Overview
You can use Dataflow data pipelines for the following tasks:
- Create recurrent job schedules.
- Understand where resources are spent over multiple job executions.
- Define and manage data freshness objectives.
- Drill down into individual pipeline stages to fix and optimize your pipelines.
For API documentation, see the Data Pipelines reference.
Features
- Create a recurring batch pipeline to run a batch job on a schedule.
- Create a recurring incremental batch pipeline to run a batch job against the latest version of input data.
- Use the pipeline summary scorecard to view the aggregated capacity usage and resource consumption of a pipeline.
- View the data freshness of a streaming pipeline. This metric, which evolves over time, can be tied to an alert that notifies you when freshness falls lower than a specified objective.
- Use pipeline metric graphs to compare batch pipeline jobs and find anomalies.
Limitations
Regional availability: You can create data pipelines in available Cloud Scheduler regions.
Quota:
- Default number of pipelines per project: 500
Default number of pipelines per organization: 2500
The organization level quota is disabled by default. You can opt-in to organization level quotas, and if you do so, each organization can have at most 2500 pipelines by default.
Labels: You can't use user-defined labels to label Dataflow data pipelines. However, when you use the
additionalUserLabelsfield, those values are passed through to your Dataflow job. For more information about how labels apply to individual Dataflow jobs, see Pipeline options.
Types of data pipelines
Dataflow has two data pipeline types, streaming and batch. Both types of pipeline run jobs that are defined in Dataflow templates.
- Streaming data pipeline
- A streaming data pipeline runs a Dataflow streaming job immediately after it's created.
- Batch data pipeline
A batch data pipeline runs a Dataflow batch job on a user-defined schedule. The batch pipeline input filename can be parameterized to allow for incremental batch pipeline processing.
Incremental batch pipelines
You can use datetime placeholders to specify an incremental input file format for a batch pipeline.
- Placeholders for year, month, date, hour, minute, and second can be used, and
must follow the
strftime()format. Placeholders are preceded by the percentage symbol (%). - Parameter formatting is not verified during pipeline creation.
- Example: If you specify "gs://bucket/Y" as the parameterized input path,
it's evaluated as "gs://bucket/Y", because "Y" without a preceding "%"
does not map to the
strftime()format.
- Example: If you specify "gs://bucket/Y" as the parameterized input path,
it's evaluated as "gs://bucket/Y", because "Y" without a preceding "%"
does not map to the
At each scheduled batch pipeline execution time, the placeholder portion of the input path is evaluated to the current (or time-shifted) datetime. Date values are evaluated using the current date in the time zone of the scheduled job. If the evaluated path matches the path of an input file, the file is picked up for processing by the batch pipeline at the scheduled time.
- Example: A batch pipeline is scheduled to repeat at the start of each hour
PST. If you parameterize the input path as
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, on April 15, 2021, 6PM PST, the input path is evaluated togs://bucket-name/2021-04-15/prefix-18_00.csv.
Use time shift parameters
You can use + or - minute or hour time shift parameters.
To support matching an input path with an evaluated datetime that is
shifted before or after the current datetime of the pipeline schedule,
enclose these parameters in curly braces.
Use the format {[+|-][0-9]+[m|h]}. The batch pipeline continues to repeat at its
scheduled time, but the input path is evaluated with the specified
time offset.
- Example: A batch pipeline is scheduled to repeat at the start of each hour
PST. If you parameterize the input path as
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, on April 15, 2021, 6PM PST, the input path is evaluated togs://bucket-name/2021-04-15/prefix-16_00.csv.
Data pipeline roles
For Dataflow data pipeline operations to succeed, you need the necessary IAM roles, as follows:
You need the appropriate role to perform operations:
Datapipelines.admin: Can perform all data pipeline operationsDatapipelines.viewer: Can view data pipelines and jobsDatapipelines.invoker: Can invoke a data pipeline job run (this role can be enabled using the API)
The service account used by Cloud Scheduler needs to have the
roles/iam.serviceAccountUserrole, whether the service account is user-specified or the default Compute Engine service account. For more information, see Data pipeline roles.You need to be able to act as the service account used by Cloud Scheduler and Dataflow by being granted the
roles/iam.serviceAccountUserrole on that account. If you don't select a service account for Cloud Scheduler and Dataflow, the default Compute Engine service account is used.
