Questo documento spiega come il team di assistenza e il team di ingegneria del prodotto collaborano per risolvere un incidente e fornirti aggiornamenti. Google Cloud
Il seguente diagramma mostra le responsabilità dei team di ingegneria del prodotto e assistenza.

Le sezioni seguenti spiegano queste responsabilità.
Rilevamento
Google Cloud utilizza il monitoraggio interno e sintetico per rilevare gli incidenti. Per ulteriori informazioni, consulta il capitolo 6 del libro Site Reliability Engineering.
Risposta iniziale
Quando viene rilevato un incidente, il team di Google Cloud Service Health gestisce le comunicazioni con i clienti. La notifica iniziale di un incidente è spesso scarna, e spesso menziona solo il prodotto in questione. Questo perché diamo la priorità alla notifica rapida rispetto ai dettagli. I dettagli possono essere forniti negli aggiornamenti successivi.
Per fornirti quante più informazioni possibili senza sovraccaricarti con problemi che non ti riguardano, vengono utilizzati diversi canali di comunicazione a seconda dell'ambito e della gravità di un problema:
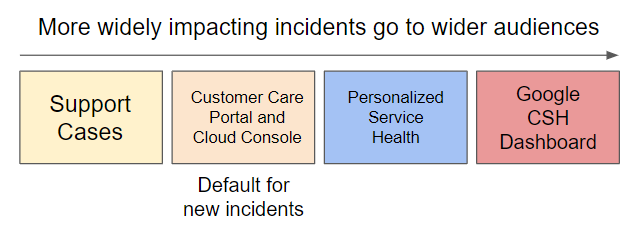
Indaga
I team di ingegneri di prodotto sono responsabili di analizzare la causa principale degli incidenti. La gestione degli incidenti viene spesso eseguita dagli SRE, ma potrebbe essere eseguita da tecnici software o da altri, a seconda della situazione e del prodotto. Per ulteriori informazioni, consulta il capitolo 12 del libro Site Reliability Engineering.
Attenuazione e correzione
Un problema è considerato risolto solo quando sono state apportate modifiche che Google ritiene con certezza che metteranno fine all'impatto in modo definitivo. Ad esempio, la correzione potrebbe comportare il rollback di una modifica che ha attivato un incidente.
Mentre è in corso un incidente, Service Health e il team del prodotto cercano di mitigare il problema. La mitigazione si verifica quando l'impatto o l'ambito di un problema può essere ridotto, ad esempio fornendo temporaneamente risorse aggiuntive a un prodotto in sovraccarico.
Se non è stata trovata alcuna mitigazione, quando possibile, il team Service Health trova e comunica soluzioni alternative. Le soluzioni alternative sono passaggi che puoi intraprendere per soddisfare la necessità di base nonostante l'incidente. Una soluzione alternativa potrebbe essere utilizzare impostazioni diverse per una chiamata API per evitare un percorso di codice problematico.
Invia un follow-up
Mentre un incidente è in corso, il team Service Health fornisce aggiornamenti regolari. In genere gli aggiornamenti forniscono:
Ulteriori informazioni sull'incidente, ad esempio messaggi di errore, zone o regioni interessate, funzionalità interessate o percentuali di impatto.
Progressi verso la mitigazione, comprese eventuali soluzioni alternative.
Tempistiche per la comunicazione, personalizzate in base all'incidente.
Modifiche dello stato, ad esempio quando un incidente viene risolto.
Retrospettiva
Tutti gli incidenti vengono sottoposti a un'analisi retrospettiva interna per comprenderli appieno e identificare i miglioramenti dell'affidabilità che Google può apportare. Questi miglioramenti vengono poi monitorati e implementati. Per ulteriori informazioni, consulta il capitolo 15 del libro Site Reliability Engineering.
Report sull'incidente
Quando gli incidenti hanno un impatto molto ampio e grave, Google fornisce report sugli incidenti che descrivono i sintomi, l'impatto, la causa principale, la correzione e la prevenzione futura degli incidenti. Come per le retrospettive, prestiamo particolare attenzione ai passaggi che intraprendiamo per imparare dal problema e migliorare l'affidabilità. L'obiettivo di Google nella stesura e nella pubblicazione delle retrospettive è quello di essere trasparente e dimostrare il nostro impegno a creare prodotti stabili per i nostri clienti.