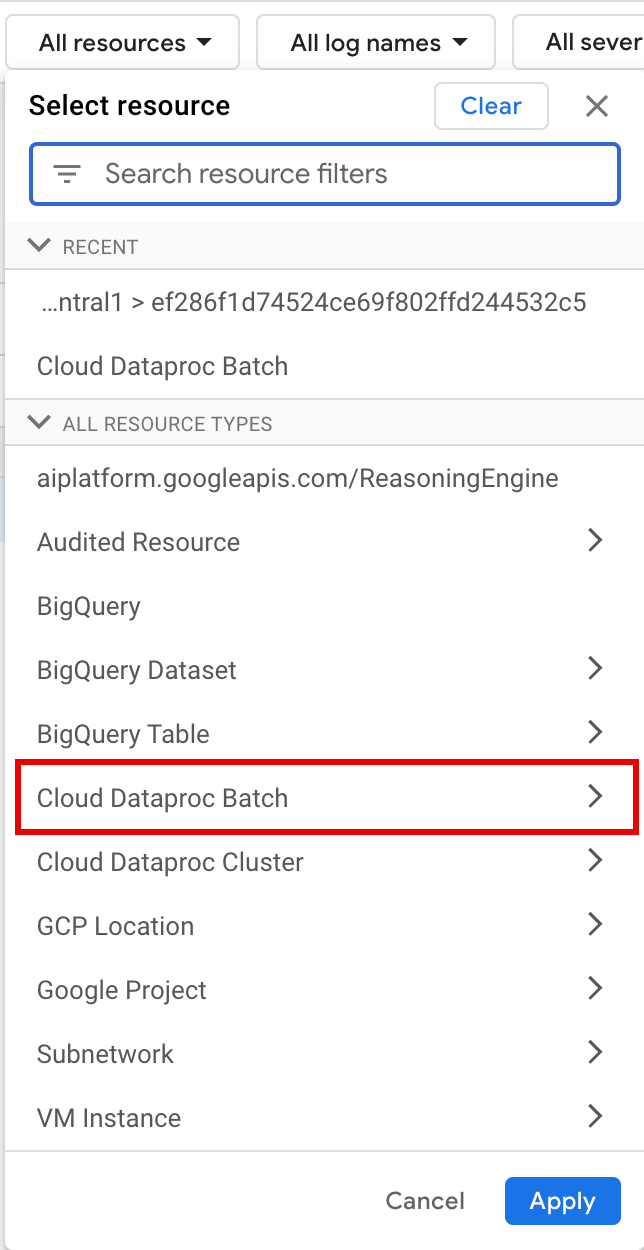
Di panel Pilih resource, pilih batch LOCATION, lalu BATCH ID. Parameter batch ini tercantum di halaman Batch Dataproc di konsol Google Cloud .
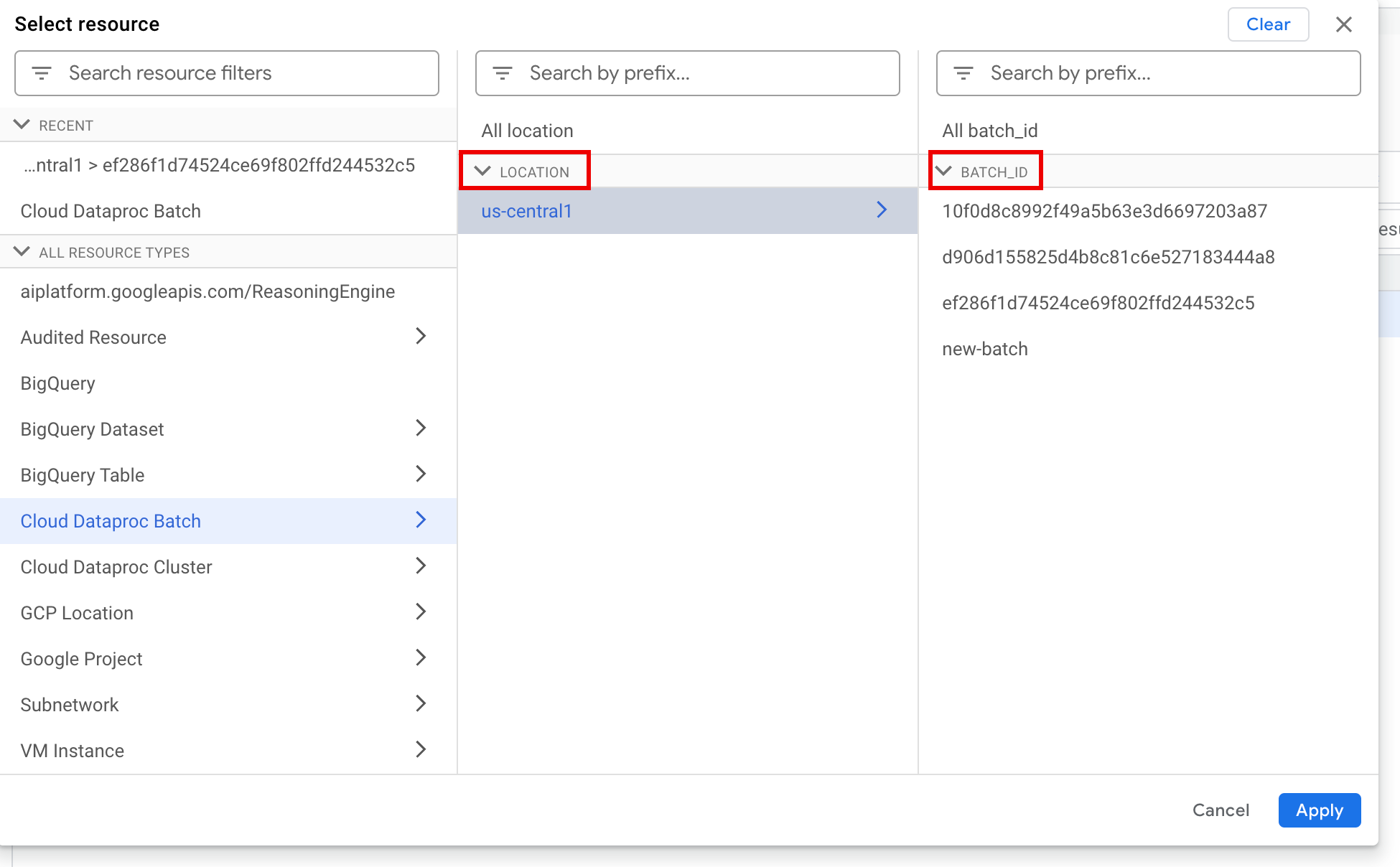
Klik Terapkan.
Di bagian Select log names, masukkan
dataproc.googleapis.comdi kotak Search log names untuk membatasi jenis log yang akan dikueri. Pilih satu atau beberapa nama file log yang tercantum.