Create a data pipeline
You can create a Dataflow data pipeline in two ways:
The data pipelines setup page: When you first access the Dataflow pipelines feature in the Google Cloud console, a setup page opens. Enable the listed APIs to create data pipelines.
Import a job
You can import a Dataflow batch or streaming job that is based on a classic or flex template and make it a data pipeline.
In the Google Cloud console, go to the Dataflow Jobs page.
Select a completed job, then on the Job Details page, select +Import as a pipeline.
On the Create pipeline from template page, the parameters are populated with the options of the imported job.
For a batch job, in the Schedule your pipeline section, provide a recurrence schedule. Providing an email account address for the Cloud Scheduler, which is used to schedule batch runs, is optional. If it's not specified, the default Compute Engine service account is used.
Create a data pipeline
In the Google Cloud console, go to the Dataflow Data pipelines page.
Select +Create data pipeline.
On the Create pipeline from template page, provide a pipeline name, and fill in the other template selection and parameter fields.
For a batch job, in the Schedule your pipeline section, provide a recurrence schedule. Providing an email account address for the Cloud Scheduler, which is used to schedule batch runs, is optional. If a value is not specified, the default Compute Engine service account is used.
Create a batch data pipeline
To create this sample batch data pipeline, you must have access to the following resources in your project:
- A Cloud Storage bucket to store input and output files
- A BigQuery dataset to create a table.
This example pipeline uses the Cloud Storage Text to BigQuery batch pipeline template. This template reads files in CSV format from Cloud Storage, runs a transform, then inserts values into a BigQuery table with three columns.
Create the following files on your local drive:
A
bq_three_column_table.jsonfile that contains the following schema of the destination BigQuery table.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }A
split_csv_3cols.jsJavaScript file, which implements a simple transformation on the input data before insertion into BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }A
file01.csvCSV file with several records that are inserted into the BigQuery table.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Use the
gcloud storage cpcommand to copy the files to folders in a Cloud Storage bucket in your project, as follows:Copy
bq_three_column_table.jsonandsplit_csv_3cols.jstogs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Copy
file01.csvtogs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
In the Google Cloud console, go to the Cloud Storage Buckets page.
To create a
tmpfolder in your Cloud Storage bucket, select your folder name to open the Bucket details page, then click Create folder.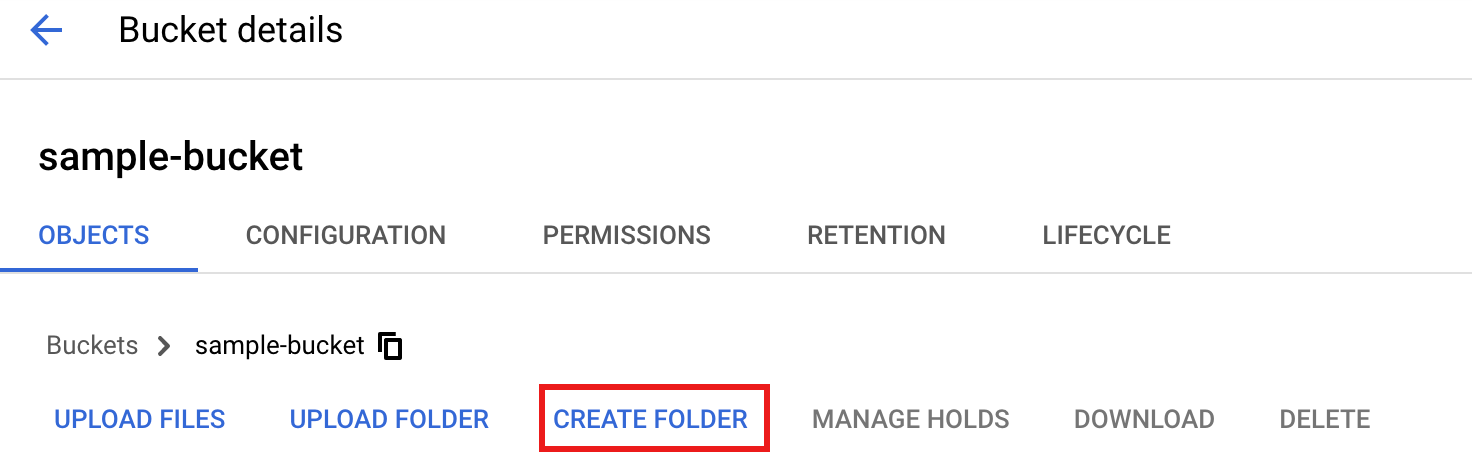
In the Google Cloud console, go to the Dataflow Data pipelines page.
