Cortex for Meridian
This page details the process of data preparation and cloud automation for Google Meridian. Cortex Framework for Meridian streamlines the open-source marketing mix modeling (MMM) with cross-media and sales data. Cortex Framework simplifies this process by providing pre-configured data models and automating Meridian open source model execution using Google Cloud services like Colab Enterprise and Workflows.
One of the key value propositions of Google Cloud Cortex Framework is to provide a data and Artificial Intelligence (AI) foundation for next generation enterprise intelligence that enables analytics spanning across key areas such as sales, marketing, order fulfillment, and inventory management.
Cortex Framework for marketing provides cross media platform key performance indicators (KPIs) and metrics. These metrics are a significant part of the pre-modeling data preparation step for running Google's latest open source MMM called Meridian. Advertisers, agencies, and partners can accelerate the pre-modeling data preparation process by leveraging Google Cloud Cortex Framework Data Foundation.
Cortex for Meridian simplifies the pre-modeling process by efficiently gathering and transforming data from core Cortex Framework data sources, including:
For more information, see Meridian documentation.
Configuration file
During notebook execution, the system retrieves configuration parameters
from the cortex_meridian_config.json file located in the configuration
folder within Cloud Storage.
The following section shares different configuration YAML files examples for Meridian execution:
Sales
Configuration YAML file example for sales as KPIs:
{
"cortex_bq_project_id": "PROJECT_ID",
"cortex_meridian_marketing_data_set_id": "K9_REPORTING",
"cortex_meridian_marketing_view_name": "CrossMediaSalesInsightsWeeklyAgg",
"column_mappings": {
"controls": [],
"geo": "geo",
"kpi": "number_of_sales_orders",
"media": [
"Tiktok_impression",
"Meta_impression",
"YouTube_impression",
"GoogleAds_impression"
],
"media_spend": [
"Tiktok_spend",
"Meta_spend",
"YouTube_spend",
"GoogleAds_spend"
],
"population": "population",
"revenue_per_kpi": "average_revenue_per_sales_order",
"time": "time"
},
"channel_names": [
"TikTok",
"Meta",
"YouTube",
"GoogleAds"
],
"data_processing": {
"kpi_type": "{USE_CASE_SPECIFIC}",
"roi_mu": {USE_CASE_SPECIFIC},
"roi_sigma": {USE_CASE_SPECIFIC},
"sample": {
"prior": {USE_CASE_SPECIFIC},
"posterior": {
"n_chains": {USE_CASE_SPECIFIC},
"n_adapt": {USE_CASE_SPECIFIC},
"n_burnin": {USE_CASE_SPECIFIC},
"n_keep": {USE_CASE_SPECIFIC}
}
}
}
}
Conversions
Configuration YAML file examples for conversions as KPIs:
...
"kpi": "conversions",
"revenue_per_kpi": "",
...
The following table describes the value for each configuration parameter
from the cortex_meridian_config.json file:
| Parameter | Meaning | Default value | Description |
cortex_bq_project_id
|
Project with the Cortex Framework datasets. | {PROJECT_ID}
|
The Google Cloud project ID. |
cortex_meridian_marketing_data_set_id
|
BigQuery dataset with Cortex for Meridian view. | The configuration value of k9.datasets.reporting in the config.json file.
|
The dataset that contains the cortex_meridian_marketing_view_name view.
|
cortex_meridian_marketing_view_name
|
BigQuery view with Cortex for Meridian marketing data and sales. | "CrossMediaSalesInsightsWeeklyAgg"
|
The view that contains weekly aggregated marketing and sales data. |
column_mappings.controls
|
Optional: It can contain the confounders that have a causal effect on both the target KPI and the media metric. | []
|
For Meridian data modelling details on control variables see Control variables. |
column_mappings.geo
|
The columns providing geo information. | "geo"
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.kpi
|
The target KPI for the model. | "number_of_sales_orders" or "conversions" .
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.media
|
Array of columns providing impressions for the channel. | [
"Tiktok_impression",
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.media_spend
|
Columns providing spend for the channel. | [
"Tiktok_spend",
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.population
|
The population for each geo. | "population"
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.revenue_per_kpi
|
The average revenue for a KPI unit. | "average_revenue_per_sales_order" or ""
|
For Meridian data modelling details see Collect and organize your data. |
column_mappings.time
|
The time column - start of the week (Monday). | "time"
|
For Meridian data modelling details see Collect and organize your data. |
channel_names
|
Array of channel names. | [
"TikTok",
|
The names used for the channel - index should match column_mappings.media
and column_mappings.media_spend.
|
data_processing.kpi_type
|
KPI can be either revenue or some other non-revenue KPI. Non-revenue KPI-type can also be used even when revenue is ultimately the KPI. | "{USE_CASE_SPECIFIC}"
|
For Meridian data modelling details for KPI see KPI. |
data_processing.roi_mu
|
Prior distribution on the ROI of each media channel. roi_mu
(used with ROI_M in the notebook).
|
{USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference. |
data_processing.roi_sigma
|
Prior distribution on the ROI of each media channel roi_sigma
(used with ROI_M in the notebook).
|
{USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference. |
data_processing.sample.prior
|
Number of samples drawn from the prior distribution. | {USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Default prior parameterizations and API reference. |
data_processing.sample.posterior.n_chains
|
Number of MCMC chains. | {USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference | .
data_processing.sample.posterior.n_adapt
|
Number of adaptation draws per chain. | {USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference. |
data_processing.sample.posterior.n_burnin
|
Number of burn-in draws per chain. | {USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference. |
data_processing.sample.posterior.n_keep
|
Number of draws per chain to keep for inference. | {USE_CASE_SPECIFIC}
|
For Meridian data processing details make sure you read and understand: Configure the model and API reference. |
Compatibility with Meridian
Cortex Framework Data Foundation and Meridian are released separately. The Cortex Framework release notes provide an overview of its releases and versions. On Meridian's GitHub repository you can see the latest available Meridian versions. Meridian prerequisites and system recommendations are available on Meridian's user guide.