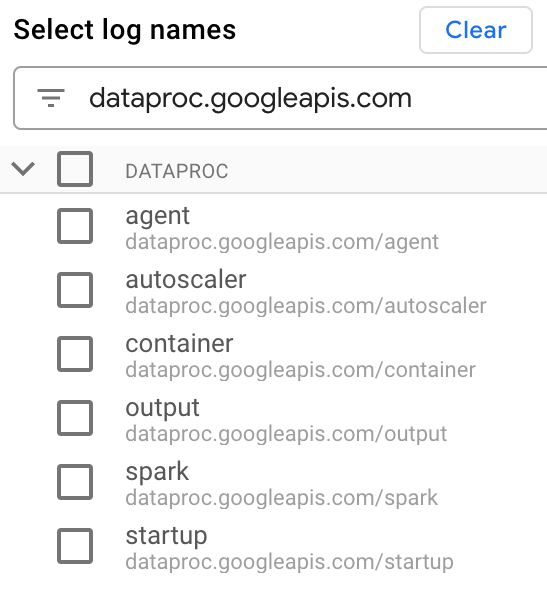
Gunakan editor kueri untuk memfilter log khusus VM.
Tentukan jenis resource dan nama resource VM seperti yang ditunjukkan pada contoh berikut:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID: UUID batch tercantum di halaman Detail batch di konsol Google Cloud , yang terbuka saat Anda mengklik ID Batch di halaman Batch.