Select Create data pipeline. Enter or select the following items on the Create pipeline from template page:
- For Pipeline name, enter
text_to_bq_batch_data_pipeline. - For Regional endpoint, select a Compute Engine region. The source and destination regions must match. Therefore, your Cloud Storage bucket and BigQuery table must be in the same region.
For Dataflow template, in Process Data in Bulk (batch), select Text Files on Cloud Storage to BigQuery.
For Schedule your pipeline, select a schedule, such as Hourly at minute 25, in your timezone. You can edit the schedule after you submit the pipeline. Providing an email account address for the Cloud Scheduler, which is used to schedule batch runs, is optional. If it's not specified, the default Compute Engine service account is used.
In Required parameters, enter the following:
- For JavaScript UDF path in Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- For JSON path:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- For JavaScript UDF name:
transform - For BigQuery output table:
PROJECT_ID:DATASET_ID.three_column_table
- For Cloud Storage input path:
BUCKET_ID/inputs/file01.csv
- For Temporary BigQuery directory:
BUCKET_ID/tmp
- For Temporary location:
BUCKET_ID/tmp
- For JavaScript UDF path in Cloud Storage:
Click Create pipeline.
- For Pipeline name, enter
Confirm pipeline and template information and view current and previous history from the Pipeline details page.
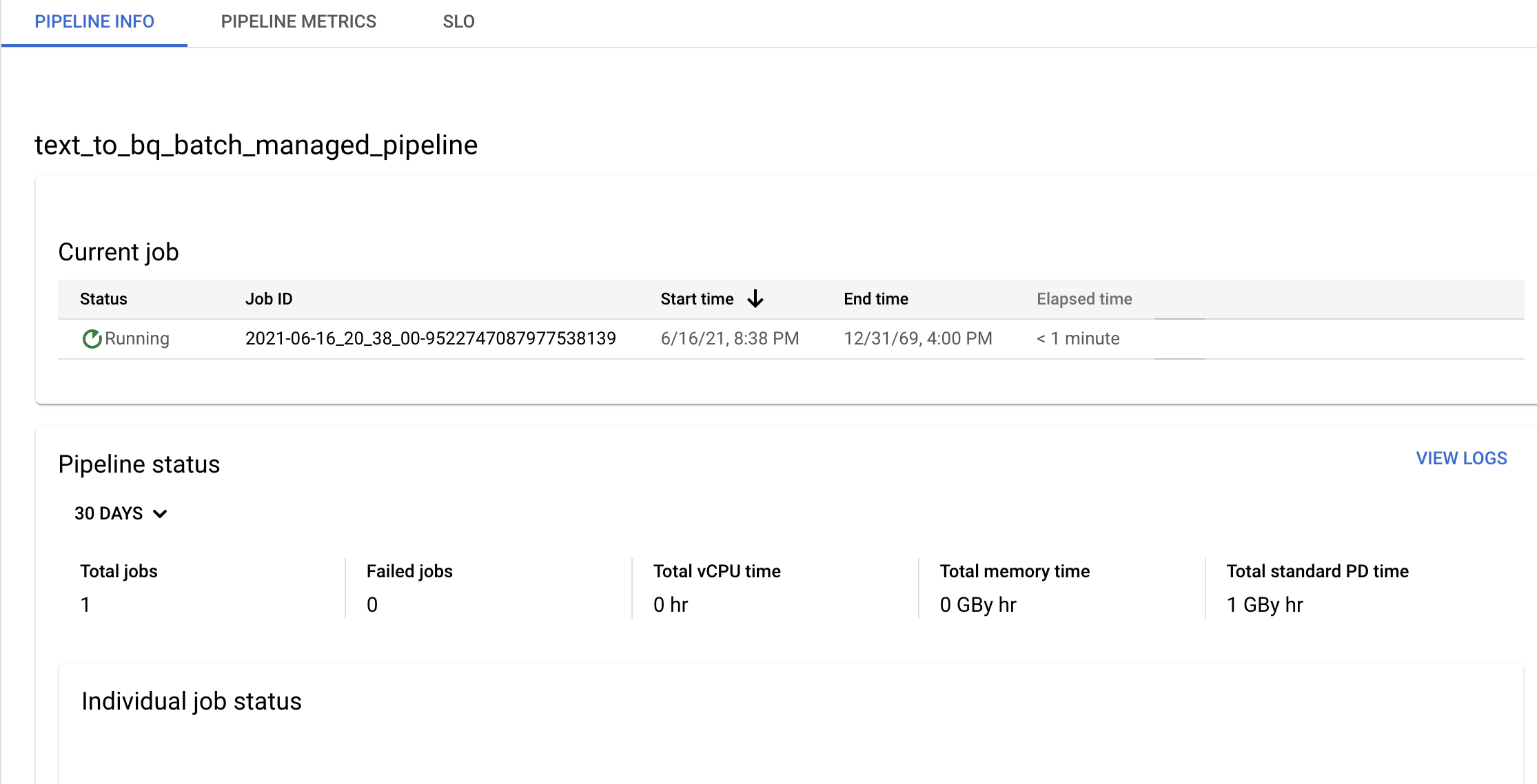
You can edit the data pipeline schedule from the Pipeline info panel on the Pipeline details page.