Cortex Framework Data Foundation releases are tested with a specific version of Meridian. You can find the compatible Meridian within the Jupyter notebook, as following image shows:

To update to a newer Meridian version, modify the corresponding line in the notebook. Consider that additional code adjustments may be required in the notebook.
Data Model
This section describes the CrossMediaSalesInsightsWeeklyAgg Data Model using
the Entity Relationship Diagram (ERD).
Cortex for Meridian relies on a single view, CrossMediaSalesInsightsWeeklyAgg,
to operate. The data source for this view is determined by the
k9.Meridian.salesDataSourceType configuration setting, which can be:
BYOD(Bring Your Own Data): Custom data integration.SAP_SALES: Sales data from SAP systems.ORACLE_SALES: Sales data from Oracle EBS systems.
The following section shares the Entity Relationship Diagrams for CrossMediaForMeridian:
BYOD
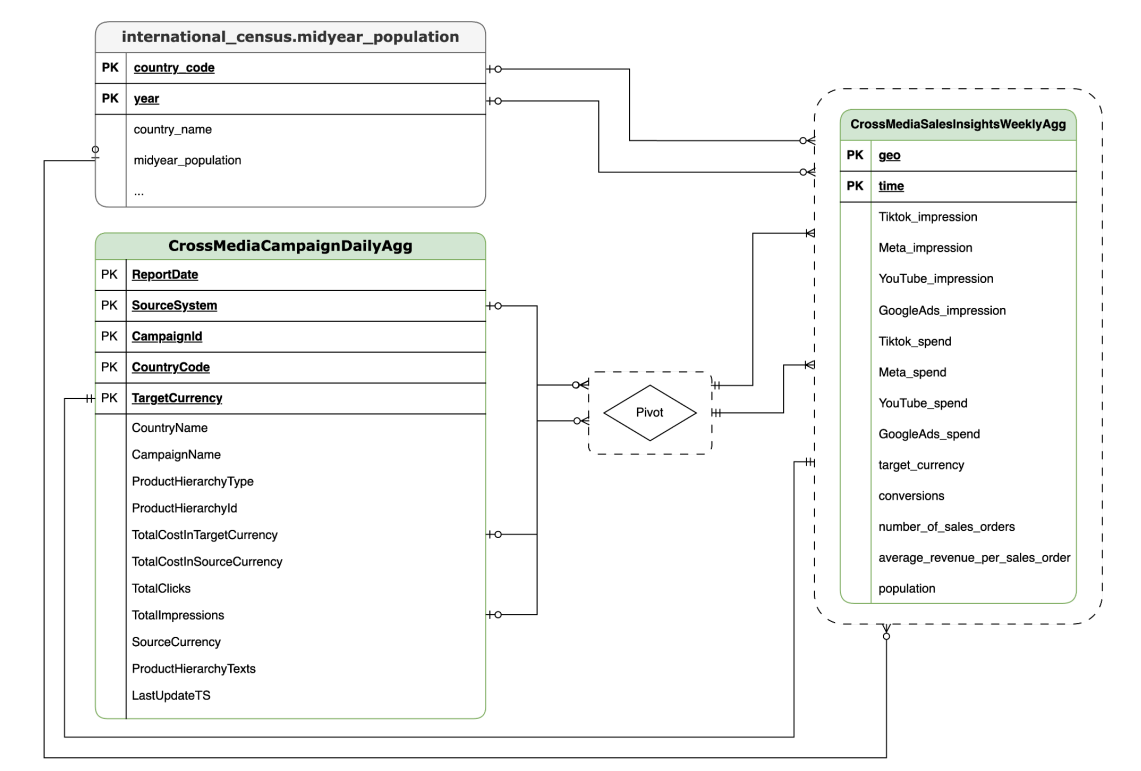
CortexForMeridian without sales data.SAP
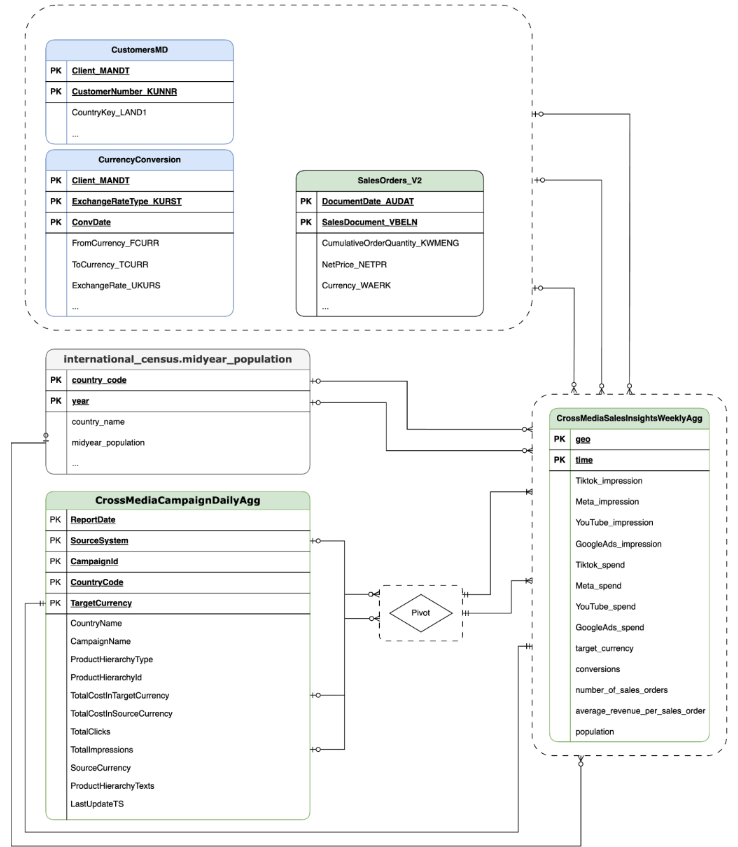
CortexForMeridian with SAP data.OracleEBS
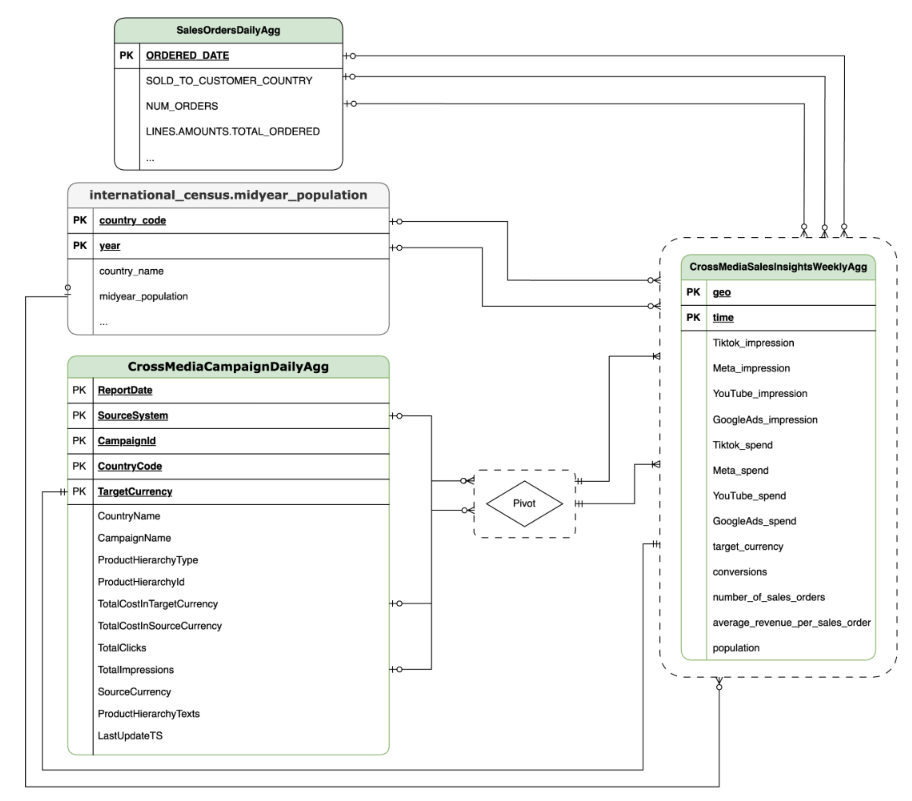
CortexForMeridian with Oracle EBS data.The following table shows the detailed schema for the
CrossMediaSalesInsightsWeeklyAgg view which is part of Cortex for Meridian:
| Column | Type | Description |
| geo | String | The geographical area that is used to aggregate all other values. |
| time | String | The time dimension that is used to aggregate all other values. |