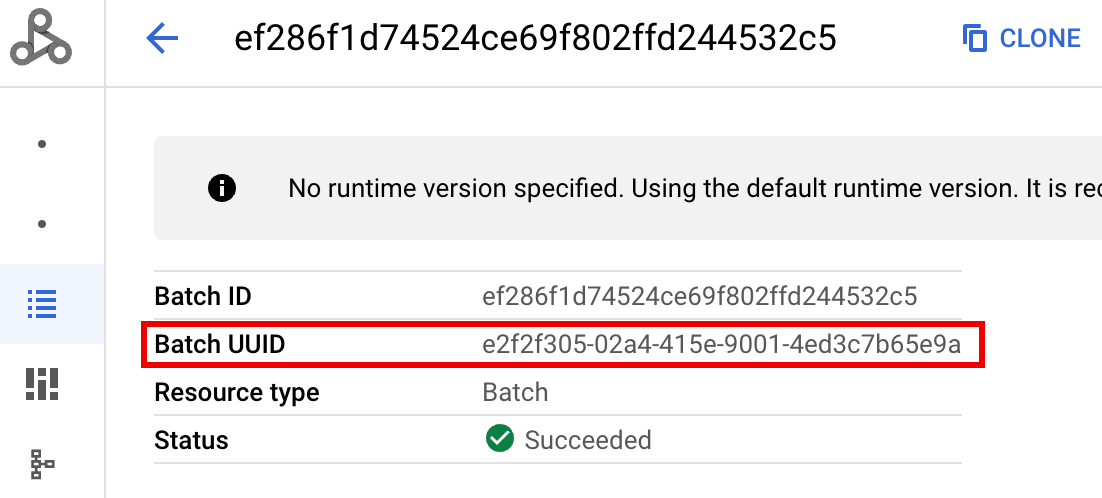
Log batch juga mencantumkan UUID batch dalam nama resource VM. Berikut adalah contoh dari batch driver.log:
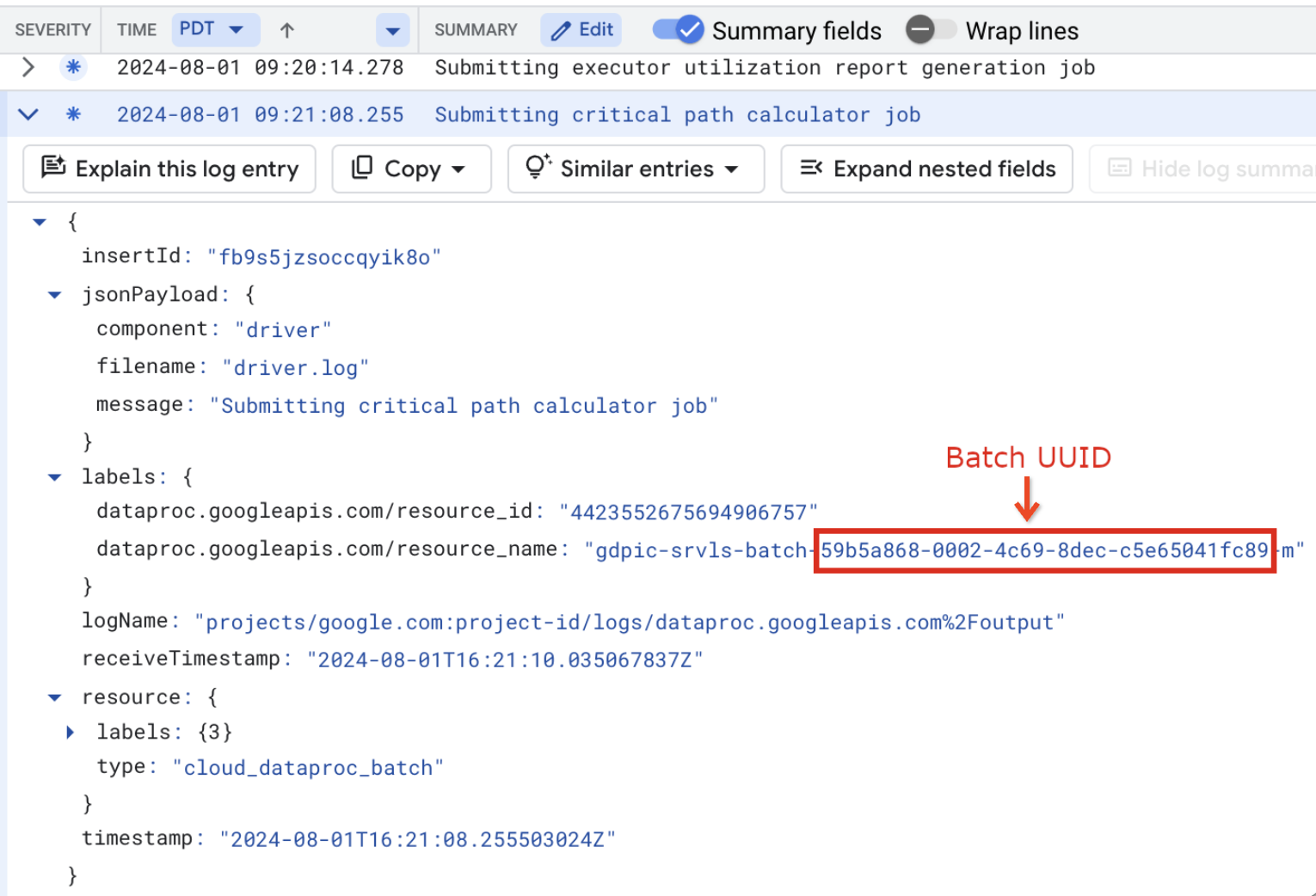
- BATCH_UUID: UUID batch tercantum di halaman Detail batch di konsol Google Cloud , yang terbuka saat Anda mengklik ID Batch di halaman Batch.
Klik Run query.
Jenis log dan contoh kueri Serverless for Apache Spark
Daftar berikut menjelaskan berbagai jenis log Serverless for Apache Spark dan memberikan contoh kueri Logs Explorer untuk setiap jenis log.
dataproc.googleapis.com/output: File log ini berisi output beban kerja batch. Serverless untuk Apache Spark mengalirkan output batch ke namespaceoutput, dan menetapkan nama file keJOB_ID.driver.log.Contoh kueri Logs Explorer untuk log output:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: Namespacesparkmengagregasi log Spark untuk daemon dan eksekutor yang berjalan di VM master dan pekerja cluster Dataproc. Setiap entri log menyertakan label komponenmaster,worker, atauexecutoruntuk mengidentifikasi sumber log, sebagai berikut:executor: Log dari eksekutor kode pengguna. Biasanya, ini adalah log terdistribusi.master: Log dari master pengelola resource mandiri Spark, yang serupa dengan logResourceManagerDataproc di Compute Engine YARN.worker: Log dari pekerja pengelola resource mandiri Spark, yang mirip dengan logNodeManagerYARN Dataproc di Compute Engine.
Contoh kueri Logs Explorer untuk semua log di namespace
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Contoh kueri Logs Explorer untuk log komponen mandiri Spark di namespace
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: Namespacestartupmencakup log startup batch (cluster). Semua log skrip inisialisasi disertakan. Komponen diidentifikasi berdasarkan label, misalnya:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: Namespaceagentmenggabungkan log agen Dataproc. Setiap entri log menyertakan label nama file yang mengidentifikasi sumber log.Contoh kueri Logs Explorer untuk log agen yang dihasilkan oleh VM pekerja tertentu:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: Namespaceautoscalermenggabungkan log autoscaler Serverless for Apache Spark.Contoh kueri Logs Explorer untuk log agen yang dihasilkan oleh VM pekerja tertentu:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Untuk mengetahui informasi selengkapnya, lihat Log Dataproc.
Untuk mengetahui informasi tentang log audit Serverless untuk Apache Spark, lihat Logging audit Dataproc.
Metrik workload
Serverless untuk Apache Spark menyediakan metrik batch dan Spark yang dapat Anda lihat dari Metrics Explorer atau halaman Detail batch di konsol Google Cloud .
