Schritt 1: Arbeitslasten einrichten
Auf dieser Seite erfahren Sie, wie Sie den ersten Schritt zum Einrichten Ihrer Datenbasis ausführen, dem Kern von Cortex Framework. Die Datenbasis basiert auf dem BigQuery-Speicher und organisiert Ihre eingehenden Daten aus verschiedenen Quellen. Diese organisierten Daten vereinfachen die Analyse und ihre Anwendung in der KI-Entwicklung.
Datenintegration einrichten
Definieren Sie zuerst einige wichtige Parameter, die als Blaupause für die effiziente Organisation und Nutzung Ihrer Daten im Cortex Framework dienen. Diese Parameter können je nach spezifischer Arbeitslast, ausgewähltem Datenfluss und Integrationsmechanismus variieren. Das folgende Diagramm bietet einen Überblick über die Datenintegration in der Data Foundation des Cortex Framework:

Definieren Sie die folgenden Parameter vor der Bereitstellung, um Daten im Cortex Framework effizient und effektiv zu nutzen.
Projekte
- Quellprojekt:Das Projekt, in dem sich Ihre Rohdaten befinden. Sie benötigen mindestens ein Google Cloud Projekt, um Daten zu speichern und den Bereitstellungsprozess auszuführen.
- Zielprojekt (optional): Projekt, in dem die verarbeiteten Datenmodelle der Cortex Framework Data Foundation gespeichert werden. Das kann dasselbe wie das Quellprojekt oder ein anderes Projekt sein, je nach Ihren Anforderungen.
Wenn Sie für jede Arbeitslast separate Gruppen von Projekten und Datasets haben möchten (z. B. eine Gruppe von Quell- und Zielprojekten für SAP und eine andere Gruppe von Ziel- und Quellprojekten für Salesforce), führen Sie für jede Arbeitslast separate Bereitstellungen aus. Weitere Informationen finden Sie im Abschnitt „Optionale Schritte“ unter Verschiedene Projekte verwenden, um den Zugriff zu trennen.
Datenmodell
- Modelle bereitstellen:Wählen Sie aus, ob Sie Modelle für alle Arbeitslasten oder nur für eine Gruppe von Modellen (z. B. SAP, Salesforce und Meta) bereitstellen müssen. Weitere Informationen finden Sie unter Verfügbare Datenquellen und Arbeitslasten.
BigQuery-Datasets
- Quelldataset (Rohdaten): BigQuery-Dataset, in das die Quelldaten repliziert werden oder in dem die Testdaten erstellt werden. Es wird empfohlen, für jede Datenquelle ein separates Dataset zu verwenden. Beispielsweise ein Rohdatensatz für SAP und ein Rohdatensatz für Google Ads. Dieses Dataset gehört zum Quellprojekt.
- CDC-Dataset:BigQuery-Dataset, in dem die CDC-verarbeiteten Daten mit den neuesten verfügbaren Datensätzen gespeichert werden. Bei einigen Arbeitslasten ist die Zuordnung von Feldnamen möglich. Es wird empfohlen, für jede Quelle ein separates CDC-Dataset zu verwenden. Sie können beispielsweise ein CDC-Dataset für SAP und ein CDC-Dataset für Salesforce erstellen. Dieses Dataset gehört zum Quellprojekt.
- Ziel-Dataset für Berichte:BigQuery-Dataset, in dem die vordefinierten Datenmodelle von Data Foundation bereitgestellt werden. Wir empfehlen, für jede Quelle ein separates Berichts-Dataset zu verwenden. Sie können beispielsweise ein Berichts-Dataset für SAP und ein Berichts-Dataset für Salesforce erstellen. Dieses Dataset wird bei der Bereitstellung automatisch erstellt, wenn es nicht vorhanden ist. Dieses Dataset gehört zum Zielprojekt.
- Vorverarbeitung des K9-Datasets:BigQuery-Dataset, in dem arbeitslastübergreifende, wiederverwendbare DAG-Komponenten wie
time-Dimensionen bereitgestellt werden können. Arbeitslasten sind von diesem Dataset abhängig, sofern sie nicht geändert werden. Dieses Dataset wird bei der Bereitstellung automatisch erstellt, wenn es nicht vorhanden ist. Dieses Dataset gehört zum Quellprojekt. - K9-Dataset für die Nachbearbeitung:BigQuery-Dataset, in dem workloadübergreifende Berichte und zusätzliche DAGs für externe Quellen (z. B. Google Trends-Aufnahme) bereitgestellt werden können. Dieses Dataset wird bei der Bereitstellung automatisch erstellt, wenn es nicht vorhanden ist. Dieses Dataset gehört zum Zielprojekt.
Optional: Beispieldaten generieren
Cortex Framework kann Beispieldaten und ‑tabellen für Sie generieren, wenn Sie keinen Zugriff auf Ihre eigenen Daten oder Replikationstools zum Einrichten von Daten haben oder wenn Sie nur sehen möchten, wie Cortex Framework funktioniert. Sie müssen die CDC- und Rohdatensets jedoch weiterhin vorab erstellen und identifizieren.
Erstellen Sie BigQuery-Datasets für Rohdaten und CDC pro Datenquelle. Folgen Sie dazu der Anleitung unten.
Console
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Wählen Sie im Bereich Explorer das Projekt aus, in dem Sie das Dataset erstellen möchten.