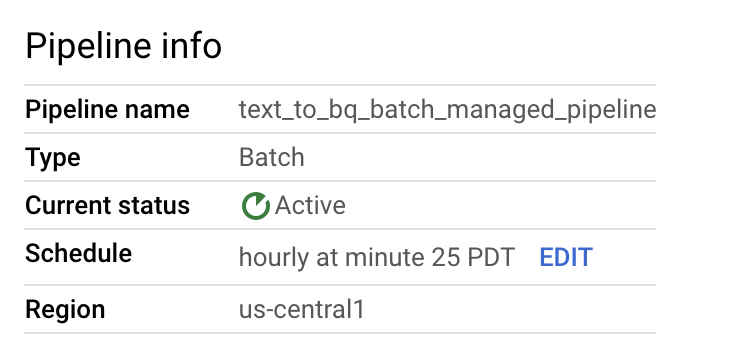
You can also run a batch pipeline on demand using the Run button in the Dataflow Pipelines console.
Create a sample streaming data pipeline
You can create a sample streaming data pipeline by following the sample batch pipeline instructions, with the following differences:
- For Pipeline schedule, don't specify a schedule for a streaming data pipeline. The Dataflow streaming job is started immediately.
- For Dataflow template, in Process Data Continuously (stream), select Text Files on Cloud Storage to BigQuery.
- For Worker machine type, the pipeline processes the initial set of
files matching the
gs://BUCKET_ID/inputs/file01.csvpattern and any additional files matching this pattern that you upload to theinputs/folder. If the size of CSV files exceeds several GB, to avoid possible out-of-memory errors, select a machine type with higher memory than the defaultn1-standard-4machine type, such asn1-highmem-8.
Troubleshooting
This section shows you how to resolve issues with Dataflow data pipelines.
Data pipeline job fails to launch
When you use data pipelines to create a recurring job schedule, your
Dataflow job might not launch, and a 503 status error appears in
the Cloud Scheduler log files.
This issue occurs when Dataflow is temporarily unable to run the job.
To work around this issue, configure Cloud Scheduler to retry the job. Because the issue is temporary, when the job is retried, it might succeed. For more information about setting retry values in Cloud Scheduler, see Create a job.
Investigate pipeline objectives violations
The following sections describe how to investigate pipelines that don't meet performance objectives.
Recurring batch pipelines
For an initial analysis of the health of your pipeline, on the Pipeline info page in the Google Cloud console, use the Individual job status and Thread time per step graphs. These graphs are located in the pipeline status panel.
Example investigation:
You have a recurring batch pipeline that runs every hour at 3 minutes past the hour. Each job normally runs for approximately 9 minutes. You have an objective for all jobs to complete in less than 10 minutes.
The job status graph shows that a job ran for more than 10 minutes.
In the Update/Execution history table, find the job that ran during the hour of interest. Click through to the Dataflow job details page. On that page, find the longer running stage, and then look in the logs for possible errors to determine the cause of the delay.
Streaming pipelines
For an initial analysis of the health of your pipeline, on the Pipeline Details page, in the Pipeline info tab, use the data freshness graph. This graph is located in the pipeline status panel.
Example investigation:
You have a streaming pipeline that normally produces an output with a data freshness of 20 seconds.
