Auf dieser Seite finden Sie einen Überblick über die regionenübergreifende Replikation von AlloyDB for PostgreSQL.
Mit der regionenübergreifenden Replikation von AlloyDB können Sie sekundäre Cluster und Instanzen aus einem primären Cluster erstellen, um die Ressourcen bei einem Ausfall in der primären Region in verschiedenen Regionen verfügbar zu machen. Diese sekundären Cluster und Instanzen fungieren als Kopien Ihrer primären Cluster- und Instanzressourcen.
Die wichtigsten Konzepte auf dieser Seite sind:
Primärer Cluster: Ein Lese-/Schreib-Cluster in einer einzelnen Region.
Sekundärer Cluster: Ein schreibgeschützter Cluster in einer anderen Region als der primäre Cluster, dessen Daten asynchron aus dem primären Cluster repliziert werden. Bei einem Ausfall eines primären AlloyDB-Clusters können Sie einen sekundären Cluster zu einem primären Cluster hochstufen.
Sie können bis zu fünf sekundäre Cluster für einen primären Cluster erstellen. Alle sekundären Cluster replizieren Daten aus einem einzelnen primären Cluster. Wenn Sie einen sekundären Cluster hochstufen, wird er zu einem unabhängigen primären Cluster.
Sekundäre Instanz: Ein schreibgeschützter Leader eines sekundären Clusters. Sie ist für den Empfang eines Replikationsstreams von einem primären Cluster verantwortlich. Der Replikationsstream aktualisiert das Speichervolume in der sekundären Region basierend auf dem Speichervolume in der primären Region. Wenn ein sekundärer Cluster zu einem primären Cluster hochgestuft wird, wird die sekundäre Instanz zur primären Instanz.
Eine sekundäre Instanz kann entweder einfach (zonal) oder hochverfügbar (regional) sein.
Das folgende Diagramm veranschaulicht die regionsübergreifende Replikation:
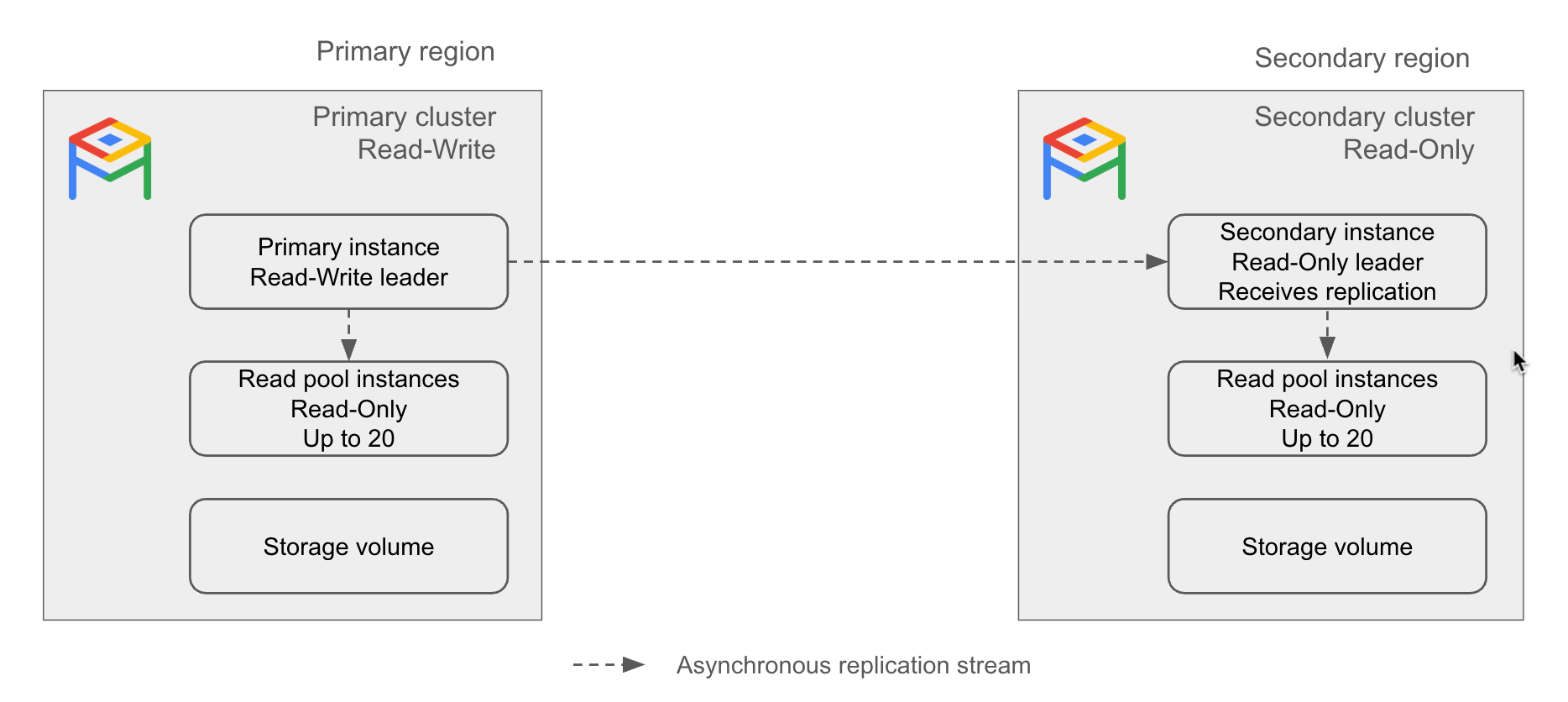
Abbildung 1. Beispiel für die regionsübergreifende Replikationsarchitektur von AlloyDB.