| Tiktok_impression | Integer | The number of times your ads were shown on Tiktok. |
| Meta_impression | Integer | The number of times your ads were shown on Meta. |
| YouTube_impression | Integer | The number of times your ads were shown on YouTube. |
| GoogleAds_impression | Integer | The number of times your ads were shown on GoogleAds. |
| Tiktok_spend | Float | The amount of money that was spent for advertising on Tiktok. |
| Meta_spend | Float | The amount of money that was spent for advertising on Meta. |
| YouTube_spend | Float | The amount of money that was spent for advertising on YouTube. |
| GoogleAds_spend | Float | The amount of money that was spent for advertising on GoogleAds. |
| target_currency | String | Target currency that is used for all the revenue columns. |
| conversions | Integer | Conversions. |
| number_of_sales_orders | Integer | Number of sales orders from Oracle EBS or SAP. |
| average_revenue_per_sales_order | Float | Average revenue per sales order from Oracle EBS or SAP. |
| population | Integer | Population size of the geo. |
Deployment
This page outlines the steps to deploy Cortex Framework for Meridian, enabling the best-in-class MMM within your Google Cloud environment.
For quickstart demo, see Quickstart demo for Meridian.
Architecture
Cortex for Meridian uses Cortex Framework for marketing and Cross Media data combined with sales data. You can bring sales data from either Oracle EBS, SAP, or another source system.