Maximieren Sie die Option Aktionen und klicken Sie auf Dataset erstellen.
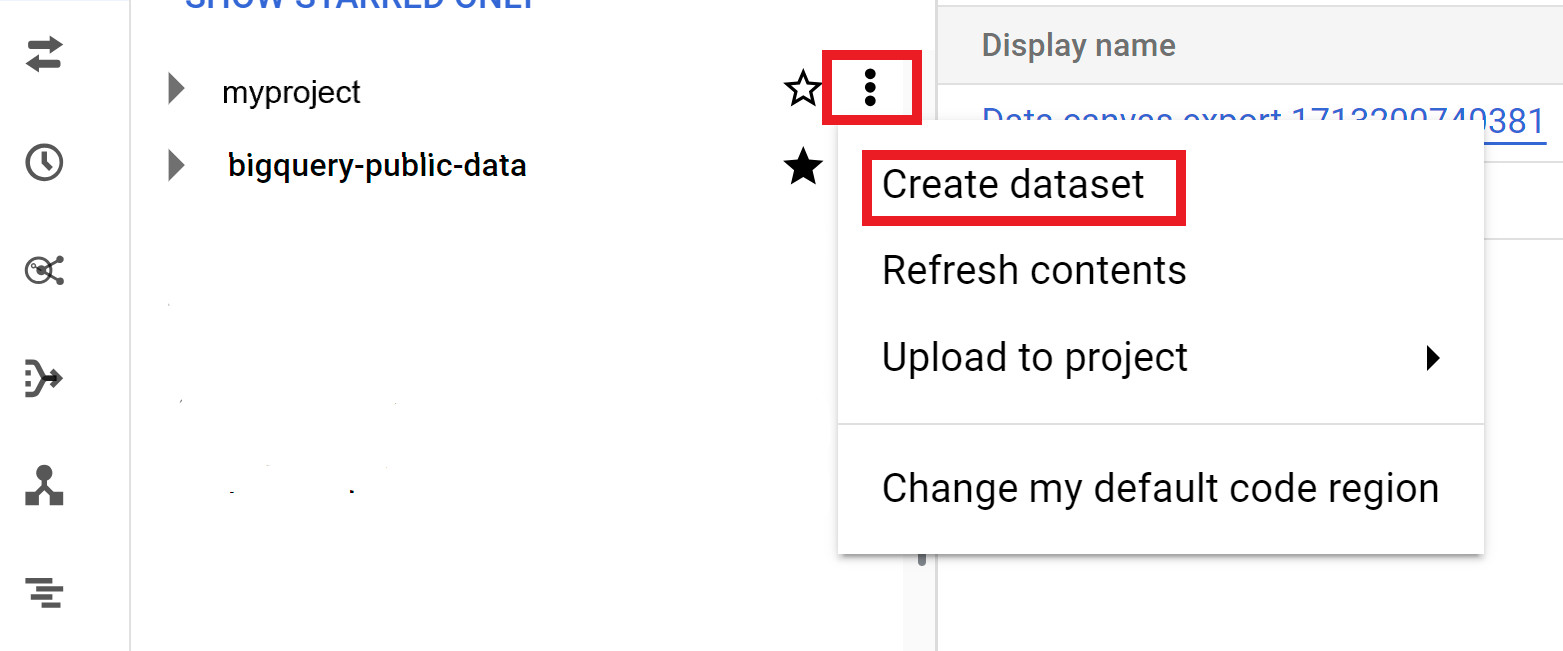
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
- Geben Sie für die Dataset-ID einen eindeutigen Dataset-Namen ein.
Wählen Sie unter Standorttyp einen geografischen Standort für das Dataset aus. Nach der Erstellung des Datasets kann der Standort nicht mehr geändert werden.
Optional: Weitere Informationen zum Anpassen Ihres Datasets finden Sie unter Datasets erstellen: Console.
Klicken Sie auf Dataset erstellen.
BigQuery
Erstellen Sie ein neues Dataset für Rohdaten, indem Sie den folgenden Befehl kopieren:
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAWErsetzen Sie Folgendes:
LOCATIONmit dem Speicherort des Datasets.SOURCE_PROJECTdurch Ihre Quellprojekt-ID.DATASET_RAWdurch den Namen des Datasets für Rohdaten. Beispiel:CORTEX_SFDC_RAW.
Erstellen Sie ein neues Dataset für CDC-Daten, indem Sie den folgenden Befehl kopieren:
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDCErsetzen Sie Folgendes:
LOCATIONmit dem Speicherort des Datasets.SOURCE_PROJECTdurch Ihre Quellprojekt-ID.DATASET_CDCdurch den Namen des Datasets für CDC-Daten. Beispiel:CORTEX_SFDC_CDC.
Prüfen Sie mit dem folgenden Befehl, ob die Datasets erstellt wurden:
bq lsOptional: Weitere Informationen zum Erstellen von Datasets finden Sie unter Datasets erstellen.
Nächste Schritte
Fahren Sie nach Abschluss dieses Schritts mit den folgenden Bereitstellungsschritten fort:
- Arbeitslasten einrichten (diese Seite)
- Repository klonen
- Integrationsmechanismus festlegen:
- Komponenten einrichten
- Bereitstellung konfigurieren
- Bereitstellung ausführen