Vorteile
Die regionenübergreifende Replikation in AlloyDB bietet folgende Vorteile:
Notfallwiederherstellung: Wenn die Region des primären Clusters nicht mehr verfügbar ist, können Sie AlloyDB-Ressourcen in einer anderen Region hochstufen, um Anfragen zu bearbeiten.
Weniger Ausfallzeiten: Die Unterstützung von Hochverfügbarkeit (HA) in sekundären Clustern reduziert Ausfallzeiten bei Wartungsereignissen oder ungeplanten Ausfällen.
Geografisch verteilte Daten: Durch die geografische Verteilung der Daten werden die Daten näher an Sie herangebracht und die Leselatenz verringert.
Bessere Leseskalierung:Jedes regionenübergreifende Replikat (oder jeder sekundäre Cluster) kann bis zu 20 Leseknoten unterstützen, sodass Sie Ihre Lesevorgänge weiter skalieren können.
Switchover ohne Datenverlust: Bei regionenübergreifenden Replikationseinrichtungen unterstützt AlloyDB die Umstellung zwischen primärer und sekundärer Instanz ohne Datenverlust.
Regionsübergreifende Replikation nutzen
Die regionsübergreifende Replikation von AlloyDB umfasst die folgenden Aufgaben:
Sekundären Cluster erstellen Ein sekundärer Cluster ist eine kontinuierlich aktualisierte Kopie Ihres primären AlloyDB-Clusters.
Sekundären Cluster ansehen: Nachdem Sie einen sekundären Cluster erstellt haben, können Sie seine Details auf der Seite Cluster in der Google Cloud -Konsole ansehen.
Lesepoolinstanzen hinzufügen Sie können einem sekundären Cluster Lesepoolinstanzen hinzufügen. Wenn Sie die Lesekapazität horizontal skalieren möchten, können Sie Ihrem sekundären Cluster bis zu 20 Leseknoten hinzufügen.
Sekundären Cluster hochstufen: Sie können die Daten aus einem sekundären Cluster lesen, aber nicht in ihn schreiben, bis Sie ihn zu einem voll funktionsfähigen, eigenständigen primären Cluster hochstufen. Wenn Sie einen sekundären Cluster hochstufen, wird auch die sekundäre Instanz des Clusters als primäre Instanz mit Lese- und Schreibfunktionen hochgestuft.
Der primäre Anwendungsfall für das Hochstufen eines sekundären Clusters ist die Notfallwiederherstellung. Wenn in der Region Ihres primären Clusters ein regionaler Ausfall auftritt, können Sie Ihren sekundären Cluster zu einem eigenständigen primären Cluster hochstufen und die Bereitstellung Ihrer Anwendung fortsetzen.
Switchover ohne Datenverlust: Mit Switchover können Sie die Rollen Ihres primären und sekundären Clusters ohne Datenverlust umkehren. Sie können einen Switchover ausführen, um Ihre Einrichtung zur Notfallwiederherstellung zu testen oder Ihre Arbeitslast zu migrieren. Nach Abschluss des Switchover-Vorgangs wird die Richtung der Replikation umgekehrt.
Wenn Sie mehrere sekundäre Cluster haben, wird der sekundäre Cluster, der den Switchover-Befehl empfängt, zu einem primären Cluster. Der vorherige primäre Cluster wird zu einem sekundären Cluster, der vom neuen primären Cluster repliziert wird. Alle anderen sekundären Cluster wechseln zur Replikation vom neuen primären Cluster.
Es gibt zwei gängige Szenarien für die Umstellung auf Ihren sekundären Cluster:
- Übungen zur Notfallwiederherstellung: Sie können Ihre Prozesse zur Notfallwiederherstellung testen, indem Sie Ihre Anwendung ohne Datenverlust in eine andere Region verschieben, um einen regionalen Ausfall zu simulieren.
- Regionale Migration: Sie führen eine geplante Migration der AlloyDB-Ressourcen von ihrer primären Region in eine andere Region aus. Beim Switchover wird der sekundäre Cluster zu einem primären Cluster mit einem RPO (Recovery Point Objective) von 0. So wird sichergestellt, dass bei der Migration keine Daten verloren gehen.
Automatisierte und kontinuierliche Sicherungen konfigurieren: Standardmäßig kopiert AlloyDB automatisch Konfigurationen für automatische und kontinuierliche Sicherungen vom primären Cluster in einen neu erstellten sekundären Cluster. Wenn Sie für Ihren sekundären Cluster andere Sicherungskonfigurationen verwenden möchten, können Sie die Sicherungskonfiguration beim Erstellen eines sekundären Clusters ändern.
Wenn Ihr primärer Cluster die CMEK-Verschlüsselung (Customer-Managed Encryption Key) für Sicherungen verwendet, haben Sie beim Erstellen eines sekundären Clusters folgende Möglichkeiten:
- Geben Sie die CMEK-Verschlüsselungseinstellungen für die Sicherungen des sekundären Clusters an.
- Deaktivieren Sie Sicherungen für den sekundären Cluster.
Weitere Informationen zum Verschlüsseln von Sicherungen mit CMEK finden Sie unter CMEK verwenden.
Sie können die Einstellungen für automatische und kontinuierliche Sicherungen für den sekundären Cluster nach der Erstellung ändern.