You set an objective of having a 30-second data freshness guarantee. When you review the data freshness graph, you notice that between 9 and 10 AM, data freshness jumped to almost 40 seconds.
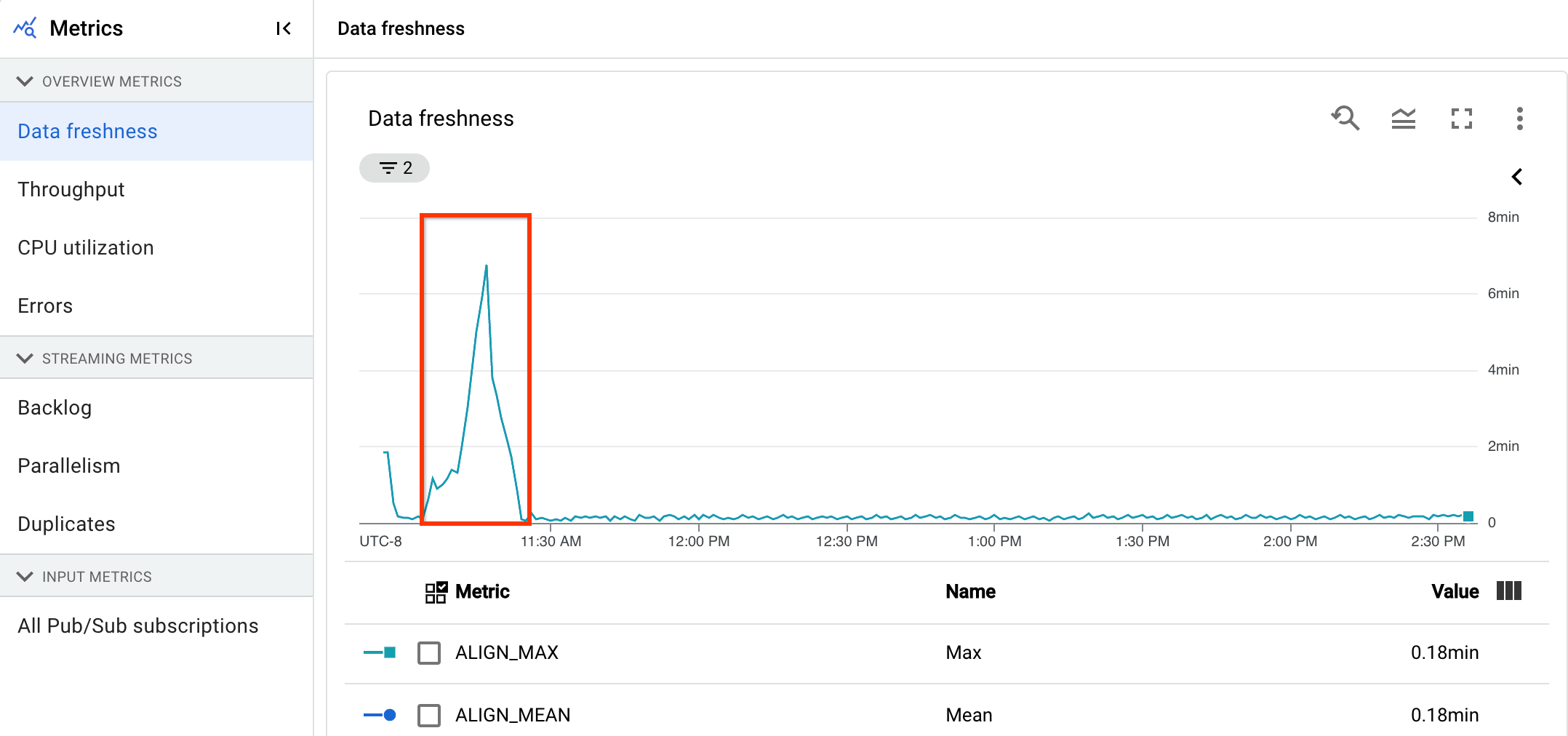
Switch to the Pipeline metrics tab, then view the CPU Utilization and Memory Utilization graphs for further analysis.
Error: Pipeline ID already exists within the project
If you try to create a new pipeline with a name that already exists in your
project, you receive this error message: Pipeline Id already exist within the
project. To avoid this issue, always choose unique names for your pipelines.