Metrik batch
Metrik resource batch Dataproc memberikan insight tentang resource batch, seperti jumlah eksekutor batch. Metrik batch diawali dengan
dataproc.googleapis.com/batch.
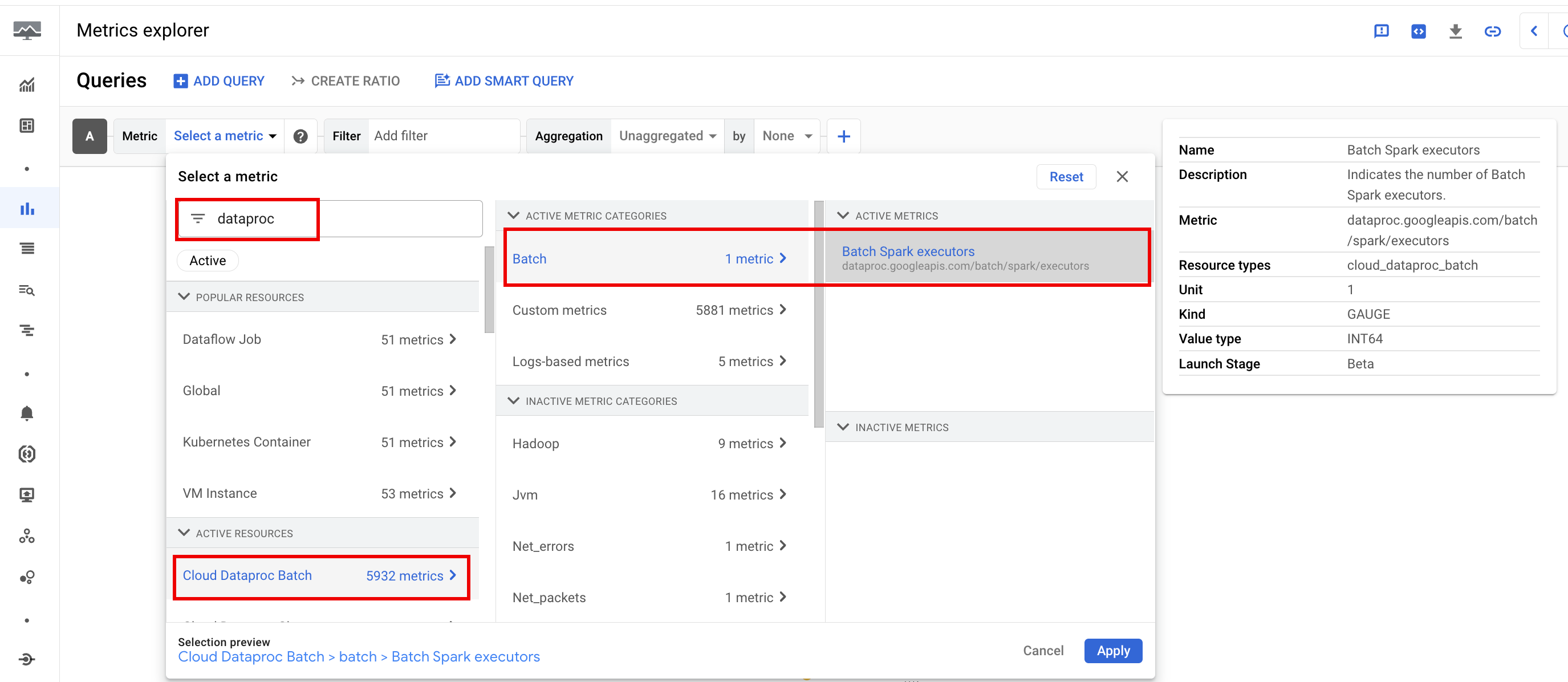
Metrik Spark
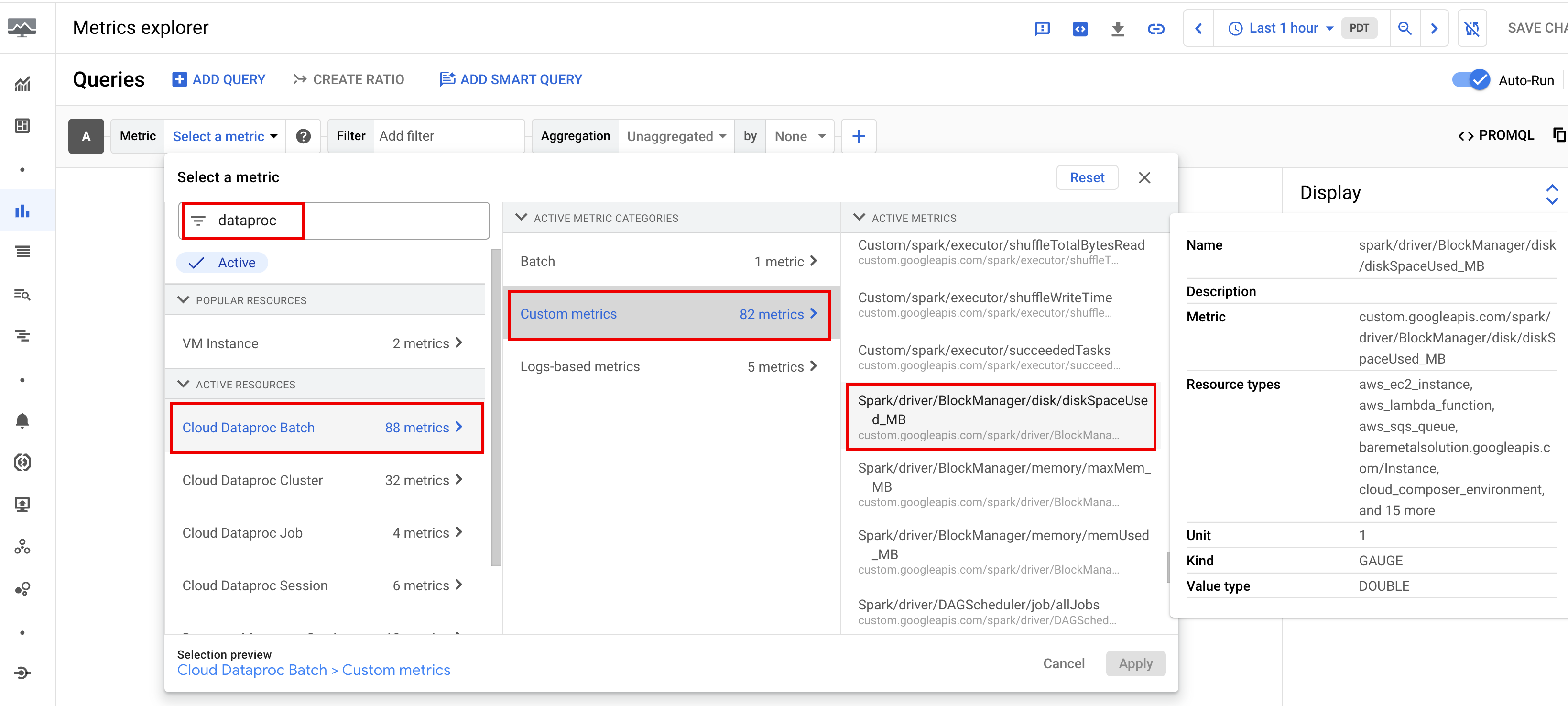
Secara default, Serverless untuk Apache Spark mengaktifkan pengumpulan metrik Spark yang tersedia, kecuali jika Anda menggunakan properti pengumpulan metrik Spark untuk menonaktifkan atau mengganti pengumpulan satu atau beberapa metrik Spark.
Metrik Spark yang tersedia
mencakup metrik driver dan eksekutor Spark, serta metrik sistem. Metrik Spark yang tersedia diawali
dengan custom.googleapis.com/.
Menyiapkan pemberitahuan metrik
Anda dapat membuat pemberitahuan metrik Dataproc untuk menerima pemberitahuan tentang masalah beban kerja.
Membuat diagram
Anda dapat membuat diagram yang memvisualisasikan metrik beban kerja menggunakan
Metrics Explorer di
konsolGoogle Cloud . Misalnya, Anda dapat
membuat diagram untuk menampilkan disk:bytes_used, lalu memfilter menurut batch_id.