The following diagram describes the key components of Cortex for Meridian:
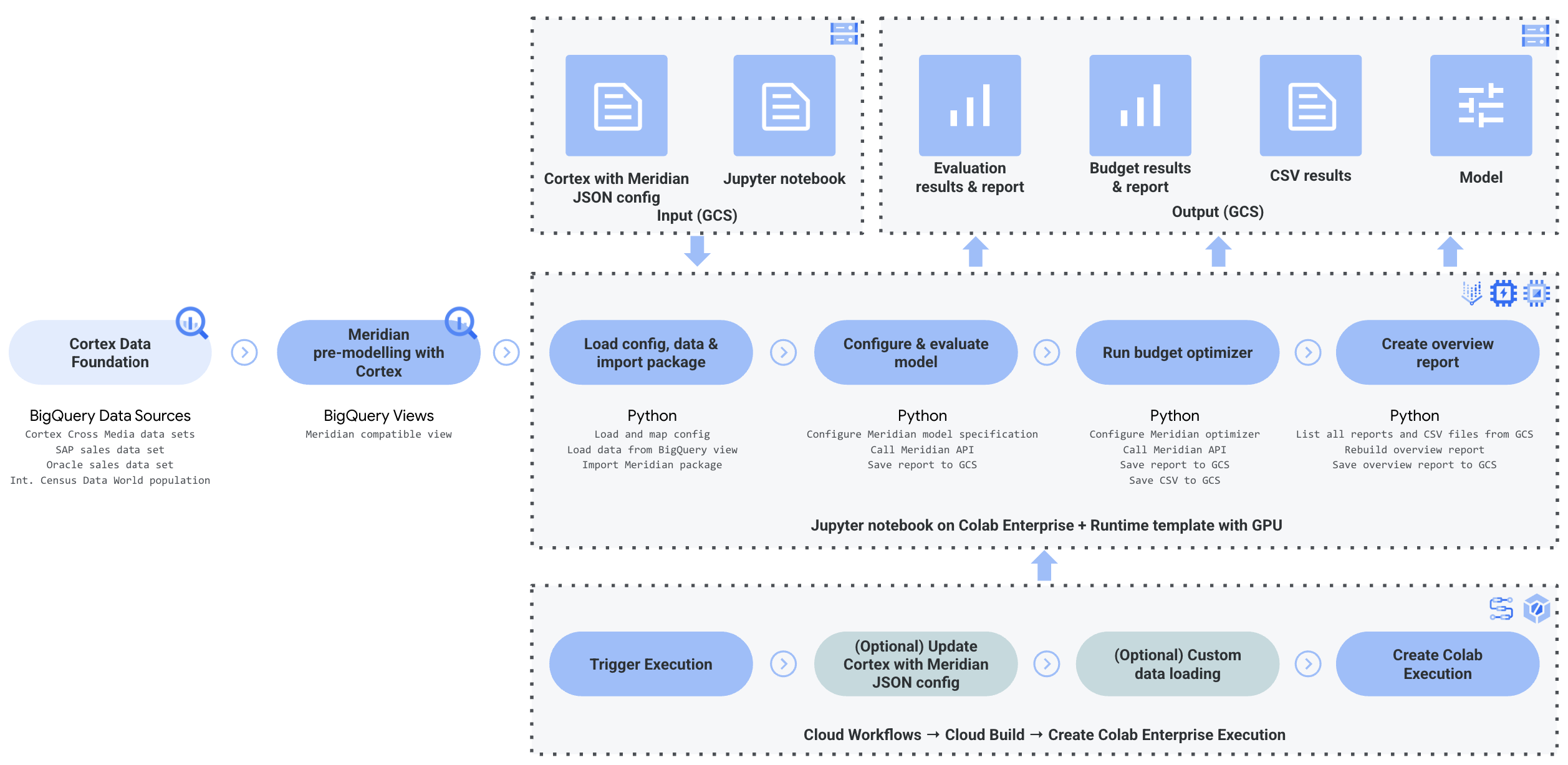
Meridian components and services
During the deployment of Cortex Framework Data Foundation
(see deployment prerequisites),
you can enable Cortex for Meridian by setting deployMeridian to true in
the config.json file. This option initiates an additional Cloud Build
pipeline, which installs the following components and services required for
Meridian:
BigQuery view: A view is created in the K9 reporting dataset called
CrossMediaSalesInsightsWeeklyAgg. This enables querying marketing data and sales data from Cortex Framework. The actual implementation of the view and the underlying sources are dependent on the sales data source you select during deployment.Cloud Storage bucket: The
PROJECT_ID-cortex-meridianbucket contains all the artifacts needed by and produced by Cortex for Meridian in the following folders:configuration: Define the settings and parameters for Cortex for Meridian. It's used by the Colab Enterprise notebook during notebook execution.csv: The raw data output from running Meridian will be saved as CSV files here.models: The generated model from running Meridian will be saved here.notebook-run-logs: Notebook copies for each executions and logs will be saved here.notebooks: Contains the main notebook with code and logic for running Cortex for Meridian. This notebook is intended for further customization to support your specific needs and requirements.reporting: This is the folder where reports from Meridian executions will be saved. Also contains an HTML template for generating an overview report with links to report output from Meridian.
Colab Enterprise: Colab Enterprise is a managed service on Google Cloud that provides a secure and collaborative environment for data science and machine learning workflows using Jupyter notebooks. It offers features like managed infrastructure, enterprise-level security controls, and integration with other Google Cloud services, making it suitable for teams working with sensitive data and requiring robust governance. A managed environment for running the Jupyter notebook.
Cortex for Meridian uses Colab Enterprise to define a runtime template with the required infrastructure to automate Meridian runs.
