This document explains how the Google Cloud Support team and product engineering team work together to resolve an incident and provide you with updates.
The following diagram shows the responsibilities of the product engineering and support teams.

The following sections explain these responsibilities.
Detection
Google Cloud uses internal and synthetic monitoring to detect incidents. For more information, see Chapter 6 of the Site Reliability Engineering book.
Initial response
When an incident is detected, the Google Cloud Service Health team manages customer communications. Initial notification of an incident is often sparse, frequently only mentioning the product in question. This is because we prioritize fast notification over detail. Detail can be provided in subsequent updates.
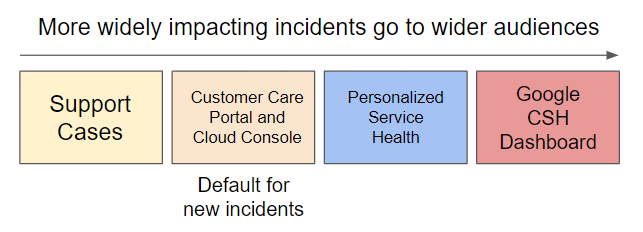
To provide you as much information as possible without overwhelming you with issues that don't affect you, different communication channels are used depending on the scope and severity of an issue:
Investigate
Product engineering teams are responsible for investigating the root cause of incidents. Incident management is often done by Site Reliability Engineers but might be done by software engineers or others, depending on the situation and product. For more information, see Chapter 12 of the Site Reliability Engineering Book.
Mitigation and fix
An issue is considered fixed only when changes have been made that Google is confident will end the impact indefinitely. For example, the fix could be rolling back a change that triggered an incident.
While an incident is in progress, Service Health and the product team attempt to mitigate the issue. Mitigation is when the impact or scope of an issue can be reduced, for example, by temporarily providing additional resources to a product suffering overload.
If no mitigation has been found, when possible, the Service Health team finds and communicates workarounds. Workarounds are steps that you can take to solve the underlying need despite the incident. A workaround might be to use different settings for an API call to avoid a problematic code path.
Follow up
While an incident is ongoing, the Service Health team provides regular updates. Updates typically provide:
More information about the incident, such as error messages, zones or regions affected, which features are affected, or percentages of impact.
Progress towards mitigation, including any workarounds.
Timelines for communication, tailored to the incident.
Changes in status, such as when an incident is fixed.
Retrospective
All incidents undergo an internal retrospective to fully understand the incident and identify reliability improvements that Google can make. These improvements are then tracked and implemented. For more information, see Chapter 15 of the Site Reliability Engineering Book.
Incident report
When incidents have very wide and serious impact, Google provides incident reports that outline the symptoms, impact, root cause, remediation, and future prevention of incidents. As with retrospectives, we pay particular attention to the steps that we take to learn from the issue and improve reliability. Google's goal in writing and releasing retrospectives is to be transparent and demonstrate our commitment to building stable products for our customers.