Cloud Monitoring
Monitoring menggunakan metrik dan metadata workload untuk memberikan insight tentang kondisi dan performa workload Serverless for Apache Spark. Metrik beban kerja mencakup metrik Spark, metrik batch, dan metrik operasi.
Anda dapat menggunakan Cloud Monitoring di konsol Google Cloud untuk menjelajahi metrik, menambahkan diagram, membuat dasbor, dan membuat pemberitahuan.
Membuat dasbor
Anda dapat membuat dasbor untuk memantau beban kerja menggunakan metrik dari beberapa project dan produk yang berbeda. Google Cloud Untuk mengetahui informasi selengkapnya, lihat Membuat dan mengelola dasbor kustom.
Server Histori Persisten
Serverless untuk Apache Spark membuat resource komputasi yang diperlukan untuk menjalankan workload, menjalankan workload pada resource tersebut, lalu menghapus resource saat workload selesai. Metrik dan peristiwa beban kerja tidak dipertahankan setelah beban kerja selesai. Namun, Anda dapat menggunakan Persistent History Server (PHS) untuk menyimpan histori aplikasi workload (log peristiwa) di Cloud Storage.
Untuk menggunakan PHS dengan workload batch, lakukan langkah-langkah berikut:
Tentukan PHS Anda saat Anda mengirimkan workload.
Gunakan Component Gateway untuk terhubung ke PHS guna melihat detail aplikasi, tahap penjadwal, detail tingkat tugas, serta informasi lingkungan dan eksekutor.
Penyesuaian otomatis
- Aktifkan penyetelan otomatis untuk Serverless for Apache Spark: Anda dapat mengaktifkan Penyetelan Otomatis untuk Serverless for Apache Spark saat mengirimkan setiap workload batch Spark berulang menggunakan Google Cloud konsol, gcloud CLI, atau Dataproc API.
Konsol
Lakukan langkah-langkah berikut untuk mengaktifkan penyetelan otomatis pada setiap beban kerja batch Spark berulang:
Di konsol Google Cloud , buka halaman Batch Dataproc.
Untuk membuat workload batch, klik Buat.
Di bagian Container, isi nama Cohort, yang mengidentifikasi batch sebagai salah satu dari serangkaian workload berulang. Analisis yang dibantu Gemini diterapkan pada workload kedua dan berikutnya yang dikirimkan dengan nama kohor ini. Misalnya, tentukan
TPCH-Query1sebagai nama kohor untuk workload terjadwal yang menjalankan kueri TPC-H harian.Isi bagian lain di halaman Buat batch sesuai kebutuhan, lalu klik Kirim. Untuk mengetahui informasi selengkapnya, lihat Mengirimkan workload batch.
gcloud
Jalankan perintah gcloud CLI
gcloud dataproc batches submit
berikut secara lokal di jendela terminal atau di Cloud Shell
untuk mengaktifkan penyetelan otomatis pada setiap beban kerja batch Spark berulang:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Ganti kode berikut:
- COMMAND: jenis beban kerja Spark, seperti
Spark,PySpark,Spark-Sql, atauSpark-R. - REGION: region tempat workload Anda akan berjalan.
- COHORT: nama kohor, yang
mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang.
Analisis yang dibantu Gemini diterapkan pada workload kedua dan berikutnya yang dikirimkan
dengan nama kelompok ini. Misalnya, tentukan
TPCH Query 1sebagai nama kohor untuk workload terjadwal yang menjalankan kueri TPC-H harian.
API
Sertakan nama RuntimeConfig.cohort
dalam permintaan batches.create
untuk mengaktifkan penyetelan otomatis pada setiap workload batch Spark
berulang. Penyetelan otomatis diterapkan ke beban kerja kedua dan berikutnya yang dikirimkan dengan nama kohor ini. Misalnya, tentukan TPCH-Query1 sebagai nama kohor untuk workload terjadwal yang menjalankan kueri TPC-H harian.
Contoh:
...
runtimeConfig:
cohort: TPCH-Query1
...