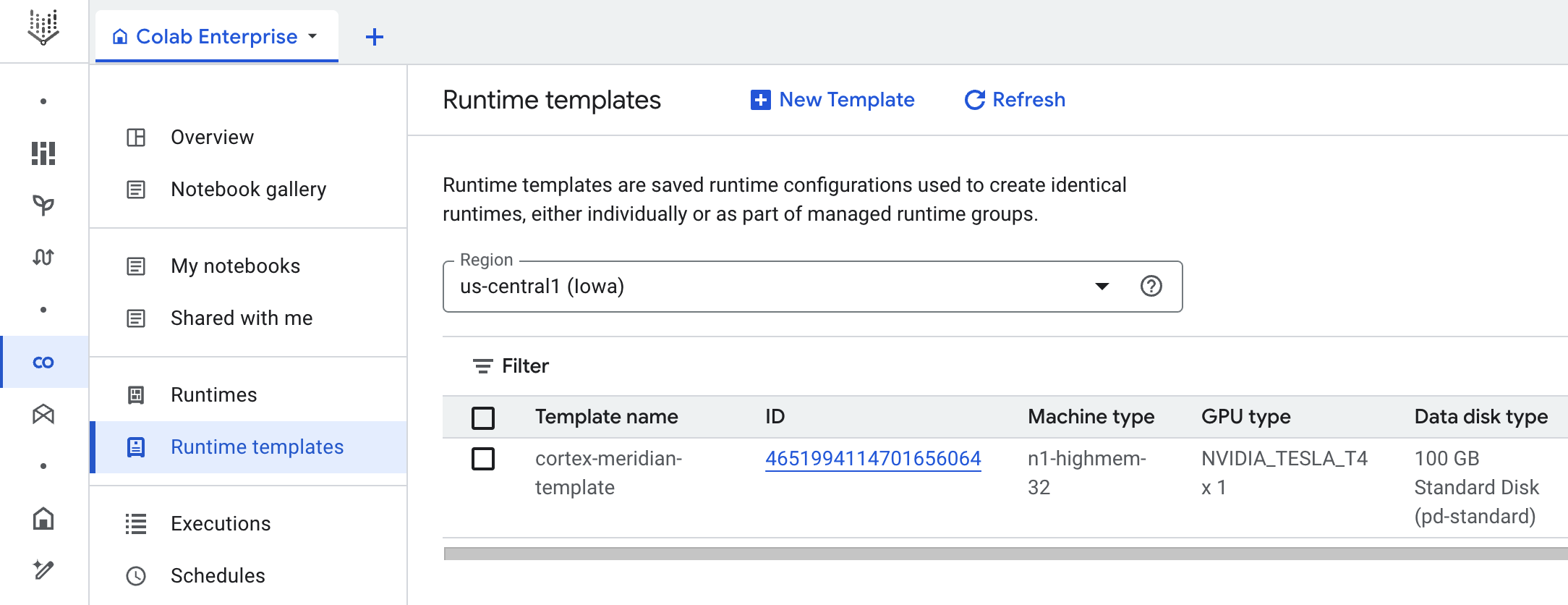
When triggering the end to end pipeline, using workflow, an Execution is created. This will run a copy of the current Jupyter notebook from Cloud Storage with the latest configuration.
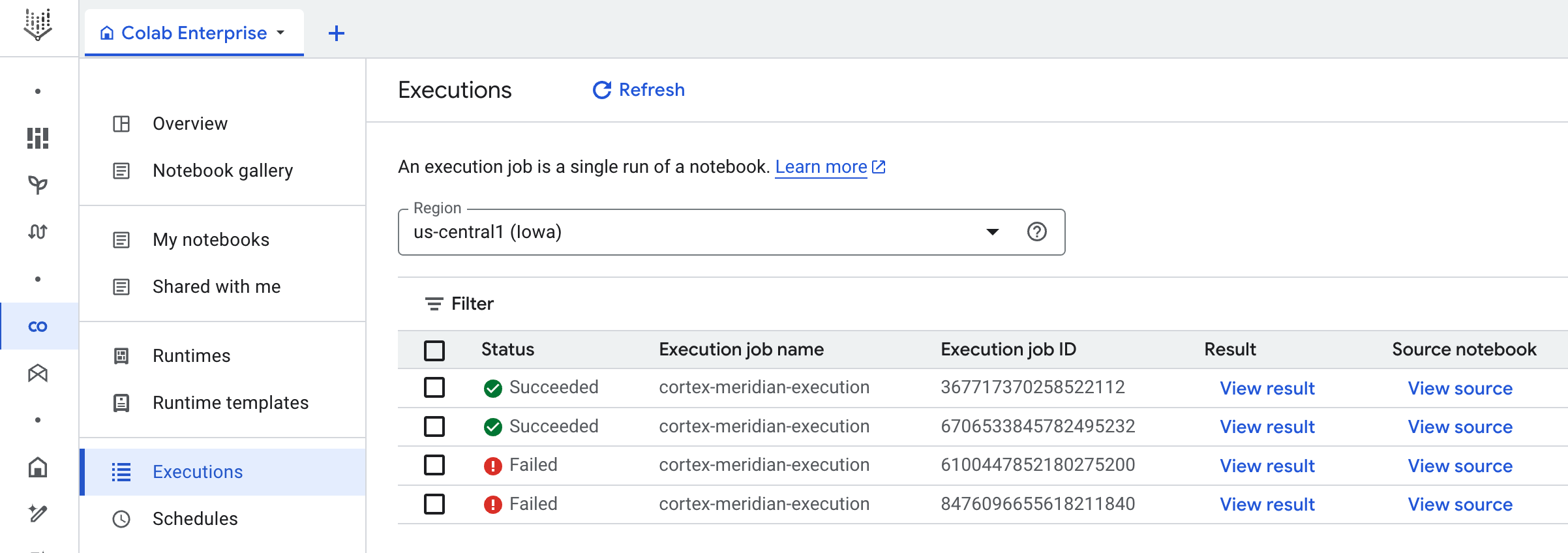
Workflow: A Cloud Workflow called
cortex-meridian-execute-notebookorchestrates the execution of the full Cortex for Meridian pipeline. The workflow will call the Colab Enterprise API that creates a runtime based on the runtime template and executes a notebook run with the current configurations, and finally saves all the results into Cloud Storage.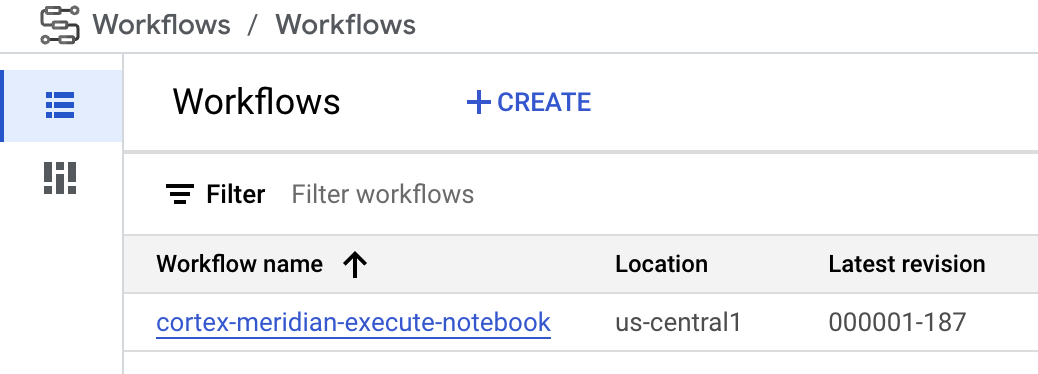
Figure 8. Workflows for Meridian. You have two optional configuration options available for the workflow:
- If you can provide a new Cortex for Meridian JSON config as input to the workflow. If you do so the flow will take a backup of the old config and update the config with your input. See REPLACE for more information.
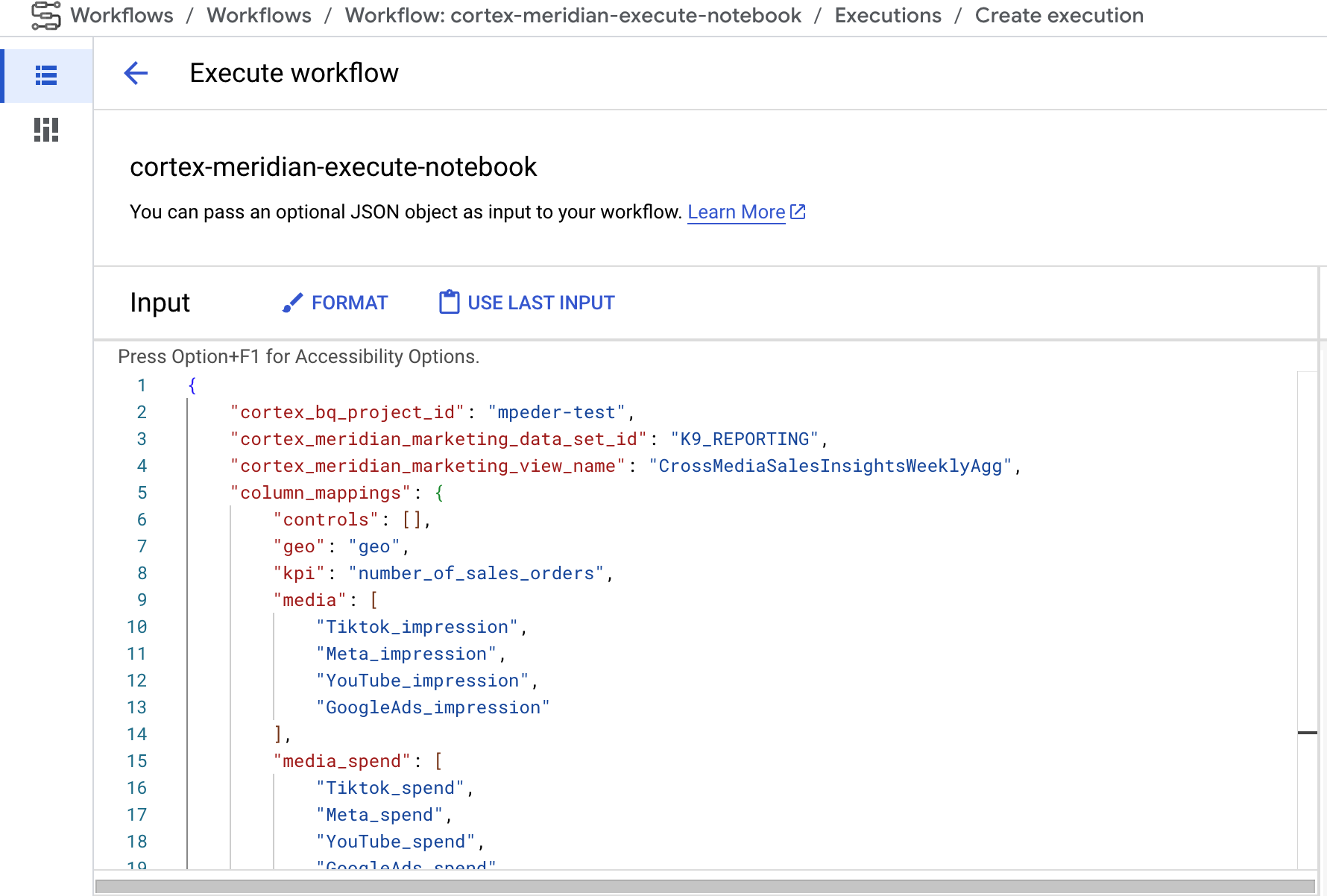
Figure 9. Example of modifying and executing a new input JSON. - The
pre_notebook_executionstep provides an excellent place for you to initiate any additional tasks you need to automate before running the notebook. For example, loading data from sources outside of Google Cloud Cortex Framework.
Service Account: A dedicated Service Account is required to be provided during deployment. This is needed for executing the workflow and the notebook in Colab Enterprise.
Additional deployment parameters for Meridian
The config.json file configures the settings required to run Meridian with
Cortex Framework. This file contains the following parameters for
Cortex for Meridian:
"k9": {
...
"deployMeridian": false,
...
"Meridian":{
"salesDataSourceType": "",
"salesDatasetID":"",
"deploymentType": "",
"defaultNotebookFile":"meridian_cortex_marketing.ipynb",
"defaultConfigFile":"cortex_meridian_config.json",
"gcsBucketNameSuffix": "cortex-meridian",
"workflow": {
"template": "create_notebook_execution_run.yaml",
"name": "cortex-meridian-execute-notebook",
"region": "us-central1"
},
"runnerServiceAccount": "cortex-meridian-colab-runner",
"colabEnterprise": {
"region": "us-central1",
"runtimeTemplateName": "cortex-meridian-template",
"runtimeMachine_type": "n1-highmem-32",
"runtimeAcceleratorCoreCount": 1,
"runtimeAcceleratorType": "NVIDIA_TESLA_T4",
"executionName": "cortex-meridian-execution",
"notebookRunLogsFolder": "notebook-run-logs"
}
}
}
The following table describes the value and description for each Meridian parameter:
| Parameter | Meaning | Default Value | Description |
k9.deployMeridian
|
Deploy Meridian or not. | false
|
Chooses whether or not to deploy Cortex for Meridian as part of a Data Foundation deployment. |
k9.Meridian.salesDataSourceType
|
The source of the sales data. | - | Choose between BYOD, SAP or OracleEBS
|
k9.Meridian.salesDatasetID
|
The id of your sales dataset. | - | The id of your sales dataset. Varies depending on your related Cortex Data Foundation config. |
k9.Meridian.deploymentType
|
Defines whether the deployment is a clean or incremental. | - | Choose between initial and incremental.
|
k9.Meridian.defaultNotebookFile
|
Jupyter notebook file. | meridian_cortex_marketing.ipynb
|
The name of the notebook file located in the notebooks folder on Cloud Storage.
|
k9.Meridian.defaultConfigFile
|
The config file for running the notebook. | cortex_meridian_config.json
|
It contains Cortex for Meridian config used when running the notebook.
It must be located in the configuration folder on
Cloud Storage.
|
k9.Meridian.gcsBucketNameSuffix
|
The suffix of the Cortex for Meridian Cloud Storage bucket. | cortex-meridian
|
The full name of the bucket will be {PROJECT_ID}-cortex-meridian as default. |
k9.Meridian.workflow.template
|
The template for the Workflow. | create_notebook_execution_run.yaml
|
The template for creating the Workflow. The workflow is used for starting a notebook execution. |
k9.Meridian.workflow.name
|
The name of the Workflow. | cortex-meridian-execute-notebook
|
The name show in the Google Cloud portal for the Workflow. |
k9.Meridian.workflow.region
|
The deployment region for the Workflow. | us-central1
|
The deployment region for the Workflow. It typically picks the same as the rest of your deployment. |
k9.Meridian.runnerServiceAccount
|
The name of the Service Account for Cortex for Meridian. | cortex-meridian-colab-runner
|
The name of the Service Account used for running the Workflow and the Colab Enterprise executions. |
k9.Meridian.colabEnterprise.region
|
The deployment region for the Colab Enterprise executions. | us-central1
|
The deployment region for the Colab Enterprise executions. It typically picks the same as the rest of your deployment. |
k9.Meridian.colabEnterprise.runtimeTemplateName
|
Enterprise colab runtime template name. | cortex-meridian-template
|
Enterprise colab runtime template name. |
k9.Meridian.colabEnterprise.runtimeMachine_type
|
Machine type for the runtime of enterprise colab notebook. | n1-highmem-32
|
Machine type for the runtime of enterprise colab notebook. |
k9.Meridian.colabEnterprise.runtimeAcceleratorCoreCount
|
Number of cores. | 1
|
GPU accelerator core count for the runtime of enterprise colab notebook. |
k9.Meridian.colabEnterprise.runtimeAcceleratorType
|
Accelerator type for the runtime of enterprise colab notebook. | NVIDIA_TESLA_T4
|
The type of GPU. |
k9.Meridian.colabEnterprise.executionName
|
Name of the execution for the runtime of enterprise colab notebook. | cortex-meridian-execution
|
The name that will show up in the web interface of Colab Enterprise - Executions. |
k9.Meridian.colabEnterprise.notebookRunLogsFolder
|
Name of the folder for the runtime executions. | notebook-run-logs
|
Executions of Colab notebook will store logs and execution copies of the notebook here. |
Workflow
Workflows serve as the primary
interface for initiating Cortex for Meridian
executions. A default workflow called cortex-meridian-execute-notebook
is deployed as part of Cortex for Meridian.
Notebook execution
To start a new Cortex for Meridian execution follow these steps:
- Go to the
cortex-meridian-execute-notebooknotebook in Workflows. - Click Execute to start a new execution.
- For initial runs, leave the input field empty to use the default
configuration stored in the
cortex_meridian_config.jsonconfiguration file in Cloud Storage. - Click Execute again to proceed.
After a brief delay, the workflow execution status will be displayed:
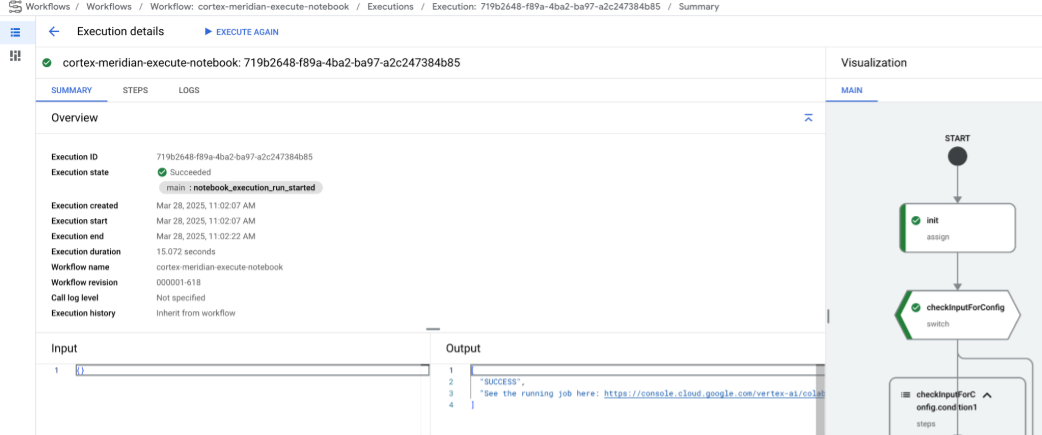
Figure 10. Example of execution details. Track the notebook execution progress in Colab Enterprise.
Workflow steps
The cortex-meridian-execute-notebook workflow contains the following steps:
| Step | Sub-step | Description |
init
|
-
|
Initialize parameters. |
checkInputForConfig
|
-
|
Check if a new config JSON was provided as workflow input. |
logBackupConfigFileName
|
Logs the backup configuration filename. | |
backupConfigFile
|
Performs a backup of the config file on Cloud Storage. | |
logBackupResult
|
Logs the result of the call the Cloud Storage API. | |
updateGCSConfigFile
|
Update the configuration file on Cloud Storage with the new values. | |
pre_notebook_execution
|
-
|
This step is empty by default. It's available for you to customize it. For example, data loading or other relevant steps before running the notebook. For more information, see Workflows overview and Workflows connectors. |
create_notebook_execution_run
|
-
|
Create the Colab Enterprise notebook execution (via a shell script in Cloud Build). |
notebook_execution_run_started
|
-
|
Outputs the completion result. |
Customize Meridian execution workflow
You can customize the Meridian execution by providing your own configuration JSON file in the Workflows input field:
- Input the full JSON of the modified configuration into the input field.
- The workflow will then:
- Replace the existing
cortex_meridian_config.jsonfile in Cloud Storage with the provided JSON. - Create a backup of the original configuration file in the
Cloud Storage/configurationdirectory. - The backup filename will follow the format
cortex_meridian_config_workflow_backup_workflow_execution_id.json, where workflow_execution_id is an uniquely identifier for the current workflow execution (for example,cortex_meridian_config_workflow_backup_3e3a5290-fac0-4d51-be5a-19b55b2545de.json)
- Replace the existing
Jupyter notebook overview
The core functionality of loading input data to run and execute Meridian model
is handled by the Python notebook meridian_cortex_marketing.ipynb,
located in the notebooks folder of your Cloud Storage bucket.
The notebook's execution flow consists of the following steps:
- Install necessary packages (including Meridian) and imports required libraries.
- Load helper functions for interacting with Cloud Storage and BigQuery.
- Retrieves execution configuration from the
configuration/cortex_meridian_config.jsonfile in Cloud Storage. - Load Cortex Framework data from the Cortex Framework Data Foundation view within BigQuery.
- Configure the Meridian model specification and map Cortex Framework Data Foundation data models for marketing and sales to Meridian model input schema.
- Execute Meridian sampling and generates a summary report, saved to
Cloud Storage (
/reporting). - Run the budget optimizer for default scenario and output summary report to
Cloud Storage (
/reporting). - Save model to Cloud Storage (
/models). - Save CSV results to Cloud Storage (
/csv). - Generate an overview report and save it to Cloud Storage (
/reporting).
Import notebook for manual execution and editing
To customize or manually execute the notebook, import it from Cloud Storage:
- Go to Colab Enterprise.
- Click My notebooks.
- Click Import.
- Select Cloud Storage as import source and select the notebook from Cloud Storage.
- Click Import.
The notebook will load and open.
Notebook executions results
To review notebook run results, open a full copy of the notebook with all cell outputs:
- Go to Executions in Colab Enterprise.
- Select the relevant region from the drop-down.
- Next to the notebook run that you want to view results for, click View result.
- Colab Enterprise will open the result of the notebook run in a new tab.
- To view the result, click the new tab.
Runtime template
Google Cloud Colab Enterprise uses runtime templates to define pre-configured execution environments. A predefined runtime template, suitable for running the Meridian notebook, is included with the Cortex for Meridian deployment. This template is automatically used to create runtime environments for notebook executions.
If needed, you can manually create additional